Ο εντοπισμός απάτης είναι ένα σημαντικό πρόβλημα που έχει εφαρμογές στις χρηματοοικονομικές υπηρεσίες, στα μέσα κοινωνικής δικτύωσης, στο ηλεκτρονικό εμπόριο, στα τυχερά παιχνίδια και σε άλλους κλάδους. Αυτή η ανάρτηση παρουσιάζει μια εφαρμογή μιας λύσης ανίχνευσης απάτης χρησιμοποιώντας το μοντέλο Συνελικτικού Δικτύου Σχεσιακού Γραφήματος (RGCN) για την πρόβλεψη της πιθανότητας ότι μια συναλλαγή είναι δόλια τόσο μέσω των τρόπων μεταγωγής όσο και μέσω επαγωγικών συμπερασμάτων. Μπορείτε να αναπτύξετε την εφαρμογή μας σε ένα Amazon Sage Maker τελικό σημείο ως λύση ανίχνευσης απάτης σε πραγματικό χρόνο, χωρίς να απαιτείται εξωτερική αποθήκευση γραφημάτων ή ενορχήστρωση, μειώνοντας έτσι σημαντικά το κόστος ανάπτυξης του μοντέλου.
Οι επιχειρήσεις που αναζητούν μια πλήρως διαχειριζόμενη υπηρεσία AWS AI για ανίχνευση απάτης μπορούν επίσης να χρησιμοποιήσουν Ανιχνευτής απάτης Amazon, το οποίο μπορείτε να χρησιμοποιήσετε για να εντοπίσετε ύποπτες διαδικτυακές πληρωμές, να εντοπίσετε νέα απάτη λογαριασμού, να αποτρέψετε την κατάχρηση του προγράμματος δοκιμής και αφοσίωσης ή να βελτιώσετε τον εντοπισμό εξαγοράς λογαριασμού.
Επισκόπηση λύσεων
Το παρακάτω διάγραμμα περιγράφει ένα υποδειγματικό δίκτυο χρηματοοικονομικών συναλλαγών που περιλαμβάνει διαφορετικούς τύπους πληροφοριών. Κάθε συναλλαγή περιέχει πληροφορίες όπως αναγνωριστικά συσκευών, αναγνωριστικά Wi-Fi, διευθύνσεις IP, φυσικές τοποθεσίες, αριθμούς τηλεφώνου και άλλα. Αντιπροσωπεύουμε τα σύνολα δεδομένων συναλλαγών μέσω ενός ετερογενούς γραφήματος που περιέχει διαφορετικούς τύπους κόμβων και ακμών. Στη συνέχεια, το πρόβλημα ανίχνευσης απάτης αντιμετωπίζεται ως εργασία ταξινόμησης κόμβων σε αυτό το ετερογενές γράφημα.

Τα νευρωνικά δίκτυα γραφημάτων (GNN) έχουν δείξει πολλά υποσχόμενα για την αντιμετώπιση προβλημάτων ανίχνευσης απάτης, ξεπερνώντας τις δημοφιλείς εποπτευόμενες μεθόδους εκμάθησης, όπως δέντρα αποφάσεων με ενίσχυση κλίσης ή πλήρως συνδεδεμένα δίκτυα προώθησης τροφοδοσίας σε σύνολα δεδομένων συγκριτικής αξιολόγησης. Σε μια τυπική ρύθμιση ανίχνευσης απάτης, κατά τη διάρκεια της φάσης εκπαίδευσης, ένα μοντέλο GNN εκπαιδεύεται σε ένα σύνολο συναλλαγών με ετικέτα. Κάθε συναλλαγή εκπαίδευσης παρέχεται με μια δυαδική ετικέτα που δηλώνει εάν είναι δόλια. Αυτό το εκπαιδευμένο μοντέλο μπορεί στη συνέχεια να χρησιμοποιηθεί για τον εντοπισμό δόλιων συναλλαγών μεταξύ ενός συνόλου συναλλαγών χωρίς ετικέτα κατά τη διάρκεια της φάσης συμπερασμάτων. Υπάρχουν δύο διαφορετικοί τρόποι συμπερασμάτων: η μεταγωγική συμπέρασμα έναντι της επαγωγικής συναγωγής (για την οποία θα συζητήσουμε περισσότερα αργότερα σε αυτήν την ανάρτηση).
