Store sprogmodeller (LLM'er) trænes generelt på store offentligt tilgængelige datasæt, der er domæneagnostiske. For eksempel, Metas lama modeller trænes på datasæt som f.eks CommonCrawl, C4, Wikipedia og arXiv. Disse datasæt omfatter en bred vifte af emner og domæner. Selvom de resulterende modeller giver forbløffende gode resultater for generelle opgaver, såsom tekstgenerering og enhedsgenkendelse, er der bevis for, at modeller trænet med domænespecifikke datasæt kan forbedre LLM ydeevne yderligere. For eksempel de træningsdata der bruges til BloombergGPT er 51 % domænespecifikke dokumenter, herunder finansielle nyheder, arkiveringer og andet finansielt materiale. Den resulterende LLM overgår LLM'er, der er trænet på ikke-domænespecifikke datasæt, når de testes på finansspecifikke opgaver. Forfatterne af BloombergGPT konkluderede, at deres model overgår alle andre testede modeller til fire af de fem økonomiske opgaver. Modellen gav endnu bedre ydeevne, når den blev testet for Bloombergs interne økonomiske opgaver med en bred margin - så meget som 60 point bedre (ud af 100). Selvom du kan lære mere om de omfattende evalueringsresultater i papir, følgende prøve taget fra BloombergGPT papir kan give dig et glimt af fordelen ved at træne LLM'er ved hjælp af finansielle domænespecifikke data. Som vist i eksemplet gav BloombergGPT-modellen rigtige svar, mens andre ikke-domænespecifikke modeller kæmpede:
Dette indlæg giver en guide til uddannelse af LLM'er specifikt til det finansielle domæne. Vi dækker følgende nøgleområder:
- Dataindsamling og forberedelse – Vejledning om at finde og kurere relevante økonomiske data til effektiv modeltræning
- Kontinuerlig fortræning vs. finjustering – Hvornår skal du bruge hver enkelt teknik til at optimere din LLM's ydeevne
- Effektiv løbende fortræning – Strategier til at strømline den løbende fortræningsproces, hvilket sparer tid og ressourcer
Dette indlæg samler ekspertisen fra det anvendte forskningsteam inden for Amazon Finance Technology og AWS Worldwide Specialist-teamet for den globale finansielle industri. Noget af indholdet er baseret på papiret Effektiv løbende fortræning til opbygning af domænespecifikke store sprogmodeller.
Indsamling og udarbejdelse af økonomidata
Kontinuerlig fortræning af domæne kræver et domænespecifikt datasæt i stor skala af høj kvalitet. Følgende er de vigtigste trin til kurering af domænedatasæt:
- Identificer datakilder – Potentielle datakilder til domænekorpus omfatter åbent web, Wikipedia, bøger, sociale medier og interne dokumenter.
- Domænedatafiltre – Fordi det ultimative mål er at kurere domænekorpus, skal du muligvis anvende yderligere trin for at bortfiltrere prøver, der er irrelevante for måldomænet. Dette reducerer ubrugelig korpus til kontinuerlig fortræning og reducerer uddannelsesomkostninger.
- forbehandling – Du kan overveje en række forbehandlingstrin for at forbedre datakvaliteten og træningseffektiviteten. For eksempel kan visse datakilder indeholde et rimeligt antal støjende tokens; deduplikering betragtes som et nyttigt skridt til at forbedre datakvaliteten og reducere uddannelsesomkostningerne.
For at udvikle finansielle LLM'er kan du bruge to vigtige datakilder: News CommonCrawl og SEC-arkivering. En SEC-arkivering er en finansiel redegørelse eller et andet formelt dokument indsendt til US Securities and Exchange Commission (SEC). Børsnoterede virksomheder er forpligtet til at indgive forskellige dokumenter regelmæssigt. Dette skaber et stort antal dokumenter gennem årene. News CommonCrawl er et datasæt udgivet af CommonCrawl i 2016. Det indeholder nyhedsartikler fra nyhedssider over hele verden.
