Η δομημένη γλώσσα ερωτημάτων (SQL) είναι μια πολύπλοκη γλώσσα που απαιτεί κατανόηση των βάσεων δεδομένων και των μεταδεδομένων. Σήμερα, γενετική AI μπορεί να ενεργοποιήσει άτομα χωρίς γνώση SQL. Αυτή η γενετική εργασία AI ονομάζεται text-to-SQL, η οποία δημιουργεί ερωτήματα SQL από την επεξεργασία φυσικής γλώσσας (NLP) και μετατρέπει το κείμενο σε σημασιολογικά σωστό SQL. Η λύση σε αυτήν την ανάρτηση στοχεύει να φέρει τις λειτουργίες εταιρικών αναλυτικών στοιχείων στο επόμενο επίπεδο συντομεύοντας τη διαδρομή προς τα δεδομένα σας χρησιμοποιώντας φυσική γλώσσα.
Με την εμφάνιση μεγάλων γλωσσικών μοντέλων (LLMs), η παραγωγή SQL που βασίζεται σε NLP έχει υποστεί σημαντικό μετασχηματισμό. Επιδεικνύοντας εξαιρετική απόδοση, τα LLM είναι πλέον σε θέση να δημιουργούν ακριβή ερωτήματα SQL από περιγραφές φυσικής γλώσσας. Ωστόσο, εξακολουθούν να υπάρχουν προκλήσεις. Πρώτον, η ανθρώπινη γλώσσα είναι εγγενώς διφορούμενη και εξαρτάται από το πλαίσιο, ενώ η SQL είναι ακριβής, μαθηματική και δομημένη. Αυτό το κενό μπορεί να οδηγήσει σε ανακριβή μετατροπή των αναγκών του χρήστη στο SQL που δημιουργείται. Δεύτερον, μπορεί να χρειαστεί να δημιουργήσετε λειτουργίες κειμένου σε SQL για κάθε βάση δεδομένων, επειδή τα δεδομένα συχνά δεν αποθηκεύονται σε έναν μόνο στόχο. Ίσως χρειαστεί να αναδημιουργήσετε τη δυνατότητα για κάθε βάση δεδομένων για να ενεργοποιήσετε τους χρήστες με δημιουργία SQL που βασίζεται σε NLP. Τρίτον, παρά τη μεγαλύτερη υιοθέτηση λύσεων κεντρικών αναλυτικών στοιχείων, όπως λίμνες δεδομένων και αποθήκες, η πολυπλοκότητα αυξάνεται με διαφορετικά ονόματα πινάκων και άλλα μεταδεδομένα που απαιτούνται για τη δημιουργία της SQL για τις επιθυμητές πηγές. Ως εκ τούτου, η συλλογή περιεκτικών και υψηλής ποιότητας μεταδεδομένων παραμένει επίσης μια πρόκληση. Για να μάθετε περισσότερα σχετικά με τις βέλτιστες πρακτικές μετατροπής κειμένου σε SQL και τα μοτίβα σχεδίασης, βλ Δημιουργία αξίας από εταιρικά δεδομένα: Βέλτιστες πρακτικές για το Text2SQL και τη γενετική τεχνητή νοημοσύνη.
Η λύση μας στοχεύει στην αντιμετώπιση αυτών των προκλήσεων χρησιμοποιώντας Θεμέλιο του Αμαζονίου και Υπηρεσίες AWS Analytics. Χρησιμοποιούμε Anthropic Claude v2.1 στο Amazon Bedrock ως το LLM μας. Για την αντιμετώπιση των προκλήσεων, η λύση μας ενσωματώνει πρώτα τα μεταδεδομένα των πηγών δεδομένων εντός του Κατάλογος δεδομένων κόλλας AWS για να αυξήσετε την ακρίβεια του παραγόμενου ερωτήματος SQL. Η ροή εργασίας περιλαμβάνει επίσης έναν βρόχο τελικής αξιολόγησης και διόρθωσης, σε περίπτωση που εντοπιστούν τυχόν ζητήματα SQL Αμαζόν Αθηνά, το οποίο χρησιμοποιείται κατάντη ως η μηχανή SQL. Η Αθηνά μας επιτρέπει επίσης να χρησιμοποιήσουμε ένα πλήθος από υποστηριζόμενα τελικά σημεία και συνδέσεις για να καλύψει ένα μεγάλο σύνολο πηγών δεδομένων.
