Αυτή η επισκέπτης ανάρτηση γράφτηκε από τους Vihan Lakshman, Tharun Medini και Anshumali Shrivastava από το ThirdAI.
Η βαθιά μάθηση μεγάλης κλίμακας έχει πρόσφατα δημιουργήσει επαναστατικές προόδους σε μια τεράστια γκάμα πεδίων. Αν και αυτή η εκπληκτική πρόοδος στην τεχνητή νοημοσύνη παραμένει αξιοσημείωτη, το οικονομικό κόστος και η κατανάλωση ενέργειας που απαιτούνται για την εκπαίδευση αυτών των μοντέλων έχει αναδειχθεί ως κρίσιμο σημείο συμφόρησης λόγω της ανάγκης για εξειδικευμένο υλικό όπως οι GPU. Παραδοσιακά, ακόμη και τα νευρωνικά μοντέλα μέτριου μεγέθους απαιτούσαν δαπανηρούς επιταχυντές υλικού για εκπαίδευση, γεγονός που περιορίζει τον αριθμό των οργανισμών με τα οικονομικά μέσα για να επωφεληθούν πλήρως από αυτήν την τεχνολογία.
Η ThirdAI Corp., που ιδρύθηκε το 2021, είναι μια startup αφιερωμένη στην αποστολή του εκδημοκρατισμού των τεχνολογιών τεχνητής νοημοσύνης μέσω αλγοριθμικών καινοτομιών και λογισμικού που αλλάζουν ριζικά τα οικονομικά της βαθιάς μάθησης. Έχουμε αναπτύξει μια αραιή μηχανή βαθιάς εκμάθησης, γνωστή ως BOLT, που έχει σχεδιαστεί ειδικά για εκπαίδευση και ανάπτυξη μοντέλων σε τυπικό υλικό CPU σε αντίθεση με δαπανηρούς και ενεργοβόρους επιταχυντές όπως οι GPU. Πολλοί από τους πελάτες μας έχουν ανέφερε έντονη ικανοποίηση με την ικανότητα του ThirdAI να εκπαιδεύει και να αναπτύσσει μοντέλα βαθιάς μάθησης για κρίσιμα επιχειρηματικά προβλήματα σε οικονομικά αποδοτική υποδομή CPU.
Σε αυτήν την ανάρτηση, διερευνούμε τις δυνατότητες του επεξεργαστή AWS Graviton3 να επιταχύνει την εκπαίδευση νευρωνικών δικτύων για τη μοναδική μηχανή βαθιάς εκμάθησης που βασίζεται σε CPU της ThirdAI.
Τα πλεονεκτήματα των CPU υψηλής απόδοσης
Στο ThirdAI, επιτυγχάνουμε αυτές τις ανακαλύψεις στην αποτελεσματική εκπαίδευση νευρωνικών δικτύων σε CPU μέσω ιδιόκτητων δυναμικών αραιών αλγορίθμων που ενεργοποιούν μόνο ένα υποσύνολο νευρώνων για μια δεδομένη είσοδο (δείτε την παρακάτω εικόνα), παρακάμπτοντας έτσι την ανάγκη για πλήρεις πυκνούς υπολογισμούς. Σε αντίθεση με άλλες προσεγγίσεις για την εκπαίδευση αραιού νευρωνικών δικτύων, το ThirdAI χρησιμοποιεί κατακερματισμός ευαίσθητος στην τοποθεσία για να επιλέξετε δυναμικά νευρώνες για μια δεδομένη είσοδο, όπως φαίνεται στις έντονες γραμμές παρακάτω. Σε ορισμένες περιπτώσεις, έχουμε μάλιστα παρατηρήσει ότι μας αραιά μοντέλα που βασίζονται σε CPU εκπαιδεύστε γρηγορότερα από την αντίστοιχη πυκνή αρχιτεκτονική στις GPU.
