Αυτή η ανάρτηση συντάσσεται από τον Anatoly Khomenko, Μηχανικό Μηχανικής Μάθησης και τον Abdenour Bezzouh, Chief Technology Officer στο Talent.com.
Ιδρύθηκε το 2011, Talent.com συγκεντρώνει λίστες θέσεων εργασίας επί πληρωμή από τους πελάτες τους και δημόσιες λίστες θέσεων εργασίας και έχει δημιουργήσει μια ενοποιημένη πλατφόρμα με εύκολη αναζήτηση. Καλύπτοντας περισσότερες από 30 εκατομμύρια λίστες θέσεων εργασίας σε περισσότερες από 75 χώρες και καλύπτοντας διάφορες γλώσσες, βιομηχανίες και κανάλια διανομής, το Talent.com ανταποκρίνεται στις διαφορετικές ανάγκες των ατόμων που αναζητούν εργασία, συνδέοντας αποτελεσματικά εκατομμύρια άτομα που αναζητούν εργασία με ευκαιρίες εργασίας.
Η αποστολή του Talent.com είναι να διευκολύνει τις παγκόσμιες συνδέσεις εργατικού δυναμικού. Για να το πετύχει αυτό, το Talent.com συγκεντρώνει λίστες θέσεων εργασίας από διάφορες πηγές στον Ιστό, προσφέροντας στους αναζητούντες εργασία πρόσβαση σε μια εκτεταμένη δεξαμενή άνω των 30 εκατομμυρίων ευκαιριών εργασίας προσαρμοσμένες στις δεξιότητες και τις εμπειρίες τους. Στο πλαίσιο αυτής της αποστολής, το Talent.com συνεργάστηκε με την AWS για να αναπτύξει μια μηχανή προτάσεων εργασίας αιχμής με γνώμονα τη βαθιά μάθηση, με στόχο να βοηθήσει τους χρήστες να προχωρήσουν την καριέρα τους.
Για να διασφαλιστεί η αποτελεσματική λειτουργία αυτής της μηχανής προτάσεων εργασίας, είναι ζωτικής σημασίας να εφαρμοστεί ένας αγωγός επεξεργασίας δεδομένων μεγάλης κλίμακας που είναι υπεύθυνος για την εξαγωγή και τη βελτίωση χαρακτηριστικών από τις συγκεντρωτικές λίστες εργασιών του Talent.com. Αυτός ο αγωγός μπορεί να επεξεργάζεται 5 εκατομμύρια ημερήσιες εγγραφές σε λιγότερο από 1 ώρα και επιτρέπει την παράλληλη επεξεργασία πολλών ημερών εγγραφών. Επιπλέον, αυτή η λύση επιτρέπει τη γρήγορη ανάπτυξη στην παραγωγή. Η κύρια πηγή δεδομένων για αυτόν τον αγωγό είναι η μορφή JSON Lines, που είναι αποθηκευμένη σε Απλή υπηρεσία αποθήκευσης Amazon (Amazon S3) και χωρίστηκε κατά ημερομηνία. Κάθε μέρα, αυτό έχει ως αποτέλεσμα τη δημιουργία δεκάδων χιλιάδων αρχείων JSON Lines, με σταδιακές ενημερώσεις να πραγματοποιούνται καθημερινά.
Ο πρωταρχικός στόχος αυτού του αγωγού επεξεργασίας δεδομένων είναι να διευκολύνει τη δημιουργία λειτουργιών που είναι απαραίτητες για την εκπαίδευση και την ανάπτυξη της μηχανής προτάσεων εργασίας στο Talent.com. Αξίζει να σημειωθεί ότι αυτός ο αγωγός πρέπει να υποστηρίζει σταδιακές ενημερώσεις και να καλύπτει τις περίπλοκες απαιτήσεις εξαγωγής χαρακτηριστικών που είναι απαραίτητες για τις ενότητες εκπαίδευσης και ανάπτυξης που είναι απαραίτητες για το σύστημα προτάσεων εργασίας. Ο αγωγός μας ανήκει στη γενική οικογένεια διαδικασιών ETL (εξαγωγή, μετασχηματισμός και φόρτωση) που συνδυάζει δεδομένα από πολλαπλές πηγές σε ένα μεγάλο, κεντρικό αποθετήριο.