Τα μοντέλα που βασίζονται στο GNN, όπως το RGCN, μπορούν να επωφεληθούν από τοπολογικές πληροφορίες, συνδυάζοντας τόσο τη δομή του γραφήματος όσο και τα χαρακτηριστικά των κόμβων και των ακμών για να μάθουν μια ουσιαστική αναπαράσταση που διακρίνει τις κακόβουλες συναλλαγές από τις νόμιμες συναλλαγές. Το RGCN μπορεί να μάθει αποτελεσματικά να αναπαριστά διαφορετικούς τύπους κόμβων και ακμών (σχέσεις) μέσω ετερογενούς ενσωμάτωσης γραφημάτων. Στο προηγούμενο διάγραμμα, κάθε συναλλαγή μοντελοποιείται ως κόμβος στόχος και αρκετές οντότητες που σχετίζονται με κάθε συναλλαγή μοντελοποιούνται ως τύποι κόμβων μη στόχου, όπως ProductCD και P_emaildomain. Οι κόμβοι στόχοι έχουν αριθμητικά και κατηγορικά χαρακτηριστικά που έχουν εκχωρηθεί, ενώ άλλοι τύποι κόμβων είναι χωρίς χαρακτηριστικά. Το μοντέλο RGCN μαθαίνει μια ενσωμάτωση για κάθε τύπο κόμβου μη-στόχου. Για την ενσωμάτωση ενός κόμβου στόχου, χρησιμοποιείται μια συνελικτική λειτουργία για τον υπολογισμό της ενσωμάτωσής του χρησιμοποιώντας τα χαρακτηριστικά του και τις ενσωματώσεις γειτονιάς. Στο υπόλοιπο μέρος της ανάρτησης, χρησιμοποιούμε τους όρους GNN και RGCN εναλλακτικά.
Αξίζει να σημειωθεί ότι εναλλακτικές στρατηγικές, όπως η αντιμετώπιση των μη στοχευόμενων οντοτήτων ως χαρακτηριστικών και η απλή κωδικοποίησή τους, θα ήταν συχνά ανέφικτες λόγω των μεγάλων χαρακτηριστικών αυτών των οντοτήτων. Αντίθετα, η κωδικοποίησή τους ως οντότητες γραφήματος επιτρέπει στο μοντέλο GNN να επωφεληθεί από την άρρητη τοπολογία στις σχέσεις οντοτήτων. Για παράδειγμα, οι συναλλαγές που μοιράζονται έναν αριθμό τηλεφώνου με γνωστές δόλιες συναλλαγές είναι επίσης πιο πιθανό να είναι δόλιες.
Η αναπαράσταση γραφήματος που χρησιμοποιείται από τα GNN δημιουργεί κάποια πολυπλοκότητα στην υλοποίησή τους. Αυτό ισχύει ιδιαίτερα για εφαρμογές όπως η ανίχνευση απάτης, στις οποίες η αναπαράσταση γραφήματος μπορεί να επαυξηθεί κατά την εξαγωγή συμπερασμάτων με νεοπροστιθέμενους κόμβους που αντιστοιχούν σε οντότητες που δεν είναι γνωστές κατά την εκπαίδευση του μοντέλου. Αυτό το σενάριο συμπερασμάτων αναφέρεται συνήθως ως επαγωγική λειτουργία. Σε αντίθεση, μεταγωγική λειτουργία είναι ένα σενάριο που υποθέτει ότι η αναπαράσταση γραφήματος που κατασκευάστηκε κατά τη διάρκεια της εκπαίδευσης του μοντέλου δεν θα αλλάξει κατά την εξαγωγή συμπερασμάτων. Τα μοντέλα GNN αξιολογούνται συχνά σε μεταγωγική λειτουργία κατασκευάζοντας αναπαραστάσεις γραφημάτων από ένα συνδυασμένο σύνολο παραδειγμάτων εκπαίδευσης και δοκιμής, ενώ συγκαλύπτονται οι ετικέτες δοκιμής κατά τη διάρκεια της αντίστροφης διάδοσης. Αυτό διασφαλίζει ότι η αναπαράσταση του γραφήματος είναι στατική και εκεί το μοντέλο GNN δεν απαιτεί την υλοποίηση λειτουργιών για την επέκταση του γραφήματος με νέους κόμβους κατά τη διάρκεια της εξαγωγής συμπερασμάτων. Δυστυχώς, η στατική αναπαράσταση γραφήματος δεν μπορεί να υποτεθεί κατά τον εντοπισμό δόλιων συναλλαγών σε πραγματικές συνθήκες. Επομένως, απαιτείται υποστήριξη για επαγωγικά συμπεράσματα κατά την ανάπτυξη μοντέλων GNN για ανίχνευση απάτης σε περιβάλλοντα παραγωγής.