Αφού ακολουθήσουμε τα βήματα για τη δημιουργία της λύσης, παρουσιάζουμε τα αποτελέσματα ορισμένων σεναρίων δοκιμών με διαφορετικά επίπεδα πολυπλοκότητας SQL. Τέλος, συζητάμε πώς είναι απλό να ενσωματώνετε διαφορετικές πηγές δεδομένων στα ερωτήματά σας SQL.
Επισκόπηση λύσεων
Υπάρχουν τρία κρίσιμα στοιχεία στην αρχιτεκτονική μας: Ανάκτηση Augmented Generation (RAG) με μεταδεδομένα βάσης δεδομένων, βρόχος αυτοδιόρθωσης πολλών βημάτων και Athena ως μηχανή SQL.
Χρησιμοποιούμε τη μέθοδο RAG για να ανακτήσουμε τις περιγραφές πινάκων και τις περιγραφές σχημάτων (στήλες) από το μετακατάστημα AWS Glue για να διασφαλίσουμε ότι το αίτημα σχετίζεται με τον σωστό πίνακα και τα σωστά σύνολα δεδομένων. Στη λύση μας, δημιουργήσαμε τα επιμέρους βήματα για την εκτέλεση ενός πλαισίου RAG με τον Κατάλογο δεδομένων κόλλας AWS για σκοπούς επίδειξης. Ωστόσο, μπορείτε επίσης να χρησιμοποιήσετε βάσεις γνώσεων στο Amazon Bedrock για να δημιουργήσετε γρήγορα λύσεις RAG.
Το στοιχείο πολλαπλών βημάτων επιτρέπει στο LLM να διορθώσει το ερώτημα SQL που δημιουργήθηκε για ακρίβεια. Εδώ, η SQL που δημιουργείται αποστέλλεται για συντακτικά σφάλματα. Χρησιμοποιούμε μηνύματα σφάλματος Athena για να εμπλουτίσουμε την προτροπή μας για το LLM για πιο ακριβείς και αποτελεσματικές διορθώσεις στο SQL που δημιουργήθηκε.
Μπορείτε να εξετάσετε τα μηνύματα σφάλματος που προέρχονται περιστασιακά από την Athena σαν σχόλια. Οι επιπτώσεις στο κόστος ενός βήματος διόρθωσης σφάλματος είναι αμελητέες σε σύγκριση με την τιμή που παραδόθηκε. Μπορείτε ακόμη να συμπεριλάβετε αυτά τα διορθωτικά βήματα ως εποπτευόμενα ενισχυμένα παραδείγματα εκμάθησης για να βελτιώσετε τα LLM σας. Ωστόσο, δεν καλύψαμε αυτή τη ροή στην ανάρτησή μας για λόγους απλότητας.
Λάβετε υπόψη ότι υπάρχει πάντα εγγενής κίνδυνος να υπάρχουν ανακρίβειες, κάτι που φυσικά συνοδεύεται από λύσεις τεχνητής νοημοσύνης. Ακόμα κι αν τα μηνύματα σφάλματος Athena είναι πολύ αποτελεσματικά για τον μετριασμό αυτού του κινδύνου, μπορείτε να προσθέσετε περισσότερα στοιχεία ελέγχου και προβολές, όπως ανθρώπινη ανάδραση ή παραδείγματα ερωτημάτων για λεπτομέρεια, για να ελαχιστοποιήσετε περαιτέρω αυτούς τους κινδύνους.
Το Athena όχι μόνο μας επιτρέπει να διορθώσουμε τα ερωτήματα SQL, αλλά επίσης απλοποιεί το συνολικό πρόβλημα για εμάς, επειδή λειτουργεί ως ο κόμβος, όπου οι ακτίνες είναι πολλαπλές πηγές δεδομένων. Η διαχείριση της πρόσβασης, η σύνταξη SQL και πολλά άλλα γίνονται μέσω του Athena.