Για περισσότερες πληροφορίες σχετικά με τον τρόπο με τον οποίο το Talent.com και η AWS δημιούργησαν συνεργατικά προηγμένες τεχνικές εκπαίδευσης μοντέλων επεξεργασίας φυσικής γλώσσας και βαθιάς μάθησης, χρησιμοποιώντας Amazon Sage Maker για να δημιουργήσετε ένα σύστημα συστάσεων εργασίας, ανατρέξτε στο Από το κείμενο στη δουλειά των ονείρων: Δημιουργία ενός προτεινόμενου εργασίας βάσει NLP στο Talent.com με το Amazon SageMaker. Το σύστημα περιλαμβάνει μηχανική χαρακτηριστικών, σχεδιασμό αρχιτεκτονικής μοντέλων βαθιάς εκμάθησης, βελτιστοποίηση υπερπαραμέτρων και αξιολόγηση μοντέλων, όπου όλες οι ενότητες εκτελούνται χρησιμοποιώντας Python.
Αυτή η ανάρτηση δείχνει πώς χρησιμοποιήσαμε το SageMaker για να δημιουργήσουμε έναν αγωγό επεξεργασίας δεδομένων μεγάλης κλίμακας για την προετοιμασία λειτουργιών για τη μηχανή προτάσεων εργασίας στο Talent.com. Η λύση που προκύπτει επιτρέπει σε έναν Επιστήμονα Δεδομένων να ιδεολογήσει την εξαγωγή χαρακτηριστικών σε ένα σημειωματάριο SageMaker χρησιμοποιώντας βιβλιοθήκες Python, όπως π.χ. Scikit-Μάθετε or PyTorchκαι, στη συνέχεια, να αναπτύξετε γρήγορα τον ίδιο κώδικα στον αγωγό επεξεργασίας δεδομένων εκτελώντας εξαγωγή χαρακτηριστικών σε κλίμακα. Η λύση δεν απαιτεί τη μεταφορά του κώδικα εξαγωγής χαρακτηριστικών για τη χρήση του PySpark, όπως απαιτείται κατά τη χρήση Κόλλα AWS ως λύση ETL. Η λύση μας μπορεί να αναπτυχθεί και να αναπτυχθεί αποκλειστικά από έναν επιστήμονα δεδομένων από άκρο σε άκρο χρησιμοποιώντας μόνο ένα SageMaker και δεν απαιτεί γνώση άλλων λύσεων ETL, όπως π.χ. Παρτίδα AWS. Αυτό μπορεί να συντομεύσει σημαντικά τον χρόνο που απαιτείται για την ανάπτυξη του αγωγού Machine Learning (ML) στην παραγωγή. Ο αγωγός λειτουργεί μέσω Python και ενσωματώνεται απρόσκοπτα με ροές εργασίας εξαγωγής χαρακτηριστικών, καθιστώντας τον προσαρμόσιμο σε ένα ευρύ φάσμα εφαρμογών ανάλυσης δεδομένων.
Επισκόπηση λύσεων
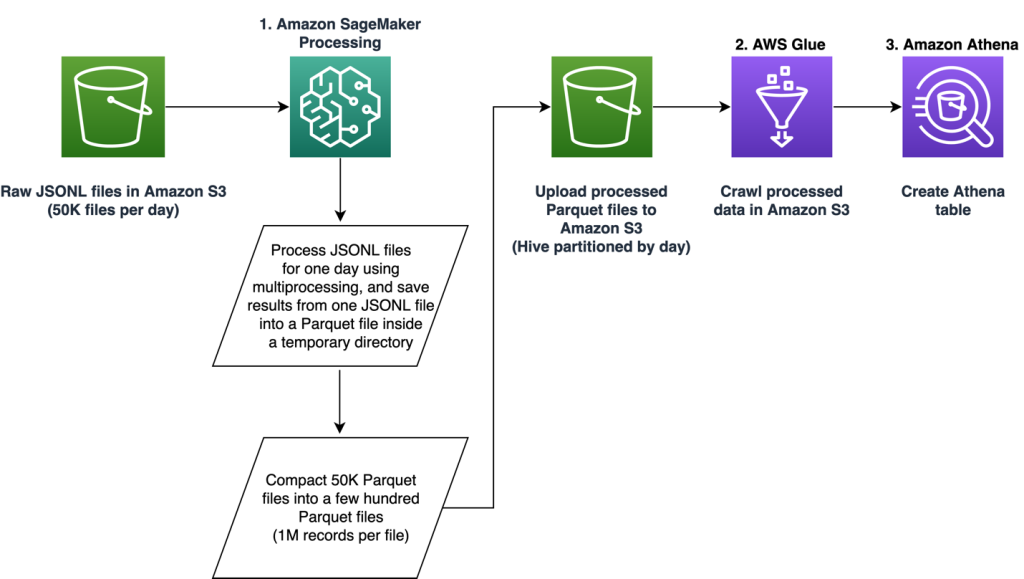
Ο αγωγός αποτελείται από τρεις κύριες φάσεις:
- Χρησιμοποιήστε ένα Επεξεργασία Amazon SageMaker εργασία για τη διαχείριση ακατέργαστων αρχείων JSONL που σχετίζονται με μια καθορισμένη ημέρα. Πολλές ημέρες δεδομένων μπορούν να υποβληθούν σε επεξεργασία από ξεχωριστές εργασίες Επεξεργασίας ταυτόχρονα.