Επιπλέον, ο εντοπισμός δόλιων συναλλαγών σε πραγματικό χρόνο είναι ζωτικής σημασίας, ειδικά σε επιχειρηματικές περιπτώσεις όπου υπάρχει μόνο μία πιθανότητα να σταματήσουν οι παράνομες δραστηριότητες. Για παράδειγμα, οι δόλιες χρήστες μπορούν να συμπεριφέρονται κακόβουλα μόνο μία φορά με έναν λογαριασμό και να μην χρησιμοποιήσουν ποτέ ξανά τον ίδιο λογαριασμό. Το συμπέρασμα σε πραγματικό χρόνο σε μοντέλα GNN εισάγει πρόσθετη πολυπλοκότητα στην υλοποίηση. Συχνά είναι απαραίτητο να εφαρμοστούν λειτουργίες εξαγωγής υπογραφών για την υποστήριξη συμπερασμάτων σε πραγματικό χρόνο. Η λειτουργία εξαγωγής υπογραφήματος είναι απαραίτητη για τη μείωση της καθυστέρησης συμπερασμάτων όταν η αναπαράσταση γραφήματος είναι μεγάλη και η εκτέλεση συμπερασμάτων σε ολόκληρο το γράφημα γίνεται απαγορευτικά δαπανηρή. Ένας αλγόριθμος για επαγωγικό συμπέρασμα σε πραγματικό χρόνο με ένα μοντέλο RGCN εκτελείται ως εξής:
- Λαμβάνοντας υπόψη μια παρτίδα συναλλαγών και ένα εκπαιδευμένο μοντέλο RGCN, επεκτείνετε την αναπαράσταση γραφήματος με οντότητες από την παρτίδα.
- Αντιστοιχίστε διανύσματα ενσωμάτωσης νέων κόμβων μη-στόχων με το μέσο διάνυσμα ενσωμάτωσης του αντίστοιχου τύπου κόμβου τους.
- Εξαγωγή υπογράφου που προκαλείται από k-πήδηση έξω από τη γειτονιά των κόμβων-στόχων από την παρτίδα.
- Εκτελέστε συμπεράσματα στο υπογράφημα και επιστρέψτε βαθμολογίες πρόβλεψης για τους κόμβους-στόχους της παρτίδας.
- Καθαρίστε την αναπαράσταση του γραφήματος αφαιρώντας τους κόμβους που προστέθηκαν πρόσφατα (αυτό το βήμα διασφαλίζει ότι η απαίτηση μνήμης για την εξαγωγή συμπερασμάτων μοντέλου παραμένει σταθερή).
Η βασική συμβολή αυτής της ανάρτησης είναι να παρουσιάσει ένα μοντέλο RGCN που εφαρμόζει τον αλγόριθμο επαγωγικών συμπερασμάτων σε πραγματικό χρόνο. Μπορείτε να αναπτύξετε την εφαρμογή RGCN σε ένα τελικό σημείο του SageMaker ως λύση ανίχνευσης απάτης σε πραγματικό χρόνο. Η λύση μας δεν απαιτεί εξωτερική αποθήκευση γραφημάτων ή ενορχήστρωση και μειώνει σημαντικά το κόστος ανάπτυξης του μοντέλου RGCN για εργασίες ανίχνευσης απάτης. Το μοντέλο εφαρμόζει επίσης λειτουργία μεταγωγικού συμπερασματικού, επιτρέποντάς μας να διεξάγουμε πειράματα για να συγκρίνουμε την απόδοση του μοντέλου σε επαγωγικούς και μεταγωγικούς τρόπους. Ο κωδικός μοντέλου και τα σημειωματάρια με πειράματα είναι προσβάσιμα από το Παραδείγματα AWS αποθετήριο GitHub.
