Δημιουργική τεχνητή νοημοσύνη (γενετική AI) τα μοντέλα έχουν επιδείξει εντυπωσιακές δυνατότητες στη δημιουργία κειμένου, εικόνων και άλλου περιεχομένου υψηλής ποιότητας. Ωστόσο, αυτά τα μοντέλα απαιτούν τεράστιες ποσότητες καθαρών, δομημένων δεδομένων εκπαίδευσης για να αξιοποιήσουν πλήρως τις δυνατότητές τους. Τα περισσότερα δεδομένα του πραγματικού κόσμου υπάρχουν σε μη δομημένες μορφές όπως τα PDF, τα οποία απαιτούν προεπεξεργασία για να μπορέσουν να χρησιμοποιηθούν αποτελεσματικά.
Σύμφωνα με IDC, τα μη δομημένα δεδομένα αντιπροσωπεύουν πάνω από το 80% όλων των επιχειρηματικών δεδομένων σήμερα. Αυτό περιλαμβάνει μορφές όπως μηνύματα ηλεκτρονικού ταχυδρομείου, PDF, σαρωμένα έγγραφα, εικόνες, ήχο, βίντεο και άλλα. Ενώ αυτά τα δεδομένα περιέχουν πολύτιμες πληροφορίες, η μη δομημένη φύση τους καθιστά δύσκολο για τους αλγόριθμους τεχνητής νοημοσύνης να ερμηνεύσουν και να μάθουν από αυτά. Σύμφωνα με α Έρευνα 2019 από την Deloitte, μόνο το 18% των επιχειρήσεων ανέφεραν ότι ήταν σε θέση να επωφεληθούν από μη δομημένα δεδομένα.
Καθώς η υιοθέτηση της τεχνητής νοημοσύνης συνεχίζει να επιταχύνεται, η ανάπτυξη αποτελεσματικών μηχανισμών για την πέψη και τη μάθηση από μη δομημένα δεδομένα γίνεται ακόμη πιο κρίσιμη στο μέλλον. Αυτό θα μπορούσε να περιλαμβάνει καλύτερα εργαλεία προεπεξεργασίας, ημι-εποπτευόμενες τεχνικές εκμάθησης και προόδους στην επεξεργασία φυσικής γλώσσας. Οι εταιρείες που χρησιμοποιούν τα μη δομημένα δεδομένα τους πιο αποτελεσματικά θα αποκτήσουν σημαντικά ανταγωνιστικά πλεονεκτήματα από την τεχνητή νοημοσύνη. Τα καθαρά δεδομένα είναι σημαντικά για την καλή απόδοση του μοντέλου. Τα εξαγόμενα κείμενα εξακολουθούν να έχουν μεγάλους όγκους ασυναρτησίες και κείμενα πλήρους γραφής (π.χ. ανάγνωση HTML). Τα αποκομμένα δεδομένα από το Διαδίκτυο συχνά περιέχουν πολλές αντιγραφές. Τα δεδομένα από τα μέσα κοινωνικής δικτύωσης, οι κριτικές ή οποιοδήποτε περιεχόμενο που δημιουργείται από τον χρήστη μπορεί επίσης να περιέχει τοξικό και μεροληπτικό περιεχόμενο και ίσως χρειαστεί να τα φιλτράρετε χρησιμοποιώντας ορισμένα βήματα προεπεξεργασίας. Θα μπορούσαν επίσης να υπάρχουν πολλά περιεχόμενα χαμηλής ποιότητας ή κείμενα που δημιουργούνται από bot, τα οποία μπορούν να φιλτραριστούν χρησιμοποιώντας συνοδευτικά μεταδεδομένα (π.χ. φιλτράρισμα απαντήσεων εξυπηρέτησης πελατών που έλαβαν χαμηλές βαθμολογίες πελατών).
