Η προετοιμασία δεδομένων είναι ένα κρίσιμο βήμα σε οποιαδήποτε ροή εργασίας μηχανικής μάθησης (ML), ωστόσο συχνά περιλαμβάνει κουραστικές και χρονοβόρες εργασίες. Καμβάς Amazon SageMaker τώρα υποστηρίζει ολοκληρωμένες δυνατότητες προετοιμασίας δεδομένων που υποστηρίζονται από Amazon SageMaker Data Wrangler. Με αυτήν την ενσωμάτωση, το SageMaker Canvas παρέχει στους πελάτες έναν από άκρο σε άκρο χώρο εργασίας χωρίς κώδικα για την προετοιμασία δεδομένων, τη δημιουργία και τη χρήση μοντέλων ML και θεμελίων για την επιτάχυνση του χρόνου από τα δεδομένα στις επιχειρηματικές πληροφορίες. Τώρα μπορείτε εύκολα να ανακαλύψετε και να συγκεντρώσετε δεδομένα από περισσότερες από 50 πηγές δεδομένων και να εξερευνήσετε και να προετοιμάσετε δεδομένα χρησιμοποιώντας περισσότερες από 300 ενσωματωμένες αναλύσεις και μετασχηματισμούς στην οπτική διεπαφή του SageMaker Canvas. Θα δείτε επίσης ταχύτερη απόδοση για μετασχηματισμούς και αναλύσεις, καθώς και μια διεπαφή φυσικής γλώσσας για εξερεύνηση και μετατροπή δεδομένων για ML.
Σε αυτήν την ανάρτηση, σας καθοδηγούμε στη διαδικασία προετοιμασίας δεδομένων για την κατασκευή μοντέλων από άκρο σε άκρο στον καμβά SageMaker.
Επισκόπηση λύσεων
Για την περίπτωση χρήσης μας, αναλαμβάνουμε το ρόλο του επαγγελματία δεδομένων σε μια εταιρεία χρηματοοικονομικών υπηρεσιών. Χρησιμοποιούμε δύο δείγματα συνόλων δεδομένων για να δημιουργήσουμε ένα μοντέλο ML που προβλέπει εάν ένα δάνειο θα αποπληρωθεί πλήρως από τον δανειολήπτη, κάτι που είναι κρίσιμο για τη διαχείριση του πιστωτικού κινδύνου. Το περιβάλλον χωρίς κώδικα του SageMaker Canvas μας επιτρέπει να προετοιμάσουμε γρήγορα τα δεδομένα, τις δυνατότητες μηχανικής, να εκπαιδεύσουμε ένα μοντέλο ML και να αναπτύξουμε το μοντέλο σε μια ροή εργασίας από άκρο σε άκρο, χωρίς την ανάγκη κωδικοποίησης.
Προϋποθέσεις
Για να ακολουθήσετε αυτήν την περιγραφή, βεβαιωθείτε ότι έχετε εφαρμόσει τις προϋποθέσεις όπως περιγράφεται λεπτομερώς στο
- Εκκινήστε το Amazon SageMaker Canvas. Εάν είστε ήδη χρήστης του SageMaker Canvas, βεβαιωθείτε ότι το κάνετε log out και συνδεθείτε ξανά για να μπορέσετε να χρησιμοποιήσετε αυτήν τη νέα δυνατότητα.
- Για να εισαγάγετε δεδομένα από το Snowflake, ακολουθήστε τα βήματα από Ρυθμίστε το OAuth για Snowflake.
Προετοιμάστε διαδραστικά δεδομένα
Με την ολοκλήρωση της εγκατάστασης, μπορούμε τώρα να δημιουργήσουμε μια ροή δεδομένων για να ενεργοποιήσουμε τη διαδραστική προετοιμασία δεδομένων. Η ροή δεδομένων παρέχει ενσωματωμένους μετασχηματισμούς και απεικονίσεις σε πραγματικό χρόνο για να μπερδέψει τα δεδομένα. Ολοκληρώστε τα παρακάτω βήματα:
- Δημιουργήστε μια νέα ροή δεδομένων χρησιμοποιώντας μία από τις ακόλουθες μεθόδους:
- Επιλέξτε Data Wrangler, Ροές δεδομένων, κατόπιν επιλέξτε Δημιουργία.
- Επιλέξτε το σύνολο δεδομένων SageMaker Canvas και επιλέξτε Δημιουργήστε μια ροή δεδομένων.
- Επιλέξτε Εισαγωγή δεδομένων και επιλέξτε Πινακοειδής από την αναπτυσσόμενη λίστα.