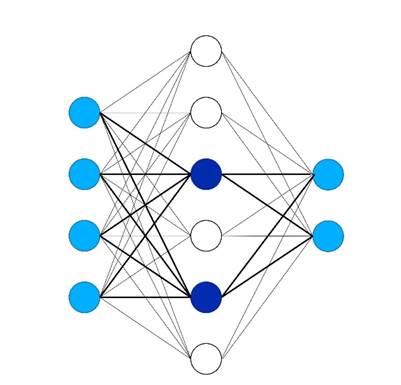
Δεδομένου ότι πολλοί από τους πελάτες-στόχους μας λειτουργούν στο cloud - και μεταξύ αυτών, η πλειονότητα χρησιμοποιεί AWS - ήμασταν ενθουσιασμένοι που δοκιμάσαμε τον επεξεργαστή AWS Graviton3 για να δούμε εάν οι εντυπωσιακές βελτιώσεις τιμής-απόδοσης της καινοτομίας πυριτίου της Amazon θα μεταφραστούν στο μοναδικό μας φόρτο εργασίας αραιής εκπαίδευσης σε νευρωνικά δίκτυα και ως εκ τούτου παρέχουν περαιτέρω εξοικονόμηση πόρων για τους πελάτες. Αν και τόσο η ερευνητική κοινότητα όσο και η ομάδα AWS Graviton έχουν προσφέρει συναρπαστικές εξελίξεις στην επιτάχυνση συμπέρασμα νευρωνικών δικτύων σε περιπτώσεις CPU, εμείς στο ThirdAI είμαστε, εξ όσων γνωρίζουμε, οι πρώτοι που μελετάμε σοβαρά πώς να εκπαιδεύουμε αποτελεσματικά νευρωνικά μοντέλα σε CPU.
Όπως φαίνεται στα αποτελέσματά μας, παρατηρήσαμε μια σημαντική επιτάχυνση εκπαίδευσης με το AWS Graviton3 σε σχέση με τις συγκρίσιμες περιπτώσεις Intel και NVIDIA σε αρκετούς αντιπροσωπευτικούς φόρτους εργασίας μοντελοποίησης.
Τύποι παρουσίας
Για την αξιολόγησή μας, εξετάσαμε δύο συγκρίσιμες περιπτώσεις CPU AWS: ένα μηχάνημα c6i.8xlarge που τροφοδοτείται από τον επεξεργαστή Ice Lake της Intel και ένα c7g.8xlarge που τροφοδοτείται από το AWS Graviton3. Ο παρακάτω πίνακας συνοψίζει τις λεπτομέρειες για κάθε περίπτωση.
| Παράδειγμα | vCPU | RAM (GB) | Επεξεργαστής | Τιμή κατ' απαίτηση (us-east-1) |
| c7g.8xlarge | 32 | 64 | AWS Graviton3 | $ 1.1562 / ώρα |
| c6i.8xlarge | 32 | 64 | Intel Ice Lake | $ 1.36 / ώρα |
| g5g.8xlarge (GPU) | 32 | 64 με μνήμη GPU 16 GB | Επεξεργαστές AWS Graviton2 με 1 GPU NVIDIA T4G | $ 1.3720 / ώρα |
Αξιολόγηση 1: Ακραία ταξινόμηση
Για την πρώτη μας αξιολόγηση, εστιάζουμε στο πρόβλημα της ακραίας ταξινόμησης πολλαπλών ετικετών (XMC), ενός ολοένα και πιο δημοφιλούς μοντέλου μηχανικής μάθησης (ML) με έναν αριθμό πρακτικών εφαρμογών στην αναζήτηση και τις συστάσεις (συμπεριλαμβανομένου του Amazon). Για την αξιολόγησή μας, εστιάζουμε στο κοινό Εργασία σύστασης προϊόντων Amazon-670K, το οποίο, δεδομένου ενός προϊόντος εισόδου, προσδιορίζει παρόμοια προϊόντα από μια συλλογή άνω των 670,000 ειδών.
Σε αυτό το πείραμα, συγκρίνουμε τον κινητήρα BOLT του ThirdAI έναντι του TensorFlow 2.11 και του PyTorch 2.0 στις προαναφερθείσες επιλογές υλικού: Intel Ice Lake, AWS Graviton3 και GPU NVIDIA T4G. Για τα πειράματά μας σε Intel και AWS Graviton, χρησιμοποιούμε το AWS Deep Learning AMI (Ubuntu 18.04) έκδοση 59.0. Για την αξιολόγηση της GPU μας, χρησιμοποιούμε το NVIDIA GPU-Optimized Arm64 AMI, διαθέσιμο μέσω του AWS Marketplace. Για αυτήν την αξιολόγηση, χρησιμοποιούμε το Αρχιτεκτονική μοντέλου SLIDE, το οποίο επιτυγχάνει τόσο ανταγωνιστική απόδοση σε αυτή την ακραία εργασία ταξινόμησης όσο και ισχυρή απόδοση εκπαίδευσης σε CPU. Για τις συγκρίσεις μας TensorFlow και PyTorch, υλοποιούμε την ανάλογη έκδοση της αρχιτεκτονικής SLIDE multi-layer perceptron (MLP) με πυκνούς πολλαπλασιασμούς πινάκων. Εκπαιδεύουμε κάθε μοντέλο για πέντε εποχές (πλήρες περάσματα μέσα από το σύνολο δεδομένων εκπαίδευσης) με σταθερό μέγεθος παρτίδας 256 και ρυθμό εκμάθησης 0.001. Παρατηρήσαμε ότι όλα τα μοντέλα πέτυχαν την ίδια ακρίβεια δοκιμής 33.6%.