Η προετοιμασία δεδομένων είναι σημαντική σε πολλαπλά στάδια στην ανάκτηση επαυξημένης γενιάς (ΚΟΥΡΕΛΙ) μοντέλα. Τα έγγραφα πηγής γνώσης χρειάζονται προεπεξεργασία, όπως καθαρισμός κειμένου και δημιουργία σημασιολογικών ενσωματώσεων, ώστε να μπορούν να ευρετηριαστούν και να ανακτηθούν αποτελεσματικά. Το ερώτημα φυσικής γλώσσας του χρήστη απαιτεί επίσης προεπεξεργασία, ώστε να μπορεί να κωδικοποιηθεί σε ένα διάνυσμα και να συγκριθεί με ενσωματώσεις εγγράφων. Μετά την ανάκτηση σχετικών πλαισίων, ενδέχεται να χρειαστούν πρόσθετη προεπεξεργασία, όπως περικοπή, προτού συνδεθούν με το ερώτημα του χρήστη για τη δημιουργία της τελικής προτροπής για το μοντέλο θεμελίωσης. Καμβάς Amazon SageMaker τώρα υποστηρίζει ολοκληρωμένες δυνατότητες προετοιμασίας δεδομένων που υποστηρίζονται από Amazon SageMaker Data Wrangler. Με αυτήν την ενσωμάτωση, το SageMaker Canvas παρέχει στους πελάτες έναν από άκρο σε άκρο χώρο εργασίας χωρίς κώδικα για την προετοιμασία δεδομένων, τη δημιουργία και τη χρήση μοντέλων ML και θεμελίων για την επιτάχυνση του χρόνου από τα δεδομένα στις επιχειρηματικές πληροφορίες. Τώρα μπορείτε εύκολα να ανακαλύψετε και να συγκεντρώσετε δεδομένα από περισσότερες από 50 πηγές δεδομένων και να εξερευνήσετε και να προετοιμάσετε δεδομένα χρησιμοποιώντας περισσότερες από 300 ενσωματωμένες αναλύσεις και μετασχηματισμούς στην οπτική διεπαφή του SageMaker Canvas.
Επισκόπηση λύσεων
Σε αυτήν την ανάρτηση, εργαζόμαστε με ένα σύνολο δεδομένων τεκμηρίωσης PDF—Θεμέλιο του Αμαζονίου τον οδηγό χρήστη. Περαιτέρω, δείχνουμε πώς να προεπεξεργάζεται ένα σύνολο δεδομένων για RAG. Συγκεκριμένα, καθαρίζουμε τα δεδομένα και δημιουργούμε τεχνουργήματα RAG για να απαντήσουμε στις ερωτήσεις σχετικά με το περιεχόμενο του συνόλου δεδομένων. Εξετάστε το ακόλουθο πρόβλημα μηχανικής εκμάθησης (ML): ο χρήστης κάνει μια ερώτηση μεγάλου μοντέλου γλώσσας (LLM): «Πώς να φιλτράρω και να αναζητώ μοντέλα στο Amazon Bedrock;». Το LLM δεν έχει δει την τεκμηρίωση κατά τη διάρκεια του σταδίου εκπαίδευσης ή τελειοποίησης, επομένως δεν θα μπορούσε να απαντήσει στην ερώτηση και πιθανότατα θα έχει παραισθήσεις. Στόχος μας με αυτήν την ανάρτηση, είναι να βρούμε ένα σχετικό κομμάτι κειμένου από το PDF (δηλαδή, RAG) και να το επισυνάψουμε στην προτροπή, επιτρέποντας έτσι στο LLM να απαντήσει σε ερωτήσεις που αφορούν συγκεκριμένα αυτό το έγγραφο.
Παρακάτω, δείχνουμε πώς μπορείτε να κάνετε όλα αυτά τα κύρια βήματα προεπεξεργασίας από Καμβάς Amazon SageMaker (τροφοδοτείται από Amazon SageMaker Data Wrangler):
- Εξαγωγή κειμένου από έγγραφο PDF (τροφοδοτείται από Texttract)
- Κατάργηση ευαίσθητων πληροφοριών (τροφοδοτείται από το Comprehend)
- Κομμάτισε το κείμενο σε κομμάτια.
- Δημιουργήστε ενσωματώσεις για κάθε κομμάτι (τροφοδοτείται από το Bedrock).
- Μεταφόρτωση ενσωμάτωσης σε διανυσματική βάση δεδομένων (τροφοδοτείται από το OpenSearch)