- Μπορείτε να εισάγετε δεδομένα απευθείας μέσω περισσότερων από 50 υποδοχών δεδομένων, όπως π.χ Απλή υπηρεσία αποθήκευσης Amazon (Amazon S3), Αμαζόν Αθηνά, Amazon RedShift, Snowflake και Salesforce. Σε αυτήν την περιγραφή, θα καλύψουμε την εισαγωγή των δεδομένων σας απευθείας από το Snowflake.
Εναλλακτικά, μπορείτε να ανεβάσετε το ίδιο σύνολο δεδομένων από τον τοπικό σας υπολογιστή. Μπορείτε να κατεβάσετε το σύνολο δεδομένων loans-part-1.csv και loans-part-2.csv.
- Από τη σελίδα Εισαγωγή δεδομένων, επιλέξτε Snowflake από τη λίστα και επιλέξτε Προσθήκη σύνδεσης.
- Εισαγάγετε ένα όνομα για τη σύνδεση, επιλέξτε OAuth επιλογή από την αναπτυσσόμενη λίστα της μεθόδου ελέγχου ταυτότητας. Εισαγάγετε το αναγνωριστικό του λογαριασμού σας okta και επιλέξτε Προσθήκη σύνδεσης.

- Θα ανακατευθυνθείτε στην οθόνη σύνδεσης του Okta για να εισαγάγετε τα διαπιστευτήρια Okta για έλεγχο ταυτότητας. Σε επιτυχή έλεγχο ταυτότητας, θα ανακατευθυνθείτε στη σελίδα ροής δεδομένων.

- Περιηγηθείτε για να εντοπίσετε το σύνολο δεδομένων δανείου από τη βάση δεδομένων Snowflake
Επιλέξτε τα δύο σύνολα δεδομένων δανείων σύροντάς τα από την αριστερή πλευρά της οθόνης προς τα δεξιά. Τα δύο σύνολα δεδομένων θα συνδεθούν και θα εμφανιστεί ένα σύμβολο ένωσης με κόκκινο θαυμαστικό. Κάντε κλικ σε αυτό και, στη συνέχεια, επιλέξτε και για τα δύο σύνολα δεδομένων το id κλειδί. Αφήστε τον τύπο σύνδεσης ως Εσωτερικός. Θα πρέπει να μοιάζει με αυτό:

- Επιλέξτε Αποθήκευση & κλείσιμο.
- Επιλέξτε Δημιουργία συνόλου δεδομένων. Δώστε ένα όνομα στο σύνολο δεδομένων.
- Μεταβείτε στη ροή δεδομένων, θα δείτε τα εξής.

- Για να εξερευνήσετε γρήγορα τα δεδομένα του δανείου, επιλέξτε Λάβετε πληροφορίες δεδομένων Και επιλέξτε το
loan_statusστήλη στόχος και Ταξινόμηση τύπος προβλήματος.
Το παραγόμενο Αναφορά ποιότητας δεδομένων και πληροφοριών παρέχει βασικά στατιστικά στοιχεία, απεικονίσεις και αναλύσεις σημασίας χαρακτηριστικών.
- Εξετάστε τις προειδοποιήσεις σχετικά με ζητήματα ποιότητας δεδομένων και μη ισορροπημένες κατηγορίες για να κατανοήσετε και να βελτιώσετε το σύνολο δεδομένων.
Για το σύνολο δεδομένων σε αυτήν την περίπτωση χρήσης, θα πρέπει να περιμένετε μια προειδοποίηση υψηλής προτεραιότητας "Πολύ χαμηλή βαθμολογία γρήγορης απόδοσης μοντέλου" και πολύ χαμηλή αποτελεσματικότητα μοντέλου σε κατηγορίες μειοψηφίας (φορτισμένες και τρέχουσες), υποδεικνύοντας την ανάγκη καθαρισμού και εξισορρόπησης των δεδομένων. Αναφέρομαι σε Τεκμηρίωση καμβά για να μάθετε περισσότερα σχετικά με την αναφορά πληροφοριών δεδομένων.