Το παρακάτω διάγραμμα απεικονίζει την αρχιτεκτονική λύσεων.
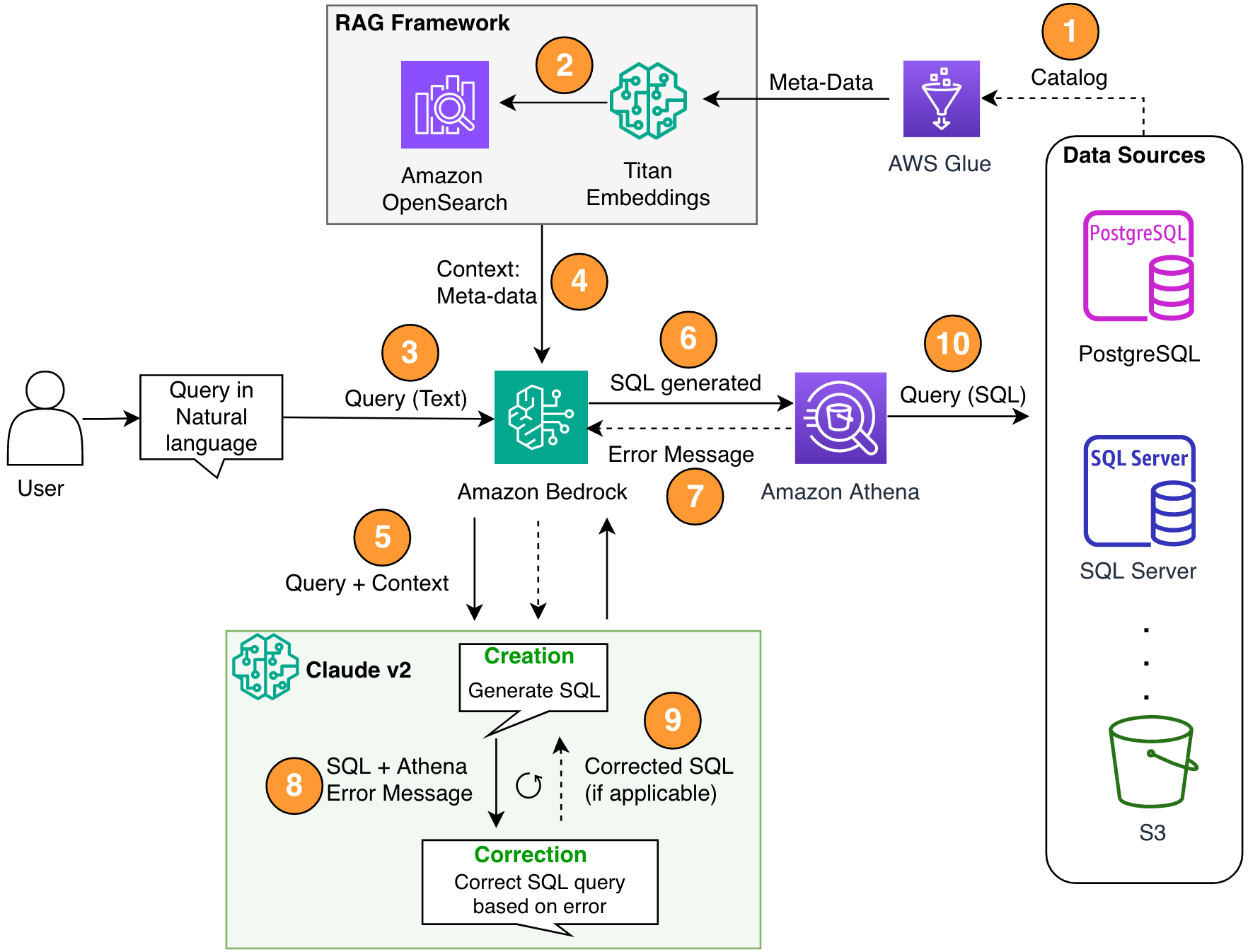
Εικόνα 1. Η αρχιτεκτονική λύση και η ροή της διαδικασίας.