Προϋποθέσεις
Για αυτήν την καθοδήγηση, θα πρέπει να έχετε τα εξής:
Note: Δημιουργήστε τομείς της υπηρεσίας OpenSearch ακολουθώντας τις οδηγίες εδώ. Για απλότητα, ας διαλέξουμε την επιλογή με κύριο όνομα χρήστη και κωδικό πρόσβασης για λεπτομερή έλεγχο πρόσβασης. Μόλις δημιουργηθεί ο τομέας, δημιουργήστε ένα διανυσματικό ευρετήριο με τις ακόλουθες αντιστοιχίσεις και η διανυσματική διάσταση 1536 ευθυγραμμίζεται με τις ενσωματώσεις Amazon Titan:
Walkthrough
Δημιουργήστε μια ροή δεδομένων
Σε αυτήν την ενότητα, καλύπτουμε πώς μπορούμε να δημιουργήσουμε μια ροή δεδομένων για την εξαγωγή κειμένου και μεταδεδομένων από αρχεία PDF, τον καθαρισμό και την επεξεργασία των δεδομένων, τη δημιουργία ενσωματώσεων χρησιμοποιώντας το Amazon Bedrock και την ευρετηρίαση των δεδομένων στο Amazon OpenSearch.
Εκκινήστε το SageMaker Canvas
Για να εκκινήσετε το SageMaker Canvas, ολοκληρώστε τα παρακάτω βήματα:
- Στον Αμαζόνιο Κονσόλα SageMaker, επιλέξτε Domains στο παράθυρο πλοήγησης.
- Επιλέξτε τον τομέα σας.
- Στο μενού εκκίνησης, επιλέξτε καμβάς.