Nyheder CommonCrawl er tilgængelig på Amazon Simple Storage Service (Amazon S3) i commoncrawl spand kl crawl-data/CC-NEWS/. Du kan få lister over filer ved hjælp af AWS kommandolinjegrænseflade (AWS CLI) og følgende kommando:
In Effektiv løbende fortræning til opbygning af domænespecifikke store sprogmodeller, bruger forfatterne en URL- og søgeordsbaseret tilgang til at filtrere finansielle nyhedsartikler fra generiske nyheder. Specifikt vedligeholder forfatterne en liste over vigtige finansielle nyhedsmedier og et sæt nøgleord relateret til finansielle nyheder. Vi identificerer en artikel som en finansiel nyhed, hvis den enten kommer fra finansielle nyhedsmedier, eller hvis der vises søgeord i URL'en. Denne enkle, men effektive tilgang giver dig mulighed for at identificere finansielle nyheder fra ikke kun finansielle nyhedsmedier, men også finanssektioner af generiske nyhedsmedier.
SEC-ansøgninger er tilgængelige online gennem SEC's EDGAR-database (Electronic Data Gathering, Analysis and Retrieval), som giver åben dataadgang. Du kan skrabe arkiverne fra EDGAR direkte eller bruge API'er i Amazon SageMaker med nogle få linjer kode, for et hvilket som helst tidsrum og for et stort antal tickers (dvs. den SEC-tildelte identifikator). For at lære mere, se SEC-arkivering.
Følgende tabel opsummerer de vigtigste detaljer for begge datakilder.
| . | Nyheder CommonCrawl | SEC arkivering |
| Dækning | 2016-2022 | 1993-2022 |
| Størrelse | 25.8 milliarder ord | 5.1 milliarder ord |
Forfatterne gennemgår et par ekstra forbehandlingstrin, før dataene føres ind i en træningsalgoritme. For det første bemærker vi, at SEC-arkiver indeholder støjende tekst på grund af fjernelse af tabeller og figurer, så forfatterne fjerner korte sætninger, der anses for at være tabel- eller figuretiketter. For det andet anvender vi en lokalitetsfølsom hashing-algoritme til at deduplikere de nye artikler og arkiver. For SEC-arkivering deduplikerer vi på sektionsniveau i stedet for dokumentniveau. Til sidst sammenkæder vi dokumenter i en lang streng, tokeniserer den og deler tokeniseringen i stykker med maksimal inputlængde understøttet af den model, der skal trænes. Dette forbedrer gennemløbet af kontinuerlig fortræning og reducerer træningsomkostningerne.
Kontinuerlig fortræning vs. finjustering
De fleste tilgængelige LLM'er har generelle formål og mangler domænespecifikke evner. Domæne LLM'er har vist betydelige resultater inden for medicinske, finansielle eller videnskabelige domæner. For at en LLM kan erhverve domænespecifik viden, er der fire metoder: træning fra bunden, løbende fortræning, finjustering af instruktion på domæneopgaver og Retrieval Augmented Generation (RAG).
I traditionelle modeller bruges finjustering normalt til at skabe opgavespecifikke modeller for et domæne. Dette betyder, at du skal vedligeholde flere modeller til flere opgaver som f.eks. enhedsudtrækning, hensigtsklassificering, sentimentanalyse eller besvarelse af spørgsmål. Med fremkomsten af LLM'er er behovet for at opretholde separate modeller blevet forældet ved at bruge teknikker som in-context learning eller prompting. Dette sparer den indsats, der kræves for at vedligeholde en stak modeller til relaterede, men forskellige opgaver.
Intuitivt kan du træne LLM'er fra bunden med domænespecifikke data. Selvom det meste af arbejdet med at skabe domæne LLM'er har fokuseret på træning fra bunden, er det uoverkommeligt dyrt. Eksempelvis koster GPT-4-modellen over $ 100 millioner at træne. Disse modeller er trænet på en blanding af åbne domænedata og domænedata. Kontinuerlig præ-træning kan hjælpe modeller med at erhverve domænespecifik viden uden at pådrage sig omkostningerne ved præ-træning fra bunden, fordi du præ-træner et eksisterende åbent domæne LLM på kun domænedataene.