Η ροή της διαδικασίας περιλαμβάνει τα ακόλουθα βήματα:
- Δημιουργήστε τον κατάλογο δεδομένων κόλλας AWS χρησιμοποιώντας έναν ανιχνευτή AWS Glue (ή διαφορετική μέθοδο).
- Χρήση του Μοντέλο Titan-Text-Embeddings στο Amazon Bedrock, μετατρέψτε τα μεταδεδομένα σε ενσωματώσεις και αποθηκεύστε τα σε ένα Amazon OpenSearch χωρίς διακομιστή κατάστημα διάνυσμα, το οποίο χρησιμεύει ως βάση γνώσεων στο πλαίσιο RAG μας.
Σε αυτό το στάδιο, η διαδικασία είναι έτοιμη να λάβει το ερώτημα σε φυσική γλώσσα. Τα βήματα 7-9 αντιπροσωπεύουν έναν βρόχο διόρθωσης, εάν υπάρχει.
- Ο χρήστης εισάγει το ερώτημά του σε φυσική γλώσσα. Μπορείτε να χρησιμοποιήσετε οποιαδήποτε εφαρμογή Ιστού για να παρέχετε τη διεπαφή χρήστη συνομιλίας. Επομένως, δεν καλύψαμε τις λεπτομέρειες της διεπαφής χρήστη στην ανάρτησή μας.
- Η λύση εφαρμόζει ένα πλαίσιο RAG μέσω αναζήτηση ομοιότητας, το οποίο προσθέτει το επιπλέον πλαίσιο από τα μεταδεδομένα από τη διανυσματική βάση δεδομένων. Αυτός ο πίνακας χρησιμοποιείται για την εύρεση του σωστού πίνακα, βάσης δεδομένων και χαρακτηριστικών.
- Το ερώτημα συγχωνεύεται με το περιβάλλον και αποστέλλεται στο Anthropic Claude v2.1 στο Amazon Bedrock.
- Το μοντέλο λαμβάνει το ερώτημα SQL που δημιουργήθηκε και συνδέεται με το Athena για να επικυρώσει τη σύνταξη.
- Εάν το Athena παρέχει ένα μήνυμα σφάλματος που αναφέρει ότι η σύνταξη είναι λανθασμένη, το μοντέλο χρησιμοποιεί το κείμενο σφάλματος από την απάντηση του Athena.
- Η νέα προτροπή προσθέτει την απάντηση της Αθηνάς.
- Το μοντέλο δημιουργεί τη διορθωμένη SQL και συνεχίζει τη διαδικασία. Αυτή η επανάληψη μπορεί να πραγματοποιηθεί πολλές φορές.
- Τέλος, εκτελούμε την SQL χρησιμοποιώντας το Athena και παράγουμε έξοδο. Εδώ, η έξοδος παρουσιάζεται στον χρήστη. Για λόγους αρχιτεκτονικής απλότητας, δεν δείξαμε αυτό το βήμα.
Προϋποθέσεις
Για αυτήν την ανάρτηση, θα πρέπει να συμπληρώσετε τις ακόλουθες προϋποθέσεις:
- έχουν ένα Λογαριασμός AWS.
- εγκαταστήστε ο Διεπαφή γραμμής εντολών AWS (AWS CLI).
- Ρυθμίστε το SDK για Python (Boto3).
- Δημιουργήστε τον κατάλογο δεδομένων κόλλας AWS χρησιμοποιώντας έναν ανιχνευτή AWS Glue (ή διαφορετική μέθοδο).
- Χρήση του Μοντέλο Titan-Text-Embeddings στο Amazon Bedrock, μετατρέψτε τα μεταδεδομένα σε ενσωματώσεις και αποθηκεύστε τα σε έναν OpenSearch Serverless κατάστημα διάνυσμα.