- Χρησιμοποιώ Κόλλα AWS για ανίχνευση δεδομένων μετά από επεξεργασία δεδομένων πολλών ημερών.
- Φόρτωση επεξεργασμένων χαρακτηριστικών για ένα καθορισμένο εύρος ημερομηνιών χρησιμοποιώντας SQL από ένα Αμαζόν Αθηνά πίνακα, μετά εκπαιδεύστε και αναπτύξτε το μοντέλο προτάσεων εργασίας.
Επεξεργαστείτε τα ακατέργαστα αρχεία JSONL
Επεξεργαζόμαστε ακατέργαστα αρχεία JSONL για μια καθορισμένη ημέρα χρησιμοποιώντας μια εργασία επεξεργασίας SageMaker. Η εργασία υλοποιεί την εξαγωγή χαρακτηριστικών και τη συμπίεση δεδομένων και αποθηκεύει τις επεξεργασμένες λειτουργίες σε αρχεία Parquet με 1 εκατομμύριο εγγραφές ανά αρχείο. Εκμεταλλευόμαστε την παραλληλοποίηση της CPU για να εκτελούμε την εξαγωγή χαρακτηριστικών για κάθε ακατέργαστο αρχείο JSONL παράλληλα. Τα αποτελέσματα της επεξεργασίας κάθε αρχείου JSONL αποθηκεύονται σε ένα ξεχωριστό αρχείο Parquet μέσα σε έναν προσωρινό κατάλογο. Αφού ολοκληρωθεί η επεξεργασία όλων των αρχείων JSONL, πραγματοποιούμε συμπίεση χιλιάδων μικρών αρχείων Parquet σε πολλά αρχεία με 1 εκατομμύριο εγγραφές ανά αρχείο. Τα συμπιεσμένα αρχεία Parquet στη συνέχεια μεταφορτώνονται στο Amazon S3 ως έξοδος της εργασίας επεξεργασίας. Η συμπίεση δεδομένων εξασφαλίζει αποτελεσματική ανίχνευση και ερωτήματα SQL στα επόμενα στάδια της διοχέτευσης.
Το παρακάτω είναι το δείγμα κώδικα για να προγραμματίσετε μια εργασία Επεξεργασίας SageMaker για μια καθορισμένη ημέρα, για παράδειγμα 2020-01-01, χρησιμοποιώντας το SageMaker SDK. Η εργασία διαβάζει ακατέργαστα αρχεία JSONL από το Amazon S3 (για παράδειγμα από s3://bucket/raw-data/2020/01/01) και αποθηκεύει τα συμπιεσμένα αρχεία Parquet στο Amazon S3 (για παράδειγμα σε s3://bucket/processed/table-name/day_partition=2020-01-01/).