Με πάνω από 300 ενσωματωμένους μετασχηματισμούς που υποστηρίζονται από το SageMaker Data Wrangler, το SageMaker Canvas σάς δίνει τη δυνατότητα να τσακώνετε γρήγορα τα δεδομένα του δανείου. Μπορείτε να κάνετε κλικ στο Προσθέστε βήμα, και περιηγηθείτε ή αναζητήστε τους σωστούς μετασχηματισμούς. Για αυτό το σύνολο δεδομένων, χρησιμοποιήστε Λείπει η πτώση και Χειριστείτε τα ακραία σημεία για να καθαρίσετε τα δεδομένα και, στη συνέχεια, εφαρμόστε Ένα-καυτό κωδικοποίηση, και Διανυσματοποίηση κειμένου για να δημιουργήσετε δυνατότητες για ML.
Συνομιλία για προετοιμασία δεδομένων είναι μια νέα δυνατότητα φυσικής γλώσσας που επιτρέπει τη διαισθητική ανάλυση δεδομένων περιγράφοντας αιτήματα σε απλά αγγλικά. Για παράδειγμα, μπορείτε να λάβετε στατιστικά στοιχεία και να χαρακτηρίσετε ανάλυση συσχέτισης για τα δεδομένα του δανείου χρησιμοποιώντας φυσικές φράσεις. Το SageMaker Canvas κατανοεί και εκτελεί τις ενέργειες μέσω συνομιλιακών αλληλεπιδράσεων, πηγαίνοντας την προετοιμασία δεδομένων στο επόμενο επίπεδο.

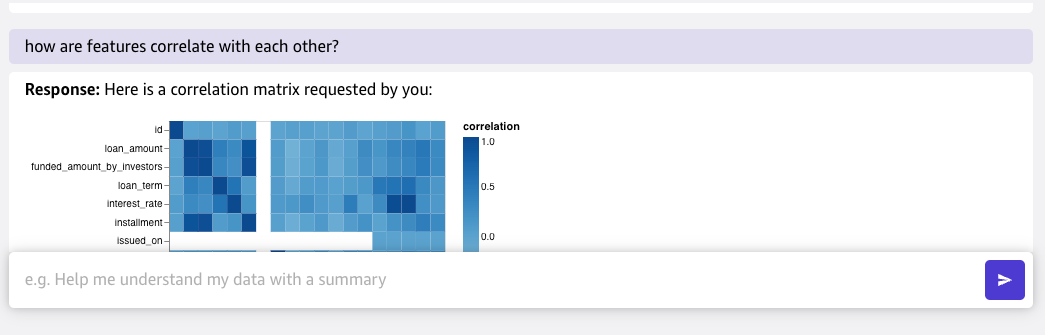
Μπορούμε να χρησιμοποιήσουμε Συνομιλία για προετοιμασία δεδομένων και ενσωματωμένος μετασχηματισμός για εξισορρόπηση των δεδομένων δανείου.
- Αρχικά, εισαγάγετε τις ακόλουθες οδηγίες:
replace “charged off” and “current” in loan_status with “default”
Συνομιλία για προετοιμασία δεδομένων δημιουργεί κώδικα για τη συγχώνευση δύο κλάσεων μειοψηφίας σε μία default τάξη.
- Επιλέξτε το ενσωματωμένο ΚΑΜΩΤ συνάρτηση μετασχηματισμού για τη δημιουργία συνθετικών δεδομένων για την προεπιλεγμένη κλάση.
Τώρα έχετε μια ισορροπημένη στήλη-στόχο.

- Μετά τον καθαρισμό και την επεξεργασία των δεδομένων του δανείου, αναδημιουργήστε το Αναφορά ποιότητας δεδομένων και πληροφοριών να επανεξετάσει τις βελτιώσεις.
Η προειδοποίηση υψηλής προτεραιότητας εξαφανίστηκε, υποδεικνύοντας βελτιωμένη ποιότητα δεδομένων. Μπορείτε να προσθέσετε περαιτέρω μετασχηματισμούς όπως απαιτείται για να βελτιώσετε την ποιότητα των δεδομένων για εκπαίδευση μοντέλων.