Το παρακάτω γράφημα συγκρίνει τον χρόνο εκπαίδευσης του BOLT του ThirdAI με το TensorFlow 2.11 και το PyTorch 2.0 στο σημείο αναφοράς ακραίας ταξινόμησης Amazon670k. Όλα τα μοντέλα επιτυγχάνουν την ίδια ακρίβεια δοκιμής. Παρατηρούμε ότι το AWS Graviton3 επιταχύνει σημαντικά την απόδοση του BOLT εκτός συσκευασίας χωρίς να απαιτούνται προσαρμογές — κατά περίπου 40%. Το BOLT του ThirdAI στο AWS Graviton3 επιτυγχάνει επίσης σημαντικά ταχύτερη εκπαίδευση από τα μοντέλα TensorFlow ή PyTorch που έχουν εκπαιδευτεί στη GPU. Λάβετε υπόψη ότι δεν υπάρχει αποτέλεσμα ThirdAI στο σημείο αναφοράς GPU της NVIDIA, επειδή το BOLT έχει σχεδιαστεί για να λειτουργεί σε CPU. Δεν περιλαμβάνουμε σημεία αναφοράς CPU TensorFlow και PyTorch λόγω του απαγορευτικά μεγάλου χρόνου εκπαίδευσης.
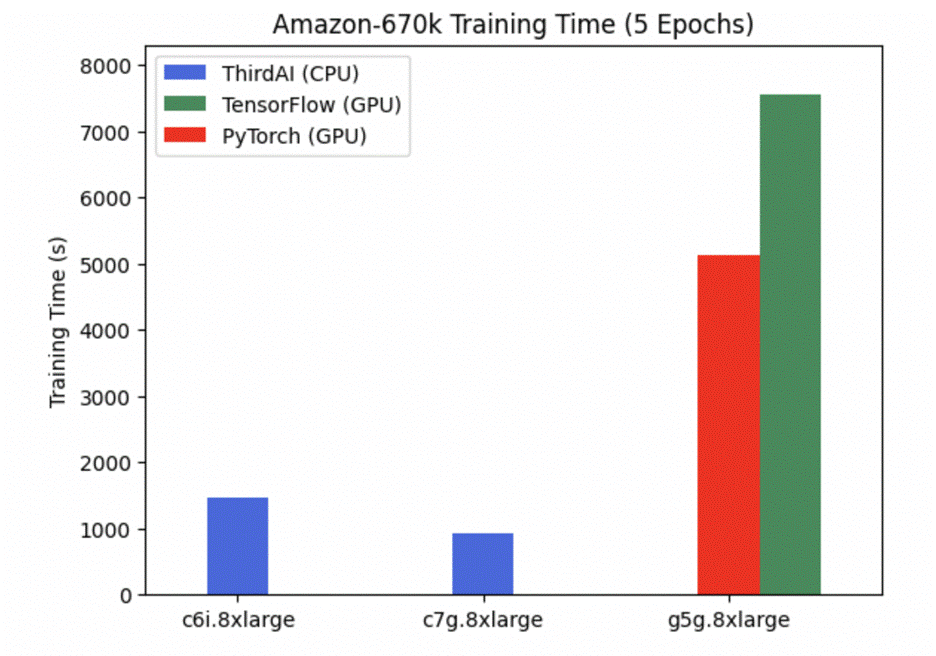
Ο παρακάτω πίνακας συνοψίζει τον χρόνο εκπαίδευσης και την ακρίβεια δοκιμής για κάθε επεξεργαστή/εξειδικευμένο επεξεργαστή (GPU).