Αυτή η ανάρτηση βασίζεται στην ανάρτηση Δημιουργήστε μια λύση ανίχνευσης απάτης σε πραγματικό χρόνο που βασίζεται σε GNN χρησιμοποιώντας το Amazon SageMaker, το Amazon Neptune και τη Βιβλιοθήκη Deep Graph. Η προηγούμενη ανάρτηση δημιούργησε μια λύση ανίχνευσης απάτης σε πραγματικό χρόνο που βασίζεται σε RGCN χρησιμοποιώντας το SageMaker, Amazon Ποσειδώνας, και το Βιβλιοθήκη Deep Graph (DGL). Η προηγούμενη λύση χρησιμοποιούσε μια βάση δεδομένων Neptune ως εξωτερικό χώρο αποθήκευσης γραφημάτων, που απαιτείται AWS Lambda για ενορχήστρωση για συμπέρασμα σε πραγματικό χρόνο και περιελάμβανε μόνο πειράματα σε λειτουργία μεταγωγής.
Το μοντέλο RGCN που εισάγεται σε αυτήν την ανάρτηση υλοποιεί όλες τις λειτουργίες του αλγόριθμου επαγωγικών συμπερασμάτων σε πραγματικό χρόνο χρησιμοποιώντας μόνο το DGL ως εξάρτηση και δεν απαιτεί εξωτερική αποθήκευση γραφήματος ή ενορχήστρωση για την ανάπτυξη.
Αρχικά αξιολογούμε την απόδοση του μοντέλου RGCN σε μεταγωγικούς και επαγωγικούς τρόπους σε ένα σύνολο δεδομένων αναφοράς. Όπως ήταν αναμενόμενο, η απόδοση του μοντέλου στην επαγωγική λειτουργία είναι ελαφρώς χαμηλότερη από ό,τι στην επαγωγική λειτουργία. Μελετάμε επίσης την επίδραση της υπερπαραμέτρου k σχετικά με την απόδοση του μοντέλου. Η υπερπαράμετρος k ελέγχει τον αριθμό των αναπηδήσεων που εκτελούνται για την εξαγωγή ενός υπογράφου στο Βήμα 3 του αλγορίθμου συμπερασμάτων σε πραγματικό χρόνο. Υψηλότερες τιμές του k θα παράγει μεγαλύτερα υπογραφήματα και μπορεί να οδηγήσει σε καλύτερη απόδοση συμπερασμάτων σε βάρος της υψηλότερης καθυστέρησης. Ως εκ τούτου, διεξάγουμε επίσης πειράματα χρονισμού για να αξιολογήσουμε τη σκοπιμότητα του μοντέλου RGCN για μια εφαρμογή σε πραγματικό χρόνο.
Σύνολο δεδομένων
Χρησιμοποιούμε το Δεδομένα απάτης IEEE-CIS, το ίδιο σύνολο δεδομένων που χρησιμοποιήθηκε στο προηγούμενο θέση. Το σύνολο δεδομένων περιέχει πάνω από 590,000 εγγραφές συναλλαγών που έχουν μια δυαδική ετικέτα απάτης (η isFraud στήλη). Τα δεδομένα χωρίζονται σε δύο πίνακες: συναλλαγή και ταυτότητα. Ωστόσο, δεν έχουν όλα τα αρχεία συναλλαγών αντίστοιχες πληροφορίες ταυτότητας. Ενώνουμε τα δύο τραπέζια στο TransactionID στήλη, η οποία μας αφήνει συνολικά 144,233 εγγραφές συναλλαγών. Ταξινομούμε τον πίνακα κατά χρονική σήμανση συναλλαγής (το TransactionDT στήλη) και να δημιουργήσετε ένα ποσοστό 80/20 χωρισμένο ανά χρόνο, παράγοντας 115,386 και 28,847 συναλλαγές για εκπαίδευση και δοκιμή, αντίστοιχα.
Για περισσότερες λεπτομέρειες σχετικά με το σύνολο δεδομένων και πώς να το μορφοποιήσετε ώστε να ταιριάζει στην απαίτηση εισαγωγής του DGL, ανατρέξτε στο Εντοπισμός απάτης σε ετερογενή δίκτυα χρησιμοποιώντας το Amazon SageMaker και το Deep Graph Library.