Εφαρμόστε τη λύση
Μπορείτε να χρησιμοποιήσετε τα παρακάτω Σημειωματάριο Jupyter, το οποίο περιλαμβάνει όλα τα αποσπάσματα κώδικα που παρέχονται σε αυτήν την ενότητα, για τη δημιουργία της λύσης. Συνιστούμε τη χρήση Στούντιο Amazon SageMaker για να ανοίξετε αυτό το σημειωματάριο με μια παρουσία ml.t3.medium με τον πυρήνα Python 3 (Data Science). Για οδηγίες, ανατρέξτε στο Εκπαιδεύστε ένα μοντέλο μηχανικής μάθησης. Ολοκληρώστε τα παρακάτω βήματα για να ρυθμίσετε τη λύση:
- Δημιουργήστε τη βάση γνώσεων στην υπηρεσία OpenSearch για το πλαίσιο RAG:
- Δημιουργήστε την προτροπή (
final_question) συνδυάζοντας την είσοδο του χρήστη σε φυσική γλώσσα (user_query), τα σχετικά μεταδεδομένα από το vector store (vector_search_match), και τις οδηγίες μας (details): - Επικαλέστε το Amazon Bedrock για το LLM (Claude v2) και ζητήστε του να δημιουργήσει το ερώτημα SQL. Στον παρακάτω κώδικα, κάνει πολλές προσπάθειες για να απεικονίσει το βήμα αυτοδιόρθωσης:x
- Εάν ληφθούν τυχόν ζητήματα με το ερώτημα SQL που δημιουργήθηκε (
{sqlgenerated}) από την απάντηση της Αθηνάς ({syntaxcheckmsg}), η νέα προτροπή (prompt) δημιουργείται με βάση την απόκριση και το μοντέλο προσπαθεί ξανά να δημιουργήσει τη νέα SQL: - Αφού δημιουργηθεί η SQL, ο πελάτης Athena καλείται για να τρέξει και να δημιουργήσει την έξοδο:
Δοκιμάστε τη λύση
Σε αυτήν την ενότητα, εκτελούμε τη λύση μας με διαφορετικά παραδείγματα σεναρίων για να ελέγξουμε διαφορετικά επίπεδα πολυπλοκότητας των ερωτημάτων SQL.
Για να δοκιμάσουμε το text-to-SQL, χρησιμοποιούμε δύο σύνολα δεδομένων διαθέσιμα από το IMDB. Υποσύνολα δεδομένων IMDb είναι διαθέσιμα για προσωπική και μη εμπορική χρήση. Μπορείτε να κατεβάσετε τα σύνολα δεδομένων και να τα αποθηκεύσετε Απλή υπηρεσία αποθήκευσης Amazon (Amazon S3). Μπορείτε να χρησιμοποιήσετε το ακόλουθο απόσπασμα Spark SQL για να δημιουργήσετε πίνακες στο AWS Glue. Για αυτό το παράδειγμα χρησιμοποιούμε title_ratings και title:
Αποθηκεύστε δεδομένα στο Amazon S3 και μεταδεδομένα στο AWS Glue
Σε αυτό το σενάριο, το σύνολο δεδομένων μας αποθηκεύεται σε έναν κάδο S3. Το Athena διαθέτει μια υποδοχή S3 που σας επιτρέπει να χρησιμοποιείτε το Amazon S3 ως πηγή δεδομένων που μπορείτε να αναζητήσετε.