Δημιουργήστε μια ροή δεδομένων
Ολοκληρώστε τα παρακάτω βήματα για να δημιουργήσετε μια ροή δεδομένων στον καμβά SageMaker:
- Στην αρχική σελίδα του SageMaker Canvas, επιλέξτε Data Wrangler.
- Επιλέξτε Δημιουργία στη δεξιά πλευρά της σελίδας, μετά δώστε ένα όνομα ροής δεδομένων και επιλέξτε Δημιουργία.

- Αυτό θα προσγειωθεί σε μια σελίδα ροής δεδομένων.
- Επιλέξτε Εισαγωγή δεδομένων, επιλέξτε δεδομένα πίνακα.

Τώρα ας εισαγάγουμε τα δεδομένα από τον κάδο Amazon S3:
- Επιλέξτε Εισαγωγή δεδομένων και επιλέξτε Πινακοειδής από την αναπτυσσόμενη λίστα.
- Πηγή δεδομένων και επιλέξτε Amazon S3 από την αναπτυσσόμενη λίστα.

- Μεταβείτε στο αρχείο μεταδεδομένων με θέσεις αρχείων PDF και επιλέξτε το αρχείο.

- Τώρα το αρχείο μεταδεδομένων φορτώνεται στη ροή δεδομένων προετοιμασίας δεδομένων και μπορούμε να προχωρήσουμε στην προσθήκη των επόμενων βημάτων για τη μετατροπή των δεδομένων και του ευρετηρίου σε Amazon Opensearch. Σε αυτήν την περίπτωση το αρχείο έχει τα ακόλουθα μεταδεδομένα, με τη θέση κάθε αρχείου στον κατάλογο Amazon S3.

Για να προσθέσετε έναν νέο μετασχηματισμό, ολοκληρώστε τα παρακάτω βήματα:
- Επιλέξτε το σύμβολο συν και επιλέξτε Προσθήκη μετασχηματισμού.

- Επιλέξτε Προσθέστε το βήμα Και επιλέξτε Προσαρμοσμένος μετασχηματισμός.
- Μπορείτε να δημιουργήσετε έναν προσαρμοσμένο μετασχηματισμό χρησιμοποιώντας Pandas, PySpark, συναρτήσεις που ορίζονται από τον χρήστη Python και SQL PySpark. Επιλέγω Python (Pyspark) για αυτήν την περίπτωση χρήσης.
- Εισαγάγετε ένα όνομα για το βήμα. Από τα παραδείγματα αποσπασμάτων κώδικα, περιηγηθείτε και επιλέξτε εξαγωγή κειμένου από pdf. Κάντε τις απαραίτητες αλλαγές στο απόσπασμα κώδικα και επιλέξτε Πρόσθεση.
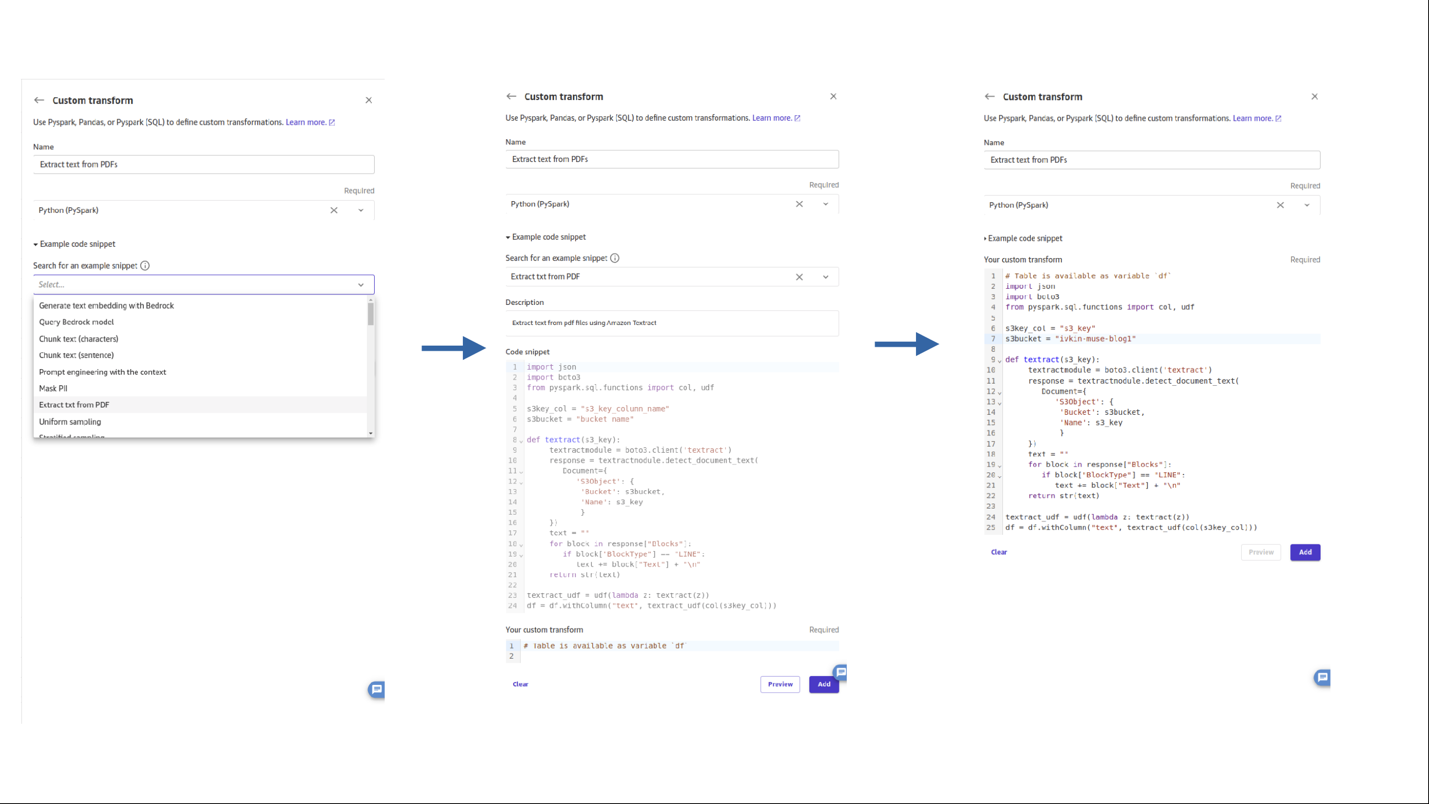