### install dependencies %pip install sagemaker pyarrow s3fs awswrangler import sagemaker
import boto3 from sagemaker.processing import FrameworkProcessor
from sagemaker.sklearn.estimator import SKLearn
from sagemaker import get_execution_role
from sagemaker.processing import ProcessingInput, ProcessingOutput region = boto3.session.Session().region_name
role = get_execution_role()
bucket = sagemaker.Session().default_bucket() ### we use instance with 16 CPUs and 128 GiB memory
### note that the script will NOT load the entire data into memory during compaction
### depending on the size of individual jsonl files, larger instance may be needed
instance = "ml.r5.4xlarge"
n_jobs = 8 ### we use 8 process workers
date = "2020-01-01" ### process data for one day est_cls = SKLearn
framework_version_str = "0.20.0" ### schedule processing job
script_processor = FrameworkProcessor( role=role, instance_count=1, instance_type=instance, estimator_cls=est_cls, framework_version=framework_version_str, volume_size_in_gb=500,
) script_processor.run( code="processing_script.py", ### name of the main processing script source_dir="../src/etl/", ### location of source code directory ### our processing script loads raw jsonl files directly from S3 ### this avoids long start-up times of the processing jobs, ### since raw data does not need to be copied into instance inputs=[], ### processing job input is empty outputs=[ ProcessingOutput(destination="s3://bucket/processed/table-name/", source="/opt/ml/processing/output"), ], arguments=[ ### directory with job's output "--output", "/opt/ml/processing/output", ### temporary directory inside instance "--tmp_output", "/opt/ml/tmp_output", "--n_jobs", str(n_jobs), ### number of process workers "--date", date, ### date to process ### location with raw jsonl files in S3 "--path", "s3://bucket/raw-data/", ], wait=False
)
Το ακόλουθο περίγραμμα κώδικα για το κύριο σενάριο (processing_script.py) που εκτελεί την εργασία επεξεργασίας SageMaker είναι η εξής:
import concurrent
import pyarrow.dataset as ds
import os
import s3fs
from pathlib import Path ### function to process raw jsonl file and save extracted features into parquet file from process_data import process_jsonl ### parse command line arguments
args = parse_args() ### we use s3fs to crawl S3 input path for raw jsonl files
fs = s3fs.S3FileSystem()
### we assume raw jsonl files are stored in S3 directories partitioned by date
### for example: s3://bucket/raw-data/2020/01/01/
jsons = fs.find(os.path.join(args.path, *args.date.split('-'))) ### temporary directory location inside the Processing job instance
tmp_out = os.path.join(args.tmp_output, f"day_partition={args.date}") ### directory location with job's output
out_dir = os.path.join(args.output, f"day_partition={args.date}") ### process individual jsonl files in parallel using n_jobs process workers
futures=[]
with concurrent.futures.ProcessPoolExecutor(max_workers=args.n_jobs) as executor: for file in jsons: inp_file = Path(file) out_file = os.path.join(tmp_out, inp_file.stem + ".snappy.parquet") ### process_jsonl function reads raw jsonl file from S3 location (inp_file) ### and saves result into parquet file (out_file) inside temporary directory futures.append(executor.submit(process_jsonl, file, out_file)) ### wait until all jsonl files are processed for future in concurrent.futures.as_completed(futures): result = future.result() ### compact parquet files
dataset = ds.dataset(tmp_out) if len(dataset.schema) > 0: ### save compacted parquet files with 1MM records per file ds.write_dataset(dataset, out_dir, format="parquet", max_rows_per_file=1024 * 1024)
Η επεκτασιμότητα είναι ένα βασικό χαρακτηριστικό του αγωγού μας. Πρώτον, πολλές εργασίες επεξεργασίας SageMaker μπορούν να χρησιμοποιηθούν για την επεξεργασία δεδομένων για αρκετές ημέρες ταυτόχρονα. Δεύτερον, αποφεύγουμε τη φόρτωση όλων των επεξεργασμένων ή μη επεξεργασμένων δεδομένων στη μνήμη ταυτόχρονα, ενώ επεξεργαζόμαστε κάθε καθορισμένη ημέρα δεδομένων. Αυτό επιτρέπει την επεξεργασία δεδομένων με χρήση τύπων στιγμιότυπων που δεν μπορούν να φιλοξενήσουν δεδομένα ολόκληρης ημέρας στην κύρια μνήμη. Η μόνη απαίτηση είναι ότι ο τύπος παρουσίας θα πρέπει να μπορεί να φορτώνει N raw JSONL ή επεξεργασμένα αρχεία Parquet στη μνήμη ταυτόχρονα, με το N να είναι ο αριθμός των εργαζομένων διεργασίας που χρησιμοποιούνται.