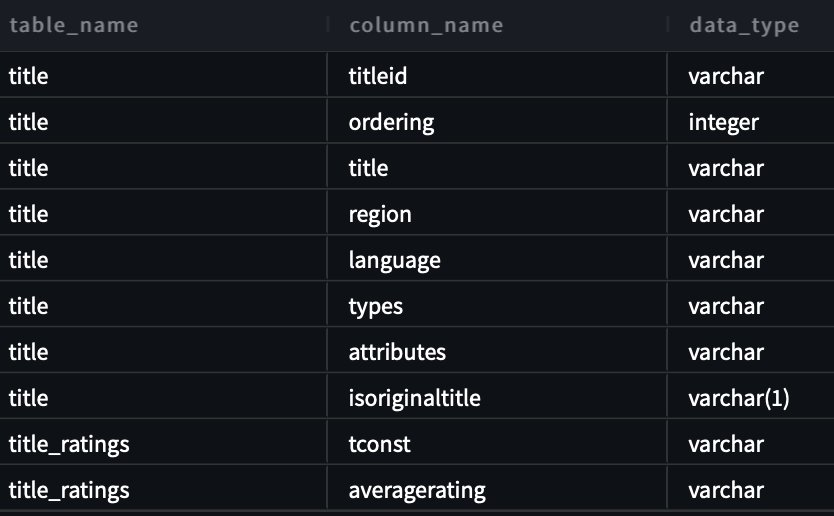
Για το πρώτο μας ερώτημα, παρέχουμε την εισαγωγή "Είμαι νέος σε αυτό. Μπορείτε να με βοηθήσετε να δω όλους τους πίνακες και τις στήλες στο σχήμα imdb;»
Το παρακάτω είναι το ερώτημα που δημιουργήθηκε:
Το παρακάτω στιγμιότυπο οθόνης και ο κώδικας δείχνουν την έξοδο μας.
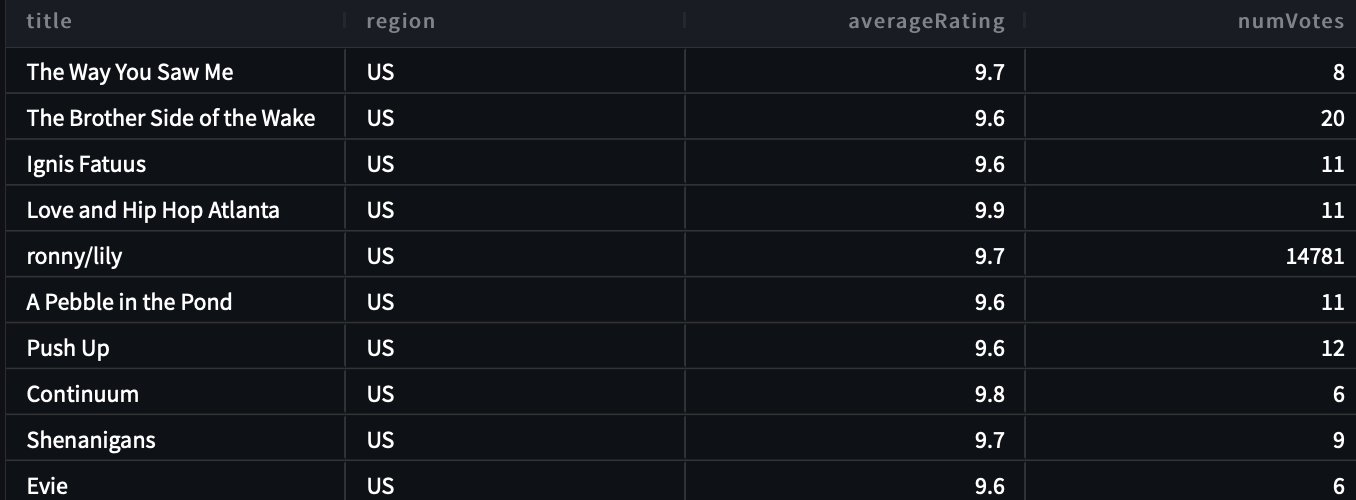
Για το δεύτερο ερώτημά μας, ρωτάμε "Δείξε μου όλους τους τίτλους και τις λεπτομέρειες στην περιοχή των ΗΠΑ της οποίας η βαθμολογία είναι μεγαλύτερη από 9.5".
Το παρακάτω είναι το ερώτημά μας που δημιουργήθηκε:
Η απάντηση είναι η εξής.
Για το τρίτο ερώτημά μας, εισάγουμε "Great Response! Δείξτε μου τώρα όλους τους πρωτότυπους τίτλους με βαθμολογίες πάνω από 7.5 και όχι στην περιοχή των ΗΠΑ.»