Κλιμακώστε και αυτοματοποιήστε την επεξεργασία δεδομένων
Για να αυτοματοποιήσετε την προετοιμασία δεδομένων, μπορείτε να εκτελέσετε ή να προγραμματίσετε ολόκληρη τη ροή εργασίας ως κατανεμημένη εργασία επεξεργασίας Spark για την επεξεργασία ολόκληρου του συνόλου δεδομένων ή τυχόν νέων συνόλων δεδομένων σε κλίμακα.
- Στη ροή δεδομένων, προσθέστε έναν κόμβο προορισμού Amazon S3.
- Ξεκινήστε μια εργασία επεξεργασίας SageMaker επιλέγοντας Δημιουργήστε εργασία.
- Διαμορφώστε την εργασία επεξεργασίας και επιλέξτε Δημιουργία, επιτρέποντας στη ροή να εκτελείται σε εκατοντάδες GB δεδομένων χωρίς δειγματοληψία.
Οι ροές δεδομένων μπορούν να ενσωματωθούν σε αγωγούς MLOps από άκρο σε άκρο για να αυτοματοποιηθεί ο κύκλος ζωής του ML. Οι ροές δεδομένων μπορούν να τροφοδοτηθούν σε σημειωματάρια SageMaker Studio ως το βήμα επεξεργασίας δεδομένων σε μια διοχέτευση SageMaker ή για την ανάπτυξη μιας διοχέτευσης συμπερασμάτων SageMaker. Αυτό επιτρέπει την αυτοματοποίηση της ροής από την προετοιμασία δεδομένων έως την εκπαίδευση και τη φιλοξενία του SageMaker.

Δημιουργήστε και αναπτύξτε το μοντέλο στον καμβά SageMaker
Μετά την προετοιμασία των δεδομένων, μπορούμε να εξάγουμε απρόσκοπτα το τελικό σύνολο δεδομένων στο SageMaker Canvas για να δημιουργήσουμε, να εκπαιδεύσουμε και να αναπτύξουμε ένα μοντέλο πρόβλεψης πληρωμής δανείου.
- Επιλέξτε Δημιουργήστε μοντέλο στον τελευταίο κόμβο της ροής δεδομένων ή στο παράθυρο κόμβων.
Αυτό εξάγει το σύνολο δεδομένων και εκκινεί τη ροή εργασίας δημιουργίας καθοδηγούμενου μοντέλου.
- Ονομάστε το εξαγόμενο σύνολο δεδομένων και επιλέξτε εξαγωγή.

- Επιλέξτε Δημιουργήστε μοντέλο από την κοινοποίηση.

- Ονομάστε το μοντέλο, επιλέξτε Προγνωστική ανάλυση, και επιλέξτε Δημιουργία.
Αυτό θα σας ανακατευθύνει στη σελίδα κατασκευής του μοντέλου.

- Συνεχίστε με την εμπειρία κατασκευής μοντέλων SageMaker Canvas επιλέγοντας τη στήλη-στόχο και τον τύπο μοντέλου και, στη συνέχεια, επιλέξτε Γρήγορη κατασκευή or Τυπική κατασκευή.
Για να μάθετε περισσότερα σχετικά με την εμπειρία κατασκευής μοντέλων, ανατρέξτε στο Κατασκευάστε ένα μοντέλο.

Όταν ολοκληρωθεί η εκπαίδευση, μπορείτε να χρησιμοποιήσετε το μοντέλο για να προβλέψετε νέα δεδομένα ή να τα αναπτύξετε. Αναφέρομαι σε Αναπτύξτε μοντέλα ML που είναι ενσωματωμένα στον καμβά Amazon SageMaker στα τελικά σημεία του Amazon SageMaker σε πραγματικό χρόνο για να μάθετε περισσότερα σχετικά με την ανάπτυξη ενός μοντέλου από το SageMaker Canvas.