Κατασκευή γραφήματος
Χρησιμοποιούμε το TransactionID στήλη για τη δημιουργία κόμβων-στόχων. Χρησιμοποιούμε τις ακόλουθες στήλες για να δημιουργήσουμε 11 τύπους μη στοχευόμενων κόμβων:
card1μέσωcard6ProductCDaddr1καιaddr2P_emaildomainκαιR_emaildomain
Χρησιμοποιούμε 38 στήλες ως κατηγορικά χαρακτηριστικά των κόμβων-στόχων:
M1μέσωM9DeviceTypeκαιDeviceInfoid_12μέσωid_38
Χρησιμοποιούμε 382 στήλες ως αριθμητικά χαρακτηριστικά των κόμβων-στόχων:
TransactionAmtdist1καιdist2id_01μέσωid_11C1μέσωC14D1μέσωD15V1μέσωV339
Το γράφημά μας που κατασκευάστηκε από τις συναλλαγές εκπαίδευσης περιέχει 217,935 κόμβους και 2,653,878 άκρες.
Υπερπαραμέτρους
Άλλες παράμετροι έχουν ρυθμιστεί να ταιριάζουν με τις παραμέτρους που αναφέρθηκαν στο προηγούμενο θέση. Το ακόλουθο απόσπασμα απεικονίζει την εκπαίδευση του μοντέλου RGCN σε μεταγωγικούς και επαγωγικούς τρόπους:
Επαγωγικός έναντι μεταγωγικού τρόπου
Εκτελούμε πέντε δοκιμές για επαγωγική και πέντε δοκιμές για μεταγωγική λειτουργία. Για κάθε δοκιμή, εκπαιδεύουμε ένα μοντέλο RGCN και το αποθηκεύουμε στο δίσκο, λαμβάνοντας 10 μοντέλα. Αξιολογούμε κάθε μοντέλο σε παραδείγματα δοκιμών ενώ αυξάνουμε τον αριθμό των άλματα (παράμετρος k) χρησιμοποιείται για την εξαγωγή ενός υπογράφου για συμπέρασμα, ρύθμιση k έως 1, 2 και 3. Προβλέπουμε σε όλα τα παραδείγματα δοκιμής ταυτόχρονα και υπολογίζουμε τη βαθμολογία ROC AUC για κάθε δοκιμή. Η ακόλουθη γραφική παράσταση δείχνει τη μέση τιμή και τα διαστήματα εμπιστοσύνης 95% των βαθμολογιών AUC.

Μπορούμε να δούμε ότι η απόδοση στη λειτουργία μεταγωγής είναι ελαφρώς υψηλότερη από την επαγωγική λειτουργία. Για k=2, οι μέσες βαθμολογίες AUC για επαγωγικούς και μεταγωγικούς τρόπους είναι 0.876 και 0.883, αντίστοιχα. Αυτό είναι αναμενόμενο επειδή το μοντέλο RGCN είναι σε θέση να μάθει ενσωματώσεις όλων των κόμβων οντοτήτων σε λειτουργία μεταγωγής, συμπεριλαμβανομένων εκείνων στο σύνολο δοκιμής. Αντίθετα, η επαγωγική λειτουργία επιτρέπει στο μοντέλο να μαθαίνει μόνο τις ενσωματώσεις κόμβων οντοτήτων που υπάρχουν στα παραδείγματα εκπαίδευσης και επομένως ορισμένοι κόμβοι πρέπει να συμπληρώνονται με μέσο όρο κατά τη διάρκεια της εξαγωγής συμπερασμάτων. Ταυτόχρονα, η πτώση της απόδοσης μεταξύ μεταγωγικών και επαγωγικών τρόπων λειτουργίας δεν είναι σημαντική και ακόμη και σε επαγωγική λειτουργία, το μοντέλο RGCN επιτυγχάνει καλή απόδοση με AUC 0.876. Παρατηρούμε επίσης ότι η απόδοση του μοντέλου δεν βελτιώνεται για τις τιμές του k>2. Αυτό σημαίνει ότι η ρύθμιση kΤο =2 θα εξήγαγε ένα αρκετά μεγάλο υπογράφημα κατά την εξαγωγή συμπερασμάτων, με αποτέλεσμα τη βέλτιστη απόδοση. Αυτή η παρατήρηση επιβεβαιώνεται και από το επόμενο πείραμά μας.