Δημιουργείται το ακόλουθο ερώτημα:
Παίρνουμε τα ακόλουθα αποτελέσματα.

Δημιουργία αυτοδιορθωμένης SQL
Αυτό το σενάριο προσομοιώνει ένα ερώτημα SQL που έχει προβλήματα σύνταξης. Εδώ, η SQL που δημιουργείται θα διορθωθεί μόνος του με βάση την απάντηση από την Athena. Στην παρακάτω απάντηση, η Αθηνά έδωσε α COLUMN_NOT_FOUND λάθος και ανέφερε ότι table_description δεν μπορεί να επιλυθεί:
Χρήση της λύσης με άλλες πηγές δεδομένων
Για να χρησιμοποιήσετε τη λύση με άλλες πηγές δεδομένων, η Athena χειρίζεται τη δουλειά για εσάς. Για να γίνει αυτό, η Αθηνά χρησιμοποιεί συνδέσεις πηγής δεδομένων που μπορεί να χρησιμοποιηθεί με ομοσπονδιακά ερωτήματα. Μπορείτε να θεωρήσετε έναν σύνδεσμο ως επέκταση του μηχανισμού αναζήτησης Athena. Υπάρχουν προ-ενσωματωμένες συνδέσεις πηγών δεδομένων Athena για πηγές δεδομένων όπως Αρχεία καταγραφής CloudWatch του Amazon, Amazon DynamoDB, Amazon DocumentDB (με συμβατότητα MongoDB), να Υπηρεσία σχεσιακής βάσης δεδομένων Amazon (Amazon RDS) και συμβατές με JDBC πηγές σχεσιακών δεδομένων όπως η MySQL και η PostgreSQL υπό την άδεια Apache 2.0. Αφού δημιουργήσετε μια σύνδεση με οποιαδήποτε πηγή δεδομένων, μπορείτε να χρησιμοποιήσετε την προηγούμενη βάση κώδικα για να επεκτείνετε τη λύση. Για περισσότερες πληροφορίες, ανατρέξτε στο Αναζητήστε οποιαδήποτε πηγή δεδομένων με το νέο ομοσπονδιακό ερώτημα της Amazon Athena.
εκκαθάριση
Για να καθαρίσετε τους πόρους, μπορείτε να ξεκινήσετε καθαρίζοντας τον κάδο S3 σας όπου βρίσκονται τα δεδομένα. Εκτός εάν η εφαρμογή σας επικαλείται το Amazon Bedrock, δεν θα επιβαρυνθεί με κανένα κόστος. Για λόγους βέλτιστων πρακτικών διαχείρισης υποδομής, συνιστούμε τη διαγραφή των πόρων που δημιουργήθηκαν σε αυτήν την επίδειξη.
Συμπέρασμα
Σε αυτήν την ανάρτηση, παρουσιάσαμε μια λύση που σας επιτρέπει να χρησιμοποιείτε το NLP για τη δημιουργία σύνθετων ερωτημάτων SQL με διάφορους πόρους που ενεργοποιούνται από την Athena. Αυξήσαμε επίσης την ακρίβεια των δημιουργούμενων ερωτημάτων SQL μέσω ενός βρόχου αξιολόγησης πολλαπλών βημάτων που βασίζεται σε μηνύματα λάθους από μεταγενέστερες διαδικασίες. Επιπλέον, χρησιμοποιήσαμε τα μεταδεδομένα στον κατάλογο δεδομένων AWS Glue για να εξετάσουμε τα ονόματα των πινάκων που ζητήθηκαν στο ερώτημα μέσω του πλαισίου RAG. Στη συνέχεια δοκιμάσαμε τη λύση σε διάφορα ρεαλιστικά σενάρια με διαφορετικά επίπεδα πολυπλοκότητας ερωτημάτων. Τέλος, συζητήσαμε πώς να εφαρμόσουμε αυτήν τη λύση σε διαφορετικές πηγές δεδομένων που υποστηρίζονται από την Athena.