| Επεξεργαστής | Κινητήρας | Χρόνος (οι) προπόνησης | Δοκιμή ακρίβειας |
| Intel Ice Lake (c6i.8xlarge) | BOLT | 1470 | 33.6 |
| AWS Graviton3 (c7g.8xlarge) | BOLT | 935 | 33.6 |
| NVIDIA T4G (g5g.8xlarge) | TensorFlow | 7550 | 33.6 |
| NVIDIA T4G (g5g.8xlarge) | PyTorch | 5130 | 33.6 |
Αξιολόγηση 2: Ανάλυση συναισθήματος πολικότητας Yelp
Για τη δεύτερη αξιολόγησή μας, εστιάζουμε στο λαϊκό Yelp Polarity σημείο αναφοράς ανάλυσης συναισθήματος, το οποίο περιλαμβάνει την ταξινόμηση μιας κριτικής ως θετικής ή αρνητικής. Για αυτήν την αξιολόγηση, συγκρίνουμε τα ThirdAI's Universal Deep Transformers (UDT) μοντέλο έναντι ενός τελειοποιημένου DistilBERT δίκτυο, ένα συμπιεσμένο προεκπαιδευμένο μοντέλο γλώσσας που επιτυγχάνει απόδοση σχεδόν αιχμής με μειωμένη καθυστέρηση συμπερασμάτων. Επειδή η βελτίωση των μοντέλων DistilBERT σε μια CPU θα χρειαζόταν απαγορευτικά πολύ χρόνο (τουλάχιστον αρκετές ημέρες), συγκρίνουμε τα μοντέλα που βασίζονται σε CPU της ThirdAI έναντι του DistilBERT που έχουν συντονιστεί με ακρίβεια σε μια GPU. Εκπαιδεύουμε όλα τα μοντέλα με μέγεθος παρτίδας 256 για ένα μόνο πέρασμα από τα δεδομένα (μία εποχή). Σημειώνουμε ότι μπορούμε να επιτύχουμε ελαφρώς υψηλότερη ακρίβεια με το BOLT με επιπλέον περάσματα μέσω των δεδομένων, αλλά περιοριζόμαστε σε ένα μόνο πέρασμα σε αυτήν την αξιολόγηση για συνέπεια.
Όπως φαίνεται στο παρακάτω σχήμα, το AWS Graviton3 επιταχύνει και πάλι σημαντικά την εκπαίδευση του μοντέλου UDT του ThirdAI. Επιπλέον, το UDT είναι σε θέση να επιτύχει συγκρίσιμη ακρίβεια δοκιμής με το DistilBERT με ένα κλάσμα του χρόνου εκπαίδευσης και χωρίς την ανάγκη για GPU. Σημειώνουμε ότι έχουν γίνει και πρόσφατες εργασίες σε βελτιστοποίηση της μικρορύθμισης του Yelp Polarity σε CPU. Τα μοντέλα μας, ωστόσο, εξακολουθούν να επιτυγχάνουν μεγαλύτερα κέρδη απόδοσης και αποφεύγουν το κόστος της προεκπαίδευσης, το οποίο είναι σημαντικό και απαιτεί τη χρήση επιταχυντών υλικού όπως οι GPU.
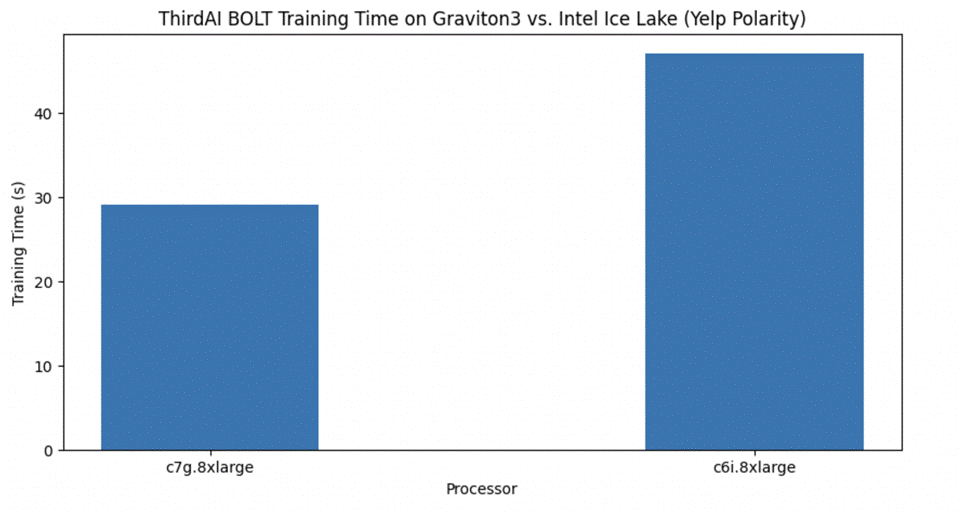
Ο παρακάτω πίνακας συνοψίζει τον χρόνο εκπαίδευσης, την ακρίβεια της δοκιμής και την καθυστέρηση συμπερασμάτων.