Ανίχνευση επεξεργασμένων δεδομένων χρησιμοποιώντας κόλλα AWS
Αφού υποβληθούν σε επεξεργασία όλα τα ακατέργαστα δεδομένα για πολλές ημέρες, μπορούμε να δημιουργήσουμε έναν πίνακα Athena από ολόκληρο το σύνολο δεδομένων χρησιμοποιώντας έναν ανιχνευτή AWS Glue. Χρησιμοποιούμε το AWS SDK για πάντα (awswrangler) βιβλιοθήκη για να δημιουργήσετε τον πίνακα χρησιμοποιώντας το ακόλουθο απόσπασμα:
import awswrangler as wr ### crawl processed data in S3
res = wr.s3.store_parquet_metadata( path='s3://bucket/processed/table-name/', database="database_name", table="table_name", dataset=True, mode="overwrite", sampling=1.0, path_suffix='.parquet',
) ### print table schema
print(res[0])
Φορτώστε επεξεργασμένα χαρακτηριστικά για εκπαίδευση
Οι επεξεργασμένες λειτουργίες για ένα καθορισμένο εύρος ημερομηνιών μπορούν τώρα να φορτωθούν από τον πίνακα Athena χρησιμοποιώντας SQL και αυτές οι δυνατότητες μπορούν στη συνέχεια να χρησιμοποιηθούν για την εκπαίδευση του μοντέλου πρότασης εργασίας. Για παράδειγμα, το ακόλουθο απόσπασμα φορτώνει ένα μήνα επεξεργασμένων λειτουργιών σε ένα DataFrame χρησιμοποιώντας το awswrangler βιβλιοθήκη:
import awswrangler as wr query = """ SELECT * FROM table_name WHERE day_partition BETWEN '2020-01-01' AND '2020-02-01' """ ### load 1 month of data from database_name.table_name into a DataFrame
df = wr.athena.read_sql_query(query, database='database_name')
Επιπλέον, η χρήση της SQL για τη φόρτωση επεξεργασμένων λειτουργιών για εκπαίδευση μπορεί να επεκταθεί για να φιλοξενήσει διάφορες άλλες περιπτώσεις χρήσης. Για παράδειγμα, μπορούμε να εφαρμόσουμε μια παρόμοια διοχέτευση για να διατηρήσουμε δύο ξεχωριστούς πίνακες Athena: έναν για την αποθήκευση εμφανίσεων χρήστη και έναν άλλο για την αποθήκευση των κλικ των χρηστών σε αυτές τις εμφανίσεις. Χρησιμοποιώντας δηλώσεις σύνδεσης SQL, μπορούμε να ανακτήσουμε εμφανίσεις στις οποίες οι χρήστες είτε έκαναν κλικ είτε δεν έκαναν κλικ και, στη συνέχεια, μεταφέρουμε αυτές τις εμφανίσεις σε μια εργασία εκπαίδευσης μοντέλου.
Οφέλη λύσης
Η εφαρμογή της προτεινόμενης λύσης φέρνει πολλά πλεονεκτήματα στην υπάρχουσα ροή εργασίας μας, όπως:
- Απλοποιημένη υλοποίηση – Η λύση επιτρέπει την εφαρμογή εξαγωγής χαρακτηριστικών στην Python χρησιμοποιώντας δημοφιλείς βιβλιοθήκες ML. Και, δεν απαιτεί τη μεταφορά του κώδικα στο PySpark. Αυτός ο εξορθολογισμός χαρακτηριστικών εξαγωγής είναι ο ίδιος κώδικας που αναπτύχθηκε από έναν επιστήμονα δεδομένων σε ένα σημειωματάριο θα εκτελεστεί από αυτόν τον αγωγό.
- Γρήγορη πορεία προς την παραγωγή – Η λύση μπορεί να αναπτυχθεί και να αναπτυχθεί από έναν επιστήμονα δεδομένων για να εκτελέσει εξαγωγή χαρακτηριστικών σε κλίμακα, επιτρέποντάς του να αναπτύξει ένα μοντέλο σύστασης ML έναντι αυτών των δεδομένων. Ταυτόχρονα, η ίδια λύση μπορεί να αναπτυχθεί στην παραγωγή από έναν Μηχανικό ML με ελάχιστες τροποποιήσεις που απαιτούνται.
- Επαναχρησιμοποίηση – Η λύση παρέχει ένα επαναχρησιμοποιήσιμο μοτίβο για εξαγωγή χαρακτηριστικών σε κλίμακα και μπορεί εύκολα να προσαρμοστεί για άλλες περιπτώσεις χρήσης πέρα από την κατασκευή μοντέλων συστάσεων.