Συμπέρασμα
Σε αυτήν την ανάρτηση, δείξαμε τις δυνατότητες του SageMaker Canvas από άκρο σε άκρο αναλαμβάνοντας τον ρόλο ενός επαγγελματία χρηματοοικονομικών δεδομένων που προετοιμάζει δεδομένα για την πρόβλεψη πληρωμής δανείου, με την υποστήριξη του SageMaker Data Wrangler. Η διαδραστική προετοιμασία δεδομένων επέτρεψε τον γρήγορο καθαρισμό, τον μετασχηματισμό και την ανάλυση των δεδομένων του δανείου για τη μηχανική ενημερωτικών χαρακτηριστικών. Καταργώντας τις πολυπλοκότητες κωδικοποίησης, το SageMaker Canvas μας επέτρεψε να επαναλάβουμε γρήγορα για να δημιουργήσουμε ένα σύνολο δεδομένων εκπαίδευσης υψηλής ποιότητας. Αυτή η επιταχυνόμενη ροή εργασίας οδηγεί απευθείας στη δημιουργία, την εκπαίδευση και την ανάπτυξη ενός αποδοτικού μοντέλου ML για επιχειρηματικό αντίκτυπο. Με την ολοκληρωμένη προετοιμασία δεδομένων και την ενοποιημένη εμπειρία από δεδομένα έως πληροφορίες, το SageMaker Canvas σάς δίνει τη δυνατότητα να βελτιώσετε τα αποτελέσματα ML. Για περισσότερες πληροφορίες σχετικά με τον τρόπο επιτάχυνσης των ταξιδιών σας από δεδομένα σε επιχειρηματικές πληροφορίες, ανατρέξτε στην ενότητα Ημέρα εμβάπτισης καμβά SageMaker και Οδηγός χρήστη AWS.
Σχετικά με τους συγγραφείς
 Ο Δρ Τσανγκσά Μα είναι Ειδικός AI/ML στο AWS. Είναι τεχνολόγος με διδακτορικό στην Επιστήμη Υπολογιστών, μεταπτυχιακό στην Εκπαιδευτική Ψυχολογία και πολυετή εμπειρία στην επιστήμη των δεδομένων και ανεξάρτητη συμβουλευτική στην AI/ML. Είναι παθιασμένη με την έρευνα μεθοδολογικών προσεγγίσεων για μηχανική και ανθρώπινη νοημοσύνη. Εκτός δουλειάς, της αρέσει η πεζοπορία, το μαγείρεμα, το κυνήγι του φαγητού και να περνά χρόνο με φίλους και οικογένειες.
Ο Δρ Τσανγκσά Μα είναι Ειδικός AI/ML στο AWS. Είναι τεχνολόγος με διδακτορικό στην Επιστήμη Υπολογιστών, μεταπτυχιακό στην Εκπαιδευτική Ψυχολογία και πολυετή εμπειρία στην επιστήμη των δεδομένων και ανεξάρτητη συμβουλευτική στην AI/ML. Είναι παθιασμένη με την έρευνα μεθοδολογικών προσεγγίσεων για μηχανική και ανθρώπινη νοημοσύνη. Εκτός δουλειάς, της αρέσει η πεζοπορία, το μαγείρεμα, το κυνήγι του φαγητού και να περνά χρόνο με φίλους και οικογένειες.
 Ajjay Govindaram είναι Senior Solutions Architect στην AWS. Συνεργάζεται με στρατηγικούς πελάτες που χρησιμοποιούν AI/ML για την επίλυση σύνθετων επιχειρηματικών προβλημάτων. Η εμπειρία του έγκειται στην παροχή τεχνικής καθοδήγησης καθώς και στη σχεδιαστική βοήθεια για μικρές έως μεγάλης κλίμακας αναπτύξεις εφαρμογών AI/ML. Οι γνώσεις του κυμαίνονται από την αρχιτεκτονική εφαρμογών έως τα μεγάλα δεδομένα, την ανάλυση και τη μηχανική μάθηση. Του αρέσει να ακούει μουσική ενώ ξεκουράζεται, να βιώνει την ύπαιθρο και να περνά χρόνο με τα αγαπημένα του πρόσωπα.
Ajjay Govindaram είναι Senior Solutions Architect στην AWS. Συνεργάζεται με στρατηγικούς πελάτες που χρησιμοποιούν AI/ML για την επίλυση σύνθετων επιχειρηματικών προβλημάτων. Η εμπειρία του έγκειται στην παροχή τεχνικής καθοδήγησης καθώς και στη σχεδιαστική βοήθεια για μικρές έως μεγάλης κλίμακας αναπτύξεις εφαρμογών AI/ML. Οι γνώσεις του κυμαίνονται από την αρχιτεκτονική εφαρμογών έως τα μεγάλα δεδομένα, την ανάλυση και τη μηχανική μάθηση. Του αρέσει να ακούει μουσική ενώ ξεκουράζεται, να βιώνει την ύπαιθρο και να περνά χρόνο με τα αγαπημένα του πρόσωπα.
 Huong Nguyen είναι Sr. Product Manager στην AWS. Είναι επικεφαλής της προετοιμασίας δεδομένων ML για το SageMaker Canvas και το SageMaker Data Wrangler, με 15 χρόνια εμπειρίας στην κατασκευή προϊόντων με επίκεντρο τον πελάτη και δεδομένα.
Huong Nguyen είναι Sr. Product Manager στην AWS. Είναι επικεφαλής της προετοιμασίας δεδομένων ML για το SageMaker Canvas και το SageMaker Data Wrangler, με 15 χρόνια εμπειρίας στην κατασκευή προϊόντων με επίκεντρο τον πελάτη και δεδομένα.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/machine-learning/accelerate-data-preparation-for-ml-with-comprehensive-data-preparation-capabilities-and-a-natural-language-interface-in-amazon-sagemaker-canvas/