| Επεξεργαστής | Κινητήρας | Μοντέλο | Χρόνος (οι) προπόνησης | Δοκιμή ακρίβειας | Λάθος συμπερασμάτων (ms) |
| Intel Icelake (c6i.8xlarge) | BOLT | ΕΞΩ | 47 | 93.2 | <1 |
| Graviton3 (c7g.8xlarge) | BOLT | ΕΞΩ | 29 | 92.9 | <1 |
| GPU T4G (g5g.8xlarge) | TensorFlow | DistilBERT | 4200 | 93.3 | 8.7 |
| GPU T4G (g5g.8xlarge) | PyTorch | DistilBERT | 3780 | 93.4 | 8.3 |
Αξιολόγηση 3: Ταξινόμηση κειμένου πολλαπλών τάξεων (DBPedia)
Για την τελική μας αξιολόγηση, εστιάζουμε στο πρόβλημα της ταξινόμησης κειμένου πολλών κλάσεων, το οποίο περιλαμβάνει την αντιστοίχιση μιας ετικέτας σε ένα δεδομένο κείμενο εισόδου από ένα σύνολο περισσότερων από δύο κλάσεων εξόδου. Εστιάζουμε στο DBPedia σημείο αναφοράς, το οποίο αποτελείται από 14 πιθανές κατηγορίες εξόδου. Και πάλι, βλέπουμε ότι το AWS Graviton3 επιταχύνει την απόδοση του UDT σε σχέση με το συγκρίσιμο παράδειγμα της Intel κατά περίπου 40%. Βλέπουμε επίσης ότι το BOLT επιτυγχάνει συγκρίσιμα αποτελέσματα με το μοντέλο που βασίζεται σε μετασχηματιστή DistilBERT, το οποίο έχει ρυθμιστεί με ακρίβεια σε μια GPU, ενώ επιτυγχάνει λανθάνουσα κατάσταση κάτω του χιλιοστού του δευτερολέπτου.
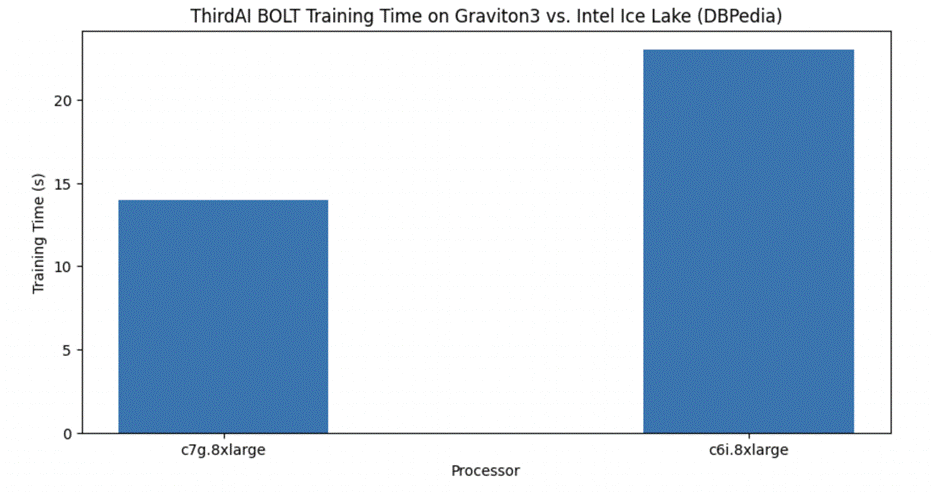
Ο παρακάτω πίνακας συνοψίζει τον χρόνο εκπαίδευσης, την ακρίβεια της δοκιμής και την καθυστέρηση συμπερασμάτων.