Αξίζει επίσης να σημειωθεί ότι, για τη λειτουργία μεταγωγής, η AUC του μοντέλου μας 0.883 είναι υψηλότερη από την αντίστοιχη AUC των 0.870 που αναφέρθηκε στο προηγούμενο θέση. Χρησιμοποιούμε περισσότερες στήλες ως αριθμητικά και κατηγορικά χαρακτηριστικά των κόμβων-στόχων, γεγονός που μπορεί να εξηγήσει την υψηλότερη βαθμολογία AUC. Σημειώνουμε επίσης ότι τα πειράματα στην προηγούμενη ανάρτηση πραγματοποίησαν μόνο μία δοκιμή.
Συμπεράσματα για μια μικρή παρτίδα
Για αυτό το πείραμα, αξιολογούμε το μοντέλο RGCN σε μια ρύθμιση συμπερασμάτων μικρής παρτίδας. Χρησιμοποιούμε πέντε μοντέλα που είχαν εκπαιδευτεί σε επαγωγική λειτουργία στο προηγούμενο πείραμα. Συγκρίνουμε την απόδοση αυτών των μοντέλων κατά την πρόβλεψη σε δύο ρυθμίσεις: συμπέρασμα πλήρους και μικρής παρτίδας. Για πλήρη συμπεράσματα παρτίδας, προβλέπουμε σε ολόκληρο το δοκιμαστικό σύνολο, όπως έγινε στο προηγούμενο πείραμα. Για συμπέρασμα μικρής παρτίδας, προβλέπουμε σε μικρές παρτίδες διαιρώντας το δοκιμαστικό σύνολο σε 28 παρτίδες ίσου μεγέθους με περίπου 1,000 συναλλαγές σε κάθε παρτίδα. Υπολογίζουμε τις βαθμολογίες AUC και για τις δύο ρυθμίσεις χρησιμοποιώντας διαφορετικές τιμές του k. Η ακόλουθη γραφική παράσταση δείχνει τον μέσο όρο και τα διαστήματα εμπιστοσύνης 95% για ρυθμίσεις συμπερασμάτων πλήρους και μικρής παρτίδας.

Παρατηρούμε ότι η απόδοση για συμπέρασμα μικρής παρτίδας όταν kΤο =1 είναι χαμηλότερο από ό,τι για την πλήρη παρτίδα. Ωστόσο, η απόδοση συμπερασμάτων μικρής παρτίδας ταιριάζει με την πλήρη παρτίδα όταν k>1. Αυτό μπορεί να αποδοθεί σε πολύ μικρότερα υπογραφήματα που εξάγονται για μικρές παρτίδες. Το επιβεβαιώνουμε συγκρίνοντας μεγέθη υπογραφών με το μέγεθος ολόκληρου του γραφήματος που δημιουργήθηκε από τις συναλλαγές εκπαίδευσης. Συγκρίνουμε μεγέθη γραφημάτων ως προς τον αριθμό των κόμβων. Για k=1, το μέσο μέγεθος υπογραφήματος για συμπέρασμα μικρής παρτίδας είναι μικρότερο από το 2% του γραφήματος εκπαίδευσης. Και για πλήρη συμπέρασμα παρτίδας όταν k=1, το μέγεθος υπογραφήματος είναι 22%. Οταν k=2, τα μεγέθη υπογραφών για συμπέρασμα μικρής και πλήρους παρτίδας είναι 54% και 64%, αντίστοιχα. Τέλος, τα μεγέθη υπογραφημάτων και για τις δύο ρυθμίσεις συμπερασμάτων φτάνουν το 100% για k=3. Με άλλα λόγια, όταν k>1, το υπογράφημα για μια μικρή παρτίδα γίνεται αρκετά μεγάλο, επιτρέποντας το συμπέρασμα για μικρές παρτίδες να φτάσει την ίδια απόδοση με το συμπέρασμα πλήρους παρτίδας.
Καταγράφουμε επίσης την καθυστέρηση πρόβλεψης για κάθε παρτίδα. Εκτελούμε τα πειράματά μας σε ένα στιγμιότυπο ml.r5.12xlarge, αλλά μπορείτε να χρησιμοποιήσετε ένα μικρότερο στιγμιότυπο με μνήμη 64 G για να εκτελέσετε τα ίδια πειράματα. Η ακόλουθη γραφική παράσταση δείχνει τον μέσο όρο και τα διαστήματα εμπιστοσύνης 95% των καθυστερήσεων πρόβλεψης μικρών παρτίδων για διαφορετικές τιμές k.