- Ας προσθέσουμε ένα βήμα για τη διόρθωση των δεδομένων Προσωπικής Αναγνώρισης (PII) από τα εξαγόμενα δεδομένα με μόχλευση Κατανοήστε το Amazon. Επιλέξτε Προσθέστε το βήμα Και επιλέξτε Προσαρμοσμένος μετασχηματισμός. Και επιλέξτε Python (PySpark).
Από τα παραδείγματα αποσπασμάτων κώδικα, περιηγηθείτε και επιλέξτε μάσκα PII. Κάντε τις απαραίτητες αλλαγές στο απόσπασμα κώδικα και επιλέξτε Προσθήκη.


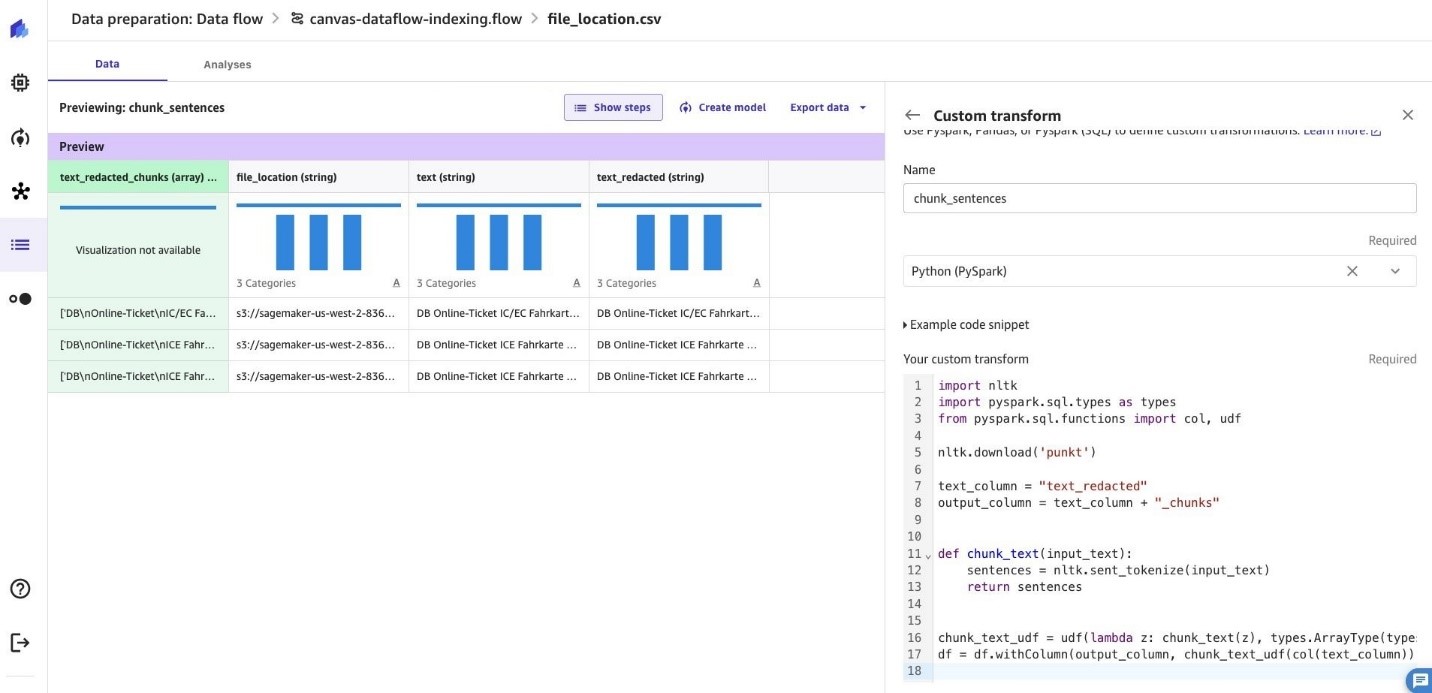
- Το επόμενο βήμα είναι να τεμαχίσετε το περιεχόμενο του κειμένου. Επιλέγω Προσθέστε το βήμα Και επιλέξτε Προσαρμοσμένος μετασχηματισμός. Και επιλέξτε Python (PySpark).
Από τα παραδείγματα αποσπασμάτων κώδικα, περιηγηθείτε και επιλέξτε Κομμάτιο κείμενο. Κάντε τις απαραίτητες αλλαγές στο απόσπασμα κώδικα και επιλέξτε Προσθήκη.

- Ας μετατρέψουμε το περιεχόμενο κειμένου σε διανυσματικές ενσωματώσεις χρησιμοποιώντας το Θεμέλιο του Αμαζονίου Μοντέλο Titan Embeddings. Επιλέγω Προσθέστε το βήμα Και επιλέξτε Προσαρμοσμένος μετασχηματισμός. Και επιλέξτε Python (PySpark).
Από τα παραδείγματα αποσπασμάτων κώδικα, περιηγηθείτε και επιλέξτε Δημιουργήστε ενσωμάτωση κειμένου με το Bedrock. Κάντε τις απαραίτητες αλλαγές στο απόσπασμα κώδικα και επιλέξτε Προσθήκη.

- Τώρα έχουμε διαθέσιμες διανυσματικές ενσωματώσεις για τα περιεχόμενα του αρχείου PDF. Ας προχωρήσουμε και ευρετηριάζουμε τα δεδομένα στο Amazon OpenSearch. Επιλέγω Προσθέστε το βήμα Και επιλέξτε Προσαρμοσμένος μετασχηματισμός. Και επιλέξτε Python (PySpark). Είστε ελεύθεροι να ξαναγράψετε τον ακόλουθο κώδικα για να χρησιμοποιήσετε την προτιμώμενη διανυσματική βάση δεδομένων σας. Για λόγους απλότητας, χρησιμοποιούμε κύριο όνομα χρήστη και κωδικό πρόσβασης για πρόσβαση στα API του OpenSearch, για φόρτους εργασίας παραγωγής επιλέξτε την επιλογή σύμφωνα με τις πολιτικές του οργανισμού σας.

Τέλος, η ροή δεδομένων που δημιουργείται θα είναι η εξής:

Με αυτήν τη ροή δεδομένων, τα δεδομένα από το αρχείο PDF έχουν διαβαστεί και έχουν ευρετηριαστεί με ενσωματώσεις διανυσμάτων στο Amazon OpenSearch. Τώρα ήρθε η ώρα να δημιουργήσουμε ένα αρχείο με ερωτήματα για να υποβάλουμε ερωτήματα στα ευρετηριασμένα δεδομένα και να τα αποθηκεύσουμε στη θέση Amazon S3. Θα κατευθύνουμε τη ροή δεδομένων αναζήτησής μας στο αρχείο και θα εξάγουμε ένα αρχείο με τα αντίστοιχα αποτελέσματα σε ένα νέο αρχείο σε μια τοποθεσία Amazon S3.
Προετοιμασία προτροπής
Αφού δημιουργήσουμε μια βάση γνώσεων από το PDF μας, μπορούμε να τη δοκιμάσουμε κάνοντας αναζήτηση στη βάση γνώσεων για μερικά δείγματα ερωτημάτων. Θα επεξεργαστούμε κάθε ερώτημα ως εξής:
- Δημιουργία ενσωμάτωσης για το ερώτημα (τροφοδοτείται από το Amazon Bedrock)
- Διανυσματική βάση δεδομένων ερωτημάτων για το περιβάλλον πλησιέστερου γείτονα (τροφοδοτείται από το Amazon OpenSearch)
- Συνδυάστε το ερώτημα και το περιβάλλον στην προτροπή.
- Ερώτημα LLM με προτροπή (τροφοδοτείται από το Amazon Bedrock)