| Επεξεργαστής | Κινητήρας | Μοντέλο | Χρόνος (οι) προπόνησης | Δοκιμή ακρίβειας | Λάθος συμπερασμάτων (ms) |
| Intel Icelake (c6i.8xlarge) | BOLT | ΕΞΩ | 23 | 98.23 | <1 |
| Graviton3 (c7g.8xlarge) | BOLT | ΕΞΩ | 14 | 98.10 | <1 |
| GPU T4G (g5g.8xlarge) | TensorFlow | DistilBERT | 4320 | 99.23 | 8.6 |
| GPU T4G (g5g.8xlarge) | PyTorch | DistilBERT | 3480 | 99.29 | 8 |
Ξεκινήστε με το ThirdAI στο AWS Graviton
Έχουμε σχεδιάσει το λογισμικό BOLT για συμβατότητα με όλες τις κύριες αρχιτεκτονικές CPU, συμπεριλαμβανομένου του AWS Graviton3. Στην πραγματικότητα, δεν χρειάστηκε να κάνουμε προσαρμογές στον κώδικά μας για να τρέξουμε στο AWS Graviton3. Επομένως, μπορείτε να χρησιμοποιήσετε το ThirdAI για εκπαίδευση και ανάπτυξη μοντέλων στο AWS Graviton3 χωρίς πρόσθετη προσπάθεια. Επιπλέον, όπως αναλύεται στην πρόσφατη μας λευκή βίβλο έρευνας, έχουμε αναπτύξει ένα σύνολο καινοτόμων μαθηματικών τεχνικών για να συντονίζουμε αυτόματα τις εξειδικευμένες υπερπαραμέτρους που σχετίζονται με τα αραιά μοντέλα μας, επιτρέποντας στα μοντέλα μας να λειτουργούν καλά αμέσως έξω από το κουτί.
Σημειώνουμε επίσης ότι τα μοντέλα μας κατά κύριο λόγο λειτουργούν καλά για εργασίες αναζήτησης, συστάσεων και επεξεργασίας φυσικής γλώσσας που συνήθως διαθέτουν μεγάλους, υψηλών διαστάσεων χώρους εξόδου και απαίτηση εξαιρετικά χαμηλής καθυστέρησης συμπερασμάτων. Εργαζόμαστε ενεργά για την επέκταση των μεθόδων μας σε πρόσθετους τομείς, όπως η όραση υπολογιστή, αλλά έχετε υπόψη σας ότι οι βελτιώσεις απόδοσης δεν μεταφράζονται σε όλους τους τομείς ML αυτήν τη στιγμή.
Συμπέρασμα
Σε αυτήν την ανάρτηση, ερευνήσαμε τη δυνατότητα του επεξεργαστή AWS Graviton3 να επιταχύνει την εκπαίδευση νευρωνικών δικτύων για τη μοναδική μηχανή βαθιάς εκμάθησης που βασίζεται σε CPU της ThirdAI. Τα σημεία αναφοράς μας για την αναζήτηση, την ταξινόμηση κειμένου και τα κριτήρια αναφοράς προτάσεων υποδεικνύουν ότι το AWS Graviton3 μπορεί να επιταχύνει τους φόρτους εργασίας εκπαίδευσης μοντέλων της ThirdAI κατά 30–40% σε σύγκριση με τις συγκρίσιμες περιπτώσεις x86 με βελτίωση της τιμής-απόδοσης σχεδόν 50%. Επιπλέον, επειδή οι παρουσίες AWS Graviton3 είναι διαθέσιμες με χαμηλότερο κόστος από τις ανάλογες μηχανές Intel και NVIDIA και επιτρέπουν μικρότερους χρόνους εκπαίδευσης και συμπερασμάτων, μπορείτε να ξεκλειδώσετε περαιτέρω την αξία του μοντέλου χρήσης AWS pay-as-you-go χρησιμοποιώντας χαμηλότερο κόστος μηχανές για μικρότερη χρονική διάρκεια.