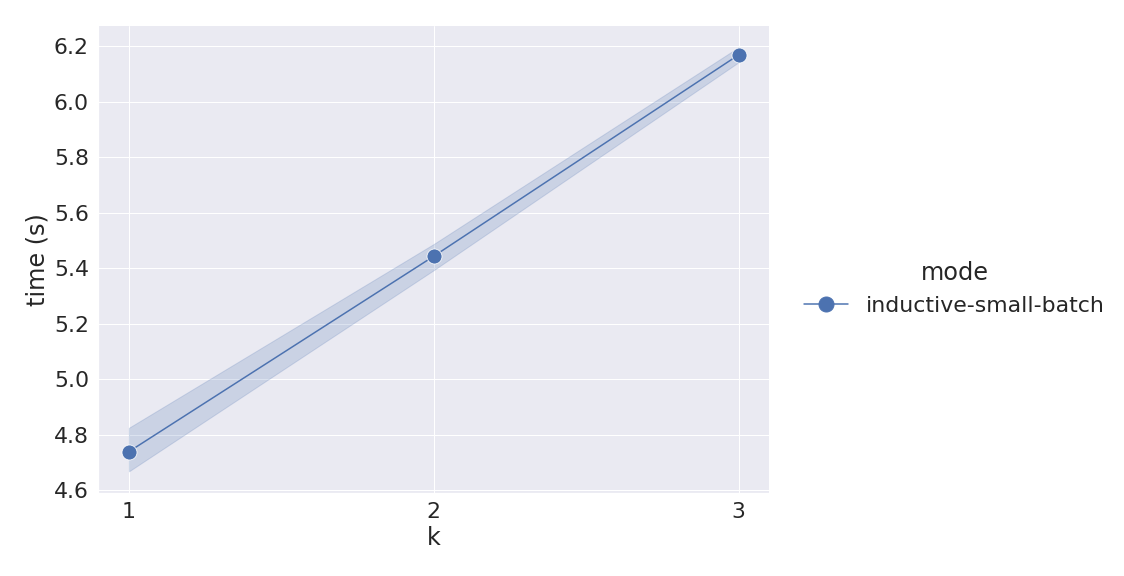
Η καθυστέρηση περιλαμβάνει και τα πέντε βήματα του αλγορίθμου επαγωγικών συμπερασμάτων σε πραγματικό χρόνο. Το βλέπουμε όταν k=2, η πρόβλεψη για 1,030 συναλλαγές διαρκεί 5.4 δευτερόλεπτα κατά μέσο όρο, με αποτέλεσμα την παροχή 190 συναλλαγών ανά δευτερόλεπτο. Αυτό επιβεβαιώνει ότι η υλοποίηση του μοντέλου RGCN είναι κατάλληλη για ανίχνευση απάτης σε πραγματικό χρόνο. Σημειώνουμε επίσης ότι το προηγούμενο θέση δεν παρείχαν σκληρές τιμές καθυστέρησης για την υλοποίησή τους.
Συμπέρασμα
Το μοντέλο RGCN που κυκλοφόρησε με αυτήν την ανάρτηση υλοποιεί τον αλγόριθμο για επαγωγικά συμπεράσματα σε πραγματικό χρόνο και δεν απαιτεί εξωτερική αποθήκευση γραφημάτων ή ενορχήστρωση. Η παράμετρος k στο Βήμα 3 του αλγορίθμου καθορίζει τον αριθμό των αναπηδήσεων που εκτελούνται για την εξαγωγή του υπογράφου για συμπέρασμα και καταλήγει σε μια αντιστάθμιση μεταξύ της ακρίβειας του μοντέλου και της καθυστέρησης πρόβλεψης. Χρησιμοποιήσαμε το Δεδομένα απάτης IEEE-CIS στα πειράματά μας και επικυρώθηκε εμπειρικά ότι η βέλτιστη τιμή της παραμέτρου k για αυτό το σύνολο δεδομένων είναι 2, επιτυγχάνοντας βαθμολογία AUC 0.876 και καθυστέρηση πρόβλεψης μικρότερη από 6 δευτερόλεπτα ανά 1,000 συναλλαγές.