- Στην αρχική σελίδα του SageMaker Canvas, επιλέξτε Προετοιμασία δεδομένων.
- Επιλέξτε Δημιουργία στη δεξιά πλευρά της σελίδας, μετά δώστε ένα όνομα ροής δεδομένων και επιλέξτε Δημιουργία.

Τώρα ας φορτώσουμε τις ερωτήσεις χρήστη και, στη συνέχεια, ας δημιουργήσουμε μια προτροπή συνδυάζοντας την ερώτηση και τα παρόμοια έγγραφα. Αυτή η προτροπή παρέχεται στο LLM για τη δημιουργία απάντησης στην ερώτηση του χρήστη.
- Ας φορτώσουμε ένα αρχείο csv με ερωτήσεις χρήστη. Επιλέγω Εισαγωγή δεδομένων και επιλέξτε Πινακοειδής από την αναπτυσσόμενη λίστα.
- Πηγή δεδομένων, και επιλέξτε Amazon S3 από την αναπτυσσόμενη λίστα. Εναλλακτικά, μπορείτε να επιλέξετε να ανεβάσετε ένα αρχείο με ερωτήματα χρήστη.

- Ας προσθέσουμε έναν προσαρμοσμένο μετασχηματισμό για να μετατρέψουμε τα δεδομένα σε διανυσματικές ενσωματώσεις, ακολουθούμενη από αναζήτηση σχετικών ενσωματώσεων από το Amazon OpenSearch, πριν στείλουμε ένα μήνυμα προτροπής στο Amazon Bedrock με το ερώτημα και το πλαίσιο από τη γνωσιακή βάση. Για να δημιουργήσετε ενσωματώσεις για το ερώτημα, μπορείτε να χρησιμοποιήσετε το ίδιο παράδειγμα απόσπασμα κώδικα Δημιουργήστε ενσωμάτωση κειμένου με το Bedrock που αναφέρεται στο Βήμα #7 παραπάνω.
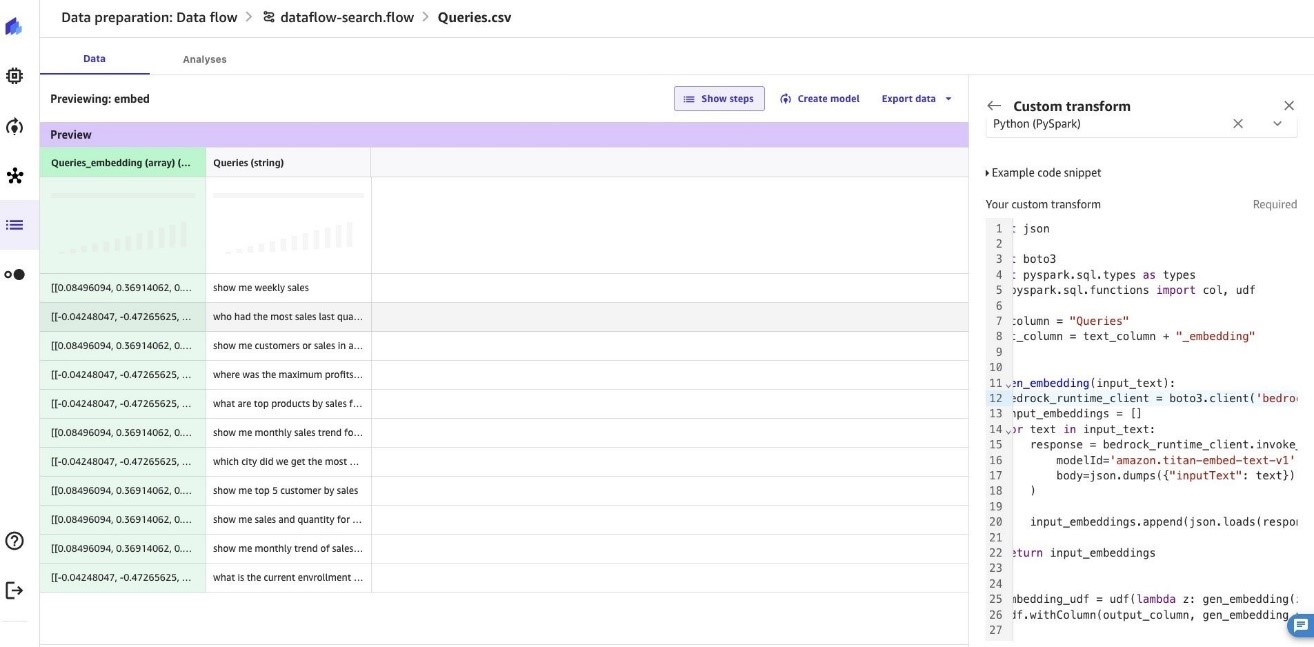
Ας επικαλεστούμε το Amazon OpenSearch API για να αναζητήσουμε σχετικά έγγραφα για τις δημιουργούμενες ενσωματώσεις διανυσμάτων. Προσθέστε έναν προσαρμοσμένο μετασχηματισμό με την Python (PySpark).
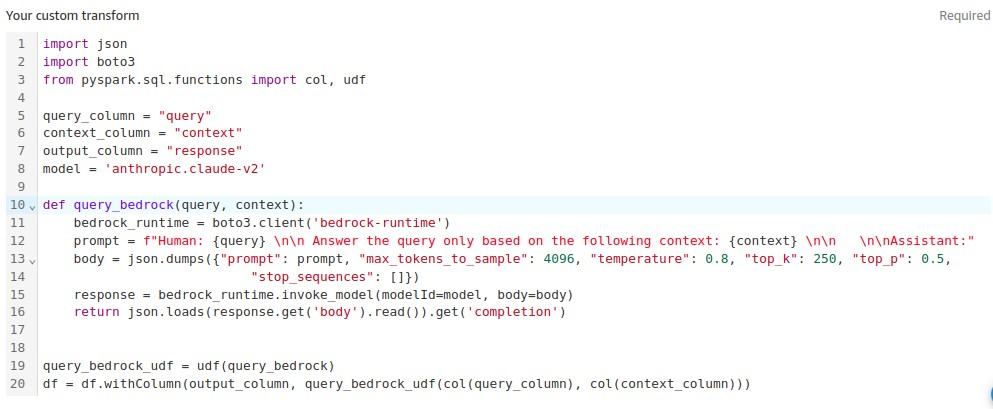
Ας προσθέσουμε έναν προσαρμοσμένο μετασχηματισμό για να καλέσουμε το Amazon Bedrock API για απάντηση ερωτημάτων, μεταβιβάζοντας τα έγγραφα από τη βάση γνώσεων Amazon OpenSearch. Από τα παραδείγματα αποσπασμάτων κώδικα, περιηγηθείτε και επιλέξτε Ερώτημα θεμελιώδους βάσης με πλαίσιο. Κάντε τις απαραίτητες αλλαγές στο απόσπασμα κώδικα και επιλέξτε Προσθήκη.
Συνοπτικά, η ροή δεδομένων απάντησης ερωτήσεων βάσει RAG έχει ως εξής:

Οι επαγγελματίες ML αφιερώνουν πολύ χρόνο στη δημιουργία κώδικα μηχανικής χαρακτηριστικών, εφαρμόζοντάς τον στα αρχικά σύνολα δεδομένων τους, εκπαιδεύοντας μοντέλα στα μηχανικά σύνολα δεδομένων και αξιολογώντας την ακρίβεια του μοντέλου. Δεδομένης της πειραματικής φύσης αυτής της εργασίας, ακόμη και το μικρότερο έργο οδηγεί σε πολλαπλές επαναλήψεις. Ο ίδιος κώδικας μηχανικής χαρακτηριστικών εκτελείται συχνά ξανά και ξανά, χάνοντας χρόνο και υπολογίζοντας πόρους για την επανάληψη των ίδιων λειτουργιών. Σε μεγάλους οργανισμούς, αυτό μπορεί να προκαλέσει ακόμη μεγαλύτερη απώλεια παραγωγικότητας, επειδή διαφορετικές ομάδες συχνά εκτελούν πανομοιότυπες εργασίες ή ακόμη και γράφουν διπλό κώδικα μηχανικής χαρακτηριστικών επειδή δεν γνωρίζουν προηγούμενη εργασία. Για να αποφύγουμε την επανεπεξεργασία των λειτουργιών, θα εξάγουμε τη ροή δεδομένων μας σε μια Amazon Σωλήνας SageMaker. Ας επιλέξουμε το κουμπί + στα δεξιά του ερωτήματος. Επιλέξτε εξαγωγή ροής δεδομένων και επιλέξτε Εκτελέστε το SageMaker Pipeline (μέσω σημειωματάριου Jupyter).