Είμαστε πολύ ενθουσιασμένοι με την εξοικονόμηση τιμής και απόδοσης του AWS Graviton3 και θα προσπαθήσουμε να μεταδώσουμε αυτές τις βελτιώσεις στους πελάτες μας, ώστε να μπορούν να απολαμβάνουν ταχύτερη εκπαίδευση ML και συμπέρασμα με βελτιωμένη απόδοση σε CPU χαμηλού κόστους. Ως πελάτες του AWS οι ίδιοι, είμαστε ενθουσιασμένοι με την ταχύτητα με την οποία το AWS Graviton3 μας επιτρέπει να πειραματιζόμαστε με τα μοντέλα μας και ανυπομονούμε να χρησιμοποιήσουμε στο μέλλον περισσότερη καινοτομία πυριτίου αιχμής από την AWS. Τεχνικός οδηγός Graviton είναι ένας καλός πόρος που πρέπει να λάβετε υπόψη κατά την αξιολόγηση του φόρτου εργασίας σας ML για εκτέλεση στο Graviton. Μπορείτε επίσης να δοκιμάσετε παρουσίες Graviton t4g δωρεάν δοκιμή.
Το περιεχόμενο και οι απόψεις σε αυτήν την ανάρτηση ανήκουν στον συγγραφέα τρίτου μέρους και η AWS δεν ευθύνεται για το περιεχόμενο ή την ακρίβεια αυτής της ανάρτησης. Τη στιγμή της συγγραφής του ιστολογίου το πιο πρόσφατο παράδειγμα ήταν το c6i και ως εκ τούτου η σύγκριση έγινε με περιπτώσεις c6i.
Σχετικά με το Συγγραφέας
Vihan Lakshman – Ο Vihan Lakshman είναι επιστήμονας ερευνητής στην ThirdAI Corp. που επικεντρώνεται στην ανάπτυξη συστημάτων για βαθιά μάθηση με αποδοτική χρήση πόρων. Πριν από το ThirdAI, εργάστηκε ως Εφαρμοσμένος Επιστήμονας στο Amazon και έλαβε προπτυχιακούς και μεταπτυχιακούς τίτλους από το Πανεπιστήμιο του Στάνφορντ. Ο Vihan είναι επίσης αποδέκτης ερευνητικής υποτροφίας του Εθνικού Ιδρύματος Επιστημών.
Θαρούν Μεντίνι – Ο Tharun Medini είναι ο συνιδρυτής και CTO της ThirdAI Corp. Έκανε το διδακτορικό του στο «Hashing Algorithms for Search and Information Retrieval» στο Πανεπιστήμιο Rice. Πριν από το ThirdAI, ο Tharun εργαζόταν στην Amazon και την Target. Ο Tharun είναι αποδέκτης πολλών βραβείων για την έρευνά του, συμπεριλαμβανομένης της υποτροφίας BP του Ινστιτούτου Ken Kennedy, της Υποτροφίας της Αμερικανικής Εταιρείας Ινδών Μηχανικών και της υποτροφίας πτυχιούχων του Πανεπιστημίου Rice.
Anshumali Shrivastava – Ο Anshumali Shrivastava είναι αναπληρωτής καθηγητής στο τμήμα πληροφορικής στο Πανεπιστήμιο Rice. Είναι επίσης ο ιδρυτής και διευθύνων σύμβουλος της ThirdAI Corp, μιας εταιρείας που εκδημοκρατίζει την τεχνητή νοημοσύνη σε υλικό βασικών προϊόντων μέσω καινοτομιών λογισμικού. Τα ευρύτατα ερευνητικά του ενδιαφέροντα περιλαμβάνουν πιθανολογικούς αλγόριθμους για την εξοικονόμηση πόρων βαθιάς μάθησης. Το 2018, το Science News τον ανέδειξε ως έναν από τους Top-10 επιστήμονες κάτω των 40 ετών για παρακολούθηση. Είναι αποδέκτης του National Science Foundation CAREER Award, ενός Young Investigator Award από το Γραφείο Επιστημονικής Έρευνας της Πολεμικής Αεροπορίας, ενός βραβείου έρευνας μηχανικής μάθησης από την Amazon και ενός Data Science Research Award από την Adobe. Έχει κερδίσει πολλά βραβεία χαρτιού, συμπεριλαμβανομένων των Best Paper Awards στο NIPS 2014 και MLSys 2022, καθώς και το βραβείο Most Reproducible Paper στο SIGMOD 2019. Το έργο του σχετικά με αποτελεσματικές τεχνολογίες μηχανικής μάθησης σε CPUs έχει καλυφθεί από τον δημοφιλή τύπο, όπως η Wall Street Journal, New York Times, TechCrunch, NDTV κ.λπ.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/machine-learning/accelerating-large-scale-neural-network-training-on-cpus-with-thirdai-and-aws-graviton/