- Αποδοτικότητα – Η λύση προσφέρει καλές επιδόσεις: επεξεργασία μίας ημέρας του Talent.comτα δεδομένα του χρειάστηκαν λιγότερο από 1 ώρα.
- Σταδιακές ενημερώσεις – Η λύση υποστηρίζει επίσης σταδιακές ενημερώσεις. Τα νέα ημερήσια δεδομένα μπορούν να υποβληθούν σε επεξεργασία με μια εργασία Επεξεργασίας SageMaker και η τοποθεσία S3 που περιέχει τα επεξεργασμένα δεδομένα μπορεί να ανιχνευθεί εκ νέου για ενημέρωση του πίνακα Athena. Μπορούμε επίσης να χρησιμοποιήσουμε μια εργασία cron για να ενημερώνουμε τα σημερινά δεδομένα πολλές φορές την ημέρα (για παράδειγμα, κάθε 3 ώρες).
Χρησιμοποιήσαμε αυτόν τον αγωγό ETL για να βοηθήσουμε το Talent.com να επεξεργάζεται 50,000 αρχεία την ημέρα που περιέχουν 5 εκατομμύρια εγγραφές και δημιουργήσαμε δεδομένα εκπαίδευσης χρησιμοποιώντας λειτουργίες που εξήχθησαν από ακατέργαστα δεδομένα 90 ημερών από το Talent.com—συνολικά 450 εκατομμύρια εγγραφές σε 900,000 αρχεία. Η σειρά μας βοήθησε το Talent.com να δημιουργήσει και να αναπτύξει το σύστημα συστάσεων στην παραγωγή μέσα σε μόλις 2 εβδομάδες. Η λύση εκτέλεσε όλες τις διεργασίες ML συμπεριλαμβανομένου του ETL στο Amazon SageMaker χωρίς να χρησιμοποιήσει άλλη υπηρεσία AWS. Το σύστημα προτάσεων εργασίας οδήγησε σε αύξηση 8.6% στην αναλογία κλικ προς αριθμό εμφανίσεων στις διαδικτυακές δοκιμές A/B έναντι μιας προηγούμενης λύσης βασισμένης στο XGBoost, βοηθώντας στη σύνδεση εκατομμυρίων χρηστών του Talent.com σε καλύτερες θέσεις εργασίας.
Συμπέρασμα
Αυτή η ανάρτηση περιγράφει τη γραμμή ETL που αναπτύξαμε για την επεξεργασία χαρακτηριστικών για εκπαίδευση και την ανάπτυξη ενός μοντέλου προτάσεων εργασίας στο Talent.com. Ο αγωγός μας χρησιμοποιεί εργασίες επεξεργασίας SageMaker για αποτελεσματική επεξεργασία δεδομένων και εξαγωγή χαρακτηριστικών σε μεγάλη κλίμακα. Ο κώδικας εξαγωγής χαρακτηριστικών υλοποιείται στην Python επιτρέποντας τη χρήση δημοφιλών βιβλιοθηκών ML για την εκτέλεση εξαγωγής χαρακτηριστικών σε κλίμακα, χωρίς την ανάγκη μεταφοράς του κώδικα για χρήση του PySpark.
Ενθαρρύνουμε τους αναγνώστες να διερευνήσουν τη δυνατότητα χρήσης του αγωγού που παρουσιάζεται σε αυτό το ιστολόγιο ως πρότυπο για τις περιπτώσεις χρήσης τους όπου απαιτείται εξαγωγή χαρακτηριστικών σε κλίμακα. Ο αγωγός μπορεί να αξιοποιηθεί από έναν Επιστήμονα Δεδομένων για την κατασκευή ενός μοντέλου ML και ο ίδιος αγωγός μπορεί στη συνέχεια να υιοθετηθεί από έναν Μηχανικό ML για να λειτουργήσει στην παραγωγή. Αυτό μπορεί να μειώσει σημαντικά τον χρόνο που απαιτείται για την παραγωγή της λύσης ML από άκρο σε άκρο, όπως συνέβη με το Talent.com. Οι αναγνώστες μπορούν να ανατρέξουν στο σεμινάριο για τη ρύθμιση και εκτέλεση εργασιών επεξεργασίας SageMaker. Παραπέμπουμε επίσης τους αναγνώστες να δουν την ανάρτηση Από το κείμενο στη δουλειά των ονείρων: Δημιουργία ενός προτεινόμενου εργασίας βάσει NLP στο Talent.com με το Amazon SageMaker, όπου συζητάμε για τη χρήση τεχνικών εκπαίδευσης μοντέλου βαθιάς μάθησης Amazon Sage Maker για τη δημιουργία του συστήματος προτάσεων εργασίας του Talent.com.