Το Amazon Bedrock βρίσκεται στο επίκεντρο αυτής της λύσης. Το Amazon Bedrock μπορεί να σας βοηθήσει να δημιουργήσετε πολλές παραγωγικές εφαρμογές AI. Για να ξεκινήσετε με το Amazon Bedrock, συνιστούμε να ακολουθήσετε τη γρήγορη εκκίνηση στα παρακάτω GitHub repo και εξοικείωση με τη δημιουργία εφαρμογών τεχνητής νοημοσύνης. Μπορείτε επίσης να δοκιμάσετε βάσεις γνώσεων στο Amazon Bedrock για να δημιουργήσετε γρήγορα τέτοιες λύσεις RAG.
Σχετικά με τους Συγγραφείς
 Sanjeeb Panda είναι μηχανικός δεδομένων και ML στην Amazon. Με το υπόβαθρο στο AI/ML, την Επιστήμη Δεδομένων και τα Μεγάλα Δεδομένα, η Sanjeeb σχεδιάζει και αναπτύσσει καινοτόμες λύσεις δεδομένων και ML που επιλύουν πολύπλοκες τεχνικές προκλήσεις και επιτυγχάνουν στρατηγικούς στόχους για παγκόσμιους πωλητές 3P που διαχειρίζονται τις επιχειρήσεις τους στο Amazon. Εκτός από τη δουλειά του ως μηχανικός Data και ML στην Amazon, ο Sanjeeb Panda είναι ένας άπληστος καλοφαγάς και λάτρης της μουσικής.
Sanjeeb Panda είναι μηχανικός δεδομένων και ML στην Amazon. Με το υπόβαθρο στο AI/ML, την Επιστήμη Δεδομένων και τα Μεγάλα Δεδομένα, η Sanjeeb σχεδιάζει και αναπτύσσει καινοτόμες λύσεις δεδομένων και ML που επιλύουν πολύπλοκες τεχνικές προκλήσεις και επιτυγχάνουν στρατηγικούς στόχους για παγκόσμιους πωλητές 3P που διαχειρίζονται τις επιχειρήσεις τους στο Amazon. Εκτός από τη δουλειά του ως μηχανικός Data και ML στην Amazon, ο Sanjeeb Panda είναι ένας άπληστος καλοφαγάς και λάτρης της μουσικής.
 Μπουράκ Γκοζλουκλού είναι Κύριος Αρχιτέκτονας Ειδικών Λύσεων AI/ML που βρίσκεται στη Βοστώνη, MA. Βοηθά τους στρατηγικούς πελάτες να υιοθετήσουν τεχνολογίες AWS και συγκεκριμένα λύσεις Generative AI για να επιτύχουν τους επιχειρηματικούς τους στόχους. Ο Burak έχει διδακτορικό στην Αεροδιαστημική Μηχανική από το METU, μεταπτυχιακό στη Μηχανική Συστημάτων και μεταδιδακτορικό στη δυναμική συστημάτων από το MIT στο Cambridge, MA. Ο Burak εξακολουθεί να είναι συνεργάτης της έρευνας στο MIT. Ο Burak είναι παθιασμένος με τη γιόγκα και τον διαλογισμό.
Μπουράκ Γκοζλουκλού είναι Κύριος Αρχιτέκτονας Ειδικών Λύσεων AI/ML που βρίσκεται στη Βοστώνη, MA. Βοηθά τους στρατηγικούς πελάτες να υιοθετήσουν τεχνολογίες AWS και συγκεκριμένα λύσεις Generative AI για να επιτύχουν τους επιχειρηματικούς τους στόχους. Ο Burak έχει διδακτορικό στην Αεροδιαστημική Μηχανική από το METU, μεταπτυχιακό στη Μηχανική Συστημάτων και μεταδιδακτορικό στη δυναμική συστημάτων από το MIT στο Cambridge, MA. Ο Burak εξακολουθεί να είναι συνεργάτης της έρευνας στο MIT. Ο Burak είναι παθιασμένος με τη γιόγκα και τον διαλογισμό.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/machine-learning/build-a-robust-text-to-sql-solution-generating-complex-queries-self-correcting-and-querying-diverse-data-sources/