Αυτή η ανάρτηση παρείχε μια διαδικασία βήμα προς βήμα για την εκπαίδευση και την αξιολόγηση ενός μοντέλου RGCN για ανίχνευση απάτης σε πραγματικό χρόνο. Η συμπεριλαμβανόμενη κλάση μοντέλων εφαρμόζει μεθόδους για ολόκληρο τον κύκλο ζωής του μοντέλου, συμπεριλαμβανομένων μεθόδων σειριοποίησης και αποσειριοποίησης. Αυτό επιτρέπει στο μοντέλο να χρησιμοποιηθεί για ανίχνευση απάτης σε πραγματικό χρόνο. Μπορείτε να εκπαιδεύσετε το μοντέλο ως εκτιμητή PyTorch SageMaker και στη συνέχεια να το αναπτύξετε σε ένα τελικό σημείο του SageMaker χρησιμοποιώντας τα ακόλουθα σημειωματάριο ως πρότυπο. Το τελικό σημείο είναι σε θέση να προβλέψει την απάτη σε μικρές παρτίδες ακατέργαστων συναλλαγών σε πραγματικό χρόνο. Μπορείτε επίσης να χρησιμοποιήσετε Amazon SageMaker Inference Recommender για να επιλέξετε τον καλύτερο τύπο παρουσίας και τη διαμόρφωση για το τελικό σημείο συμπερασμάτων με βάση τον φόρτο εργασίας σας.
Για περισσότερες πληροφορίες σχετικά με αυτό το θέμα και την εφαρμογή, σας ενθαρρύνουμε να εξερευνήσετε και να δοκιμάσετε μόνοι σας τα σενάρια μας. Μπορείτε να αποκτήσετε πρόσβαση στα σημειωματάρια και τον σχετικό κωδικό κατηγορίας μοντέλου από το Παραδείγματα AWS αποθετήριο GitHub.
Σχετικά με τους Συγγραφείς
 Ντμίτρι Μπεσπάλοφ είναι Ανώτερος Εφαρμοσμένος Επιστήμονας στο Amazon Machine Learning Solutions Lab, όπου βοηθά τους πελάτες του AWS σε διαφορετικούς κλάδους να επιταχύνουν την υιοθέτηση της τεχνητής νοημοσύνης και του cloud.
Ντμίτρι Μπεσπάλοφ είναι Ανώτερος Εφαρμοσμένος Επιστήμονας στο Amazon Machine Learning Solutions Lab, όπου βοηθά τους πελάτες του AWS σε διαφορετικούς κλάδους να επιταχύνουν την υιοθέτηση της τεχνητής νοημοσύνης και του cloud.
 Μάρκα Ryan είναι Εφαρμοσμένος Επιστήμονας στο Amazon Machine Learning Solutions Lab. Έχει ειδική εμπειρία στην εφαρμογή της μηχανικής μάθησης σε προβλήματα στον τομέα της υγείας και των επιστημών της ζωής. Στον ελεύθερο χρόνο του, του αρέσει να διαβάζει ιστορία και επιστημονική φαντασία.
Μάρκα Ryan είναι Εφαρμοσμένος Επιστήμονας στο Amazon Machine Learning Solutions Lab. Έχει ειδική εμπειρία στην εφαρμογή της μηχανικής μάθησης σε προβλήματα στον τομέα της υγείας και των επιστημών της ζωής. Στον ελεύθερο χρόνο του, του αρέσει να διαβάζει ιστορία και επιστημονική φαντασία.
 Yanjun Qi είναι Senior Applied Science Manager στο Amazon Machine Learning Solution Lab. Καινοτομεί και εφαρμόζει μηχανική εκμάθηση για να βοηθήσει τους πελάτες του AWS να επιταχύνουν την υιοθέτηση της τεχνητής νοημοσύνης και του cloud.
Yanjun Qi είναι Senior Applied Science Manager στο Amazon Machine Learning Solution Lab. Καινοτομεί και εφαρμόζει μηχανική εκμάθηση για να βοηθήσει τους πελάτες του AWS να επιταχύνουν την υιοθέτηση της τεχνητής νοημοσύνης και του cloud.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- Platoblockchain. Web3 Metaverse Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/machine-learning/build-a-gnn-based-real-time-fraud-detection-solution-using-the-deep-graph-library-without-using-external-graph-storage/