Σχετικά με τους συγγραφείς
 Ντμίτρι Μπεσπάλοφ είναι Ανώτερος Εφαρμοσμένος Επιστήμονας στο Amazon Machine Learning Solutions Lab, όπου βοηθά τους πελάτες του AWS σε διαφορετικούς κλάδους να επιταχύνουν την υιοθέτηση της τεχνητής νοημοσύνης και του cloud.
Ντμίτρι Μπεσπάλοφ είναι Ανώτερος Εφαρμοσμένος Επιστήμονας στο Amazon Machine Learning Solutions Lab, όπου βοηθά τους πελάτες του AWS σε διαφορετικούς κλάδους να επιταχύνουν την υιοθέτηση της τεχνητής νοημοσύνης και του cloud.
 Γι Σιανγκ είναι Applied Scientist II στο Amazon Machine Learning Solutions Lab, όπου βοηθά τους πελάτες της AWS σε διαφορετικούς κλάδους να επιταχύνουν την υιοθέτηση της τεχνητής νοημοσύνης και του cloud.
Γι Σιανγκ είναι Applied Scientist II στο Amazon Machine Learning Solutions Lab, όπου βοηθά τους πελάτες της AWS σε διαφορετικούς κλάδους να επιταχύνουν την υιοθέτηση της τεχνητής νοημοσύνης και του cloud.
 Tong Wang είναι Ανώτερος Εφαρμοσμένος Επιστήμονας στο Amazon Machine Learning Solutions Lab, όπου βοηθά τους πελάτες του AWS σε διαφορετικούς κλάδους να επιταχύνουν την υιοθέτηση της τεχνητής νοημοσύνης και του cloud.
Tong Wang είναι Ανώτερος Εφαρμοσμένος Επιστήμονας στο Amazon Machine Learning Solutions Lab, όπου βοηθά τους πελάτες του AWS σε διαφορετικούς κλάδους να επιταχύνουν την υιοθέτηση της τεχνητής νοημοσύνης και του cloud.
 Ανατόλι Χομένκο είναι Senior Machine Learning Engineer στο Talent.com με πάθος για την επεξεργασία φυσικής γλώσσας που ταιριάζει με καλούς ανθρώπους με καλές δουλειές.
Ανατόλι Χομένκο είναι Senior Machine Learning Engineer στο Talent.com με πάθος για την επεξεργασία φυσικής γλώσσας που ταιριάζει με καλούς ανθρώπους με καλές δουλειές.
 Abdenour Bezzouh είναι στέλεχος με περισσότερα από 25 χρόνια εμπειρίας στην κατασκευή και παροχή τεχνολογικών λύσεων που εκτείνονται σε εκατομμύρια πελάτες. Ο Abdenour κατείχε τη θέση του Chief Technology Officer (CTO) στο Talent.com όταν η ομάδα AWS σχεδίασε και εκτέλεσε τη συγκεκριμένη λύση για Talent.com.
Abdenour Bezzouh είναι στέλεχος με περισσότερα από 25 χρόνια εμπειρίας στην κατασκευή και παροχή τεχνολογικών λύσεων που εκτείνονται σε εκατομμύρια πελάτες. Ο Abdenour κατείχε τη θέση του Chief Technology Officer (CTO) στο Talent.com όταν η ομάδα AWS σχεδίασε και εκτέλεσε τη συγκεκριμένη λύση για Talent.com.
 Yanjun Qi είναι Senior Applied Science Manager στο Amazon Machine Learning Solution Lab. Καινοτομεί και εφαρμόζει μηχανική εκμάθηση για να βοηθήσει τους πελάτες του AWS να επιταχύνουν την υιοθέτηση της τεχνητής νοημοσύνης και του cloud.
Yanjun Qi είναι Senior Applied Science Manager στο Amazon Machine Learning Solution Lab. Καινοτομεί και εφαρμόζει μηχανική εκμάθηση για να βοηθήσει τους πελάτες του AWS να επιταχύνουν την υιοθέτηση της τεχνητής νοημοσύνης και του cloud.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/machine-learning/streamlining-etl-data-processing-at-talent-com-with-amazon-sagemaker/