Med instruktionsfinjustering på en opgave kan du ikke få modellen til at erhverve domæneviden, fordi LLM kun erhverver domæneoplysninger indeholdt i instruktionsfinjusteringsdatasættet. Medmindre der anvendes et meget stort datasæt til instruktionsfinjustering, er det ikke nok at tilegne sig domæneviden. Sourcing af højkvalitets instruktionsdatasæt er normalt udfordrende og er grunden til at bruge LLM'er i første omgang. Også finjustering af instruktion på én opgave kan påvirke ydeevnen på andre opgaver (som vist i dette papir). Finjustering af instruktionen er dog mere omkostningseffektiv end nogen af førtræningsalternativerne.
Følgende figur sammenligner traditionel opgavespecifik finjustering. vs in-context læringsparadigme med LLM'er.
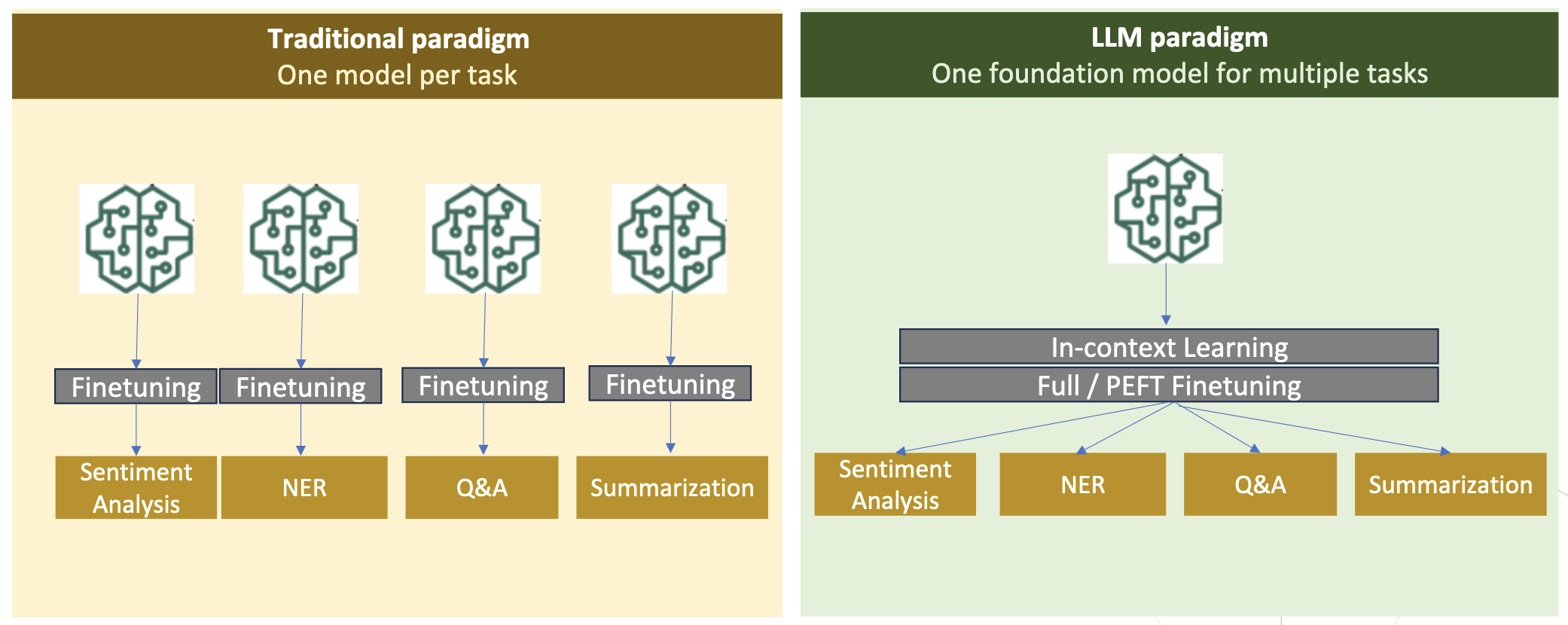 RAG er den mest effektive måde at guide en LLM til at generere svar baseret på et domæne. Selvom det kan guide en model til at generere svar ved at levere fakta fra domænet som hjælpeoplysninger, tilegner den sig ikke det domænespecifikke sprog, fordi LLM stadig er afhængig af ikke-domænesprogstil til at generere svarene.
RAG er den mest effektive måde at guide en LLM til at generere svar baseret på et domæne. Selvom det kan guide en model til at generere svar ved at levere fakta fra domænet som hjælpeoplysninger, tilegner den sig ikke det domænespecifikke sprog, fordi LLM stadig er afhængig af ikke-domænesprogstil til at generere svarene.