Καθαρισμό
Για να αποφύγετε μελλοντικές χρεώσεις, διαγράψτε ή τερματίστε τους πόρους που δημιουργήσατε κατά την παρακολούθηση αυτής της ανάρτησης. Αναφέρομαι σε Αποσύνδεση από το Amazon SageMaker Canvas Για περισσότερες πληροφορίες.
Συμπέρασμα
Σε αυτήν την ανάρτηση, σας δείξαμε πώς έχει τις δυνατότητες του Amazon SageMaker Canvas από άκρο σε άκρο, αναλαμβάνοντας τον ρόλο ενός επαγγελματία δεδομένων που προετοιμάζει δεδομένα για ένα LLM. Η διαδραστική προετοιμασία δεδομένων επέτρεψε τον γρήγορο καθαρισμό, τον μετασχηματισμό και την ανάλυση των δεδομένων για τη δημιουργία ενημερωτικών χαρακτηριστικών. Καταργώντας τις πολυπλοκότητες κωδικοποίησης, το SageMaker Canvas επέτρεψε την ταχεία επανάληψη για τη δημιουργία ενός συνόλου δεδομένων εκπαίδευσης υψηλής ποιότητας. Αυτή η επιταχυνόμενη ροή εργασίας οδήγησε απευθείας στη δημιουργία, την εκπαίδευση και την ανάπτυξη ενός αποδοτικού μοντέλου μηχανικής μάθησης για επιχειρηματικό αντίκτυπο. Με την ολοκληρωμένη προετοιμασία δεδομένων και την ενοποιημένη εμπειρία από δεδομένα έως πληροφορίες, το SageMaker Canvas δίνει τη δυνατότητα στους χρήστες να βελτιώσουν τα αποτελέσματά τους ML.
Σας ενθαρρύνουμε να μάθετε περισσότερα εξερευνώντας Amazon SageMaker Data Wrangler, Καμβάς Amazon SageMaker, Amazon Titan μοντέλα, Θεμέλιο του Αμαζονίουκαι το Amazon Υπηρεσία OpenSearch για να δημιουργήσετε μια λύση χρησιμοποιώντας το δείγμα υλοποίησης που παρέχεται σε αυτήν την ανάρτηση και ένα σύνολο δεδομένων που σχετίζεται με την επιχείρησή σας. Εάν έχετε ερωτήσεις ή προτάσεις, αφήστε ένα σχόλιο.
Σχετικά με τους Συγγραφείς
 Ajjay Govindaram είναι Senior Solutions Architect στην AWS. Συνεργάζεται με στρατηγικούς πελάτες που χρησιμοποιούν AI/ML για την επίλυση σύνθετων επιχειρηματικών προβλημάτων. Η εμπειρία του έγκειται στην παροχή τεχνικής καθοδήγησης καθώς και στη σχεδιαστική βοήθεια για μικρές έως μεγάλης κλίμακας αναπτύξεις εφαρμογών AI/ML. Οι γνώσεις του κυμαίνονται από την αρχιτεκτονική εφαρμογών έως τα μεγάλα δεδομένα, την ανάλυση και τη μηχανική μάθηση. Του αρέσει να ακούει μουσική ενώ ξεκουράζεται, να βιώνει την ύπαιθρο και να περνά χρόνο με τα αγαπημένα του πρόσωπα.
Ajjay Govindaram είναι Senior Solutions Architect στην AWS. Συνεργάζεται με στρατηγικούς πελάτες που χρησιμοποιούν AI/ML για την επίλυση σύνθετων επιχειρηματικών προβλημάτων. Η εμπειρία του έγκειται στην παροχή τεχνικής καθοδήγησης καθώς και στη σχεδιαστική βοήθεια για μικρές έως μεγάλης κλίμακας αναπτύξεις εφαρμογών AI/ML. Οι γνώσεις του κυμαίνονται από την αρχιτεκτονική εφαρμογών έως τα μεγάλα δεδομένα, την ανάλυση και τη μηχανική μάθηση. Του αρέσει να ακούει μουσική ενώ ξεκουράζεται, να βιώνει την ύπαιθρο και να περνά χρόνο με τα αγαπημένα του πρόσωπα.
 Νικήτα Ίβκιν είναι Ανώτερος Εφαρμοσμένος Επιστήμονας στο Amazon SageMaker Data Wrangler με ενδιαφέροντα για τη μηχανική μάθηση και τους αλγόριθμους καθαρισμού δεδομένων.
Νικήτα Ίβκιν είναι Ανώτερος Εφαρμοσμένος Επιστήμονας στο Amazon SageMaker Data Wrangler με ενδιαφέροντα για τη μηχανική μάθηση και τους αλγόριθμους καθαρισμού δεδομένων.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/machine-learning/simplify-data-prep-for-gen-ai-with-amazon-sagemaker-data-wrangler/