Kontinuerlig præ-træning er en mellemvej mellem præ-træning og instruktion finjustering i form af omkostninger, samtidig med at det er et stærkt alternativ til at opnå domænespecifik viden og stil. Det kan give en generel model, over hvilken yderligere instruktionsfinjustering på begrænsede instruktionsdata kan udføres. Kontinuerlig fortræning kan være en omkostningseffektiv strategi for specialiserede domæner, hvor sæt af downstream-opgaver er store eller ukendte, og mærkede instruktionsjusteringsdata er begrænsede. I andre scenarier kan finjustering af instruktion eller RAG være mere egnet.
For at lære mere om finjustering, RAG og modeltræning, se Finjuster en fundamentmodel, Retrieval Augmented Generation (RAG)og Træn en model med Amazon SageMaker, henholdsvis. Til dette indlæg fokuserer vi på effektiv løbende fortræning.
Metode til effektiv løbende fortræning
Kontinuerlig fortræning består af følgende metodologi:
- Domain-Adaptive Continual Pre-training (DACP) – I avisen Effektiv løbende fortræning til opbygning af domænespecifikke store sprogmodeller, fortræner forfatterne løbende Pythia-sprogmodelpakken på det finansielle korpus for at tilpasse det til økonomidomænet. Målet er at skabe finansielle LLM'er ved at tilføre data fra hele det finansielle domæne til en open source-model. Fordi uddannelseskorpuset indeholder alle de kurerede datasæt i domænet, bør den resulterende model tilegne sig økonomispecifik viden og derved blive en alsidig model for forskellige økonomiske opgaver. Dette resulterer i FinPythia-modeller.
- Task-Adaptive Continual Pre-training (TACP) – Forfatterne fortræner modellerne yderligere på mærkede og umærkede opgavedata for at skræddersy dem til specifikke opgaver. Under visse omstændigheder kan udviklere foretrække modeller, der leverer bedre ydeevne på en gruppe af opgaver inden for domænet frem for en domænegenerisk model. TACP er designet som løbende fortræning med det formål at forbedre ydeevnen på målrettede opgaver uden krav til mærkede data. Specifikt fortræner forfatterne løbende de åbne modeller på opgavetokenserne (uden etiketter). Den primære begrænsning af TACP ligger i at konstruere opgavespecifikke LLM'er i stedet for grundlæggende LLM'er, på grund af den eneste brug af umærkede opgavedata til træning. Selvom DACP bruger et meget større korpus, er det uoverkommeligt dyrt. For at balancere disse begrænsninger foreslår forfatterne to tilgange, der sigter mod at opbygge domænespecifikke fundament-LLM'er, mens de bevarer overlegen ydeevne på målopgaver:
- Effektiv opgave-lignende DACP (ETS-DACP) – Forfatterne foreslår at vælge en delmængde af finansielt korpus, der i høj grad ligner opgavedataene ved hjælp af indlejringslighed. Dette undersæt bruges til løbende fortræning for at gøre det mere effektivt. Specifikt fortræner forfatterne løbende det open source LLM på et lille korpus udtrukket fra det finansielle korpus, der er tæt på målopgaverne i distributionen. Dette kan hjælpe med at forbedre opgavens ydeevne, fordi vi anvender modellen til distributionen af opgavetokens på trods af, at mærkede data ikke er påkrævet.
- Effektiv opgaveagnostisk DACP (ETA-DACP) – Forfatterne foreslår at bruge metrikker som forvirring og tokentype-entropi, der ikke kræver opgavedata for at udvælge prøver fra finanskorpus til effektiv kontinuerlig fortræning. Denne tilgang er designet til at håndtere scenarier, hvor opgavedata er utilgængelige eller mere alsidige domænemodeller til det bredere domæne foretrækkes. Forfatterne anvender to dimensioner til at udvælge dataeksempler, der er vigtige for at opnå domæneinformation fra en undergruppe af før-træningsdomænedata: nyhed og mangfoldighed. Nyhed, målt ved forvirringen registreret af målmodellen, refererer til den information, der ikke var set af LLM før. Data med høj nyhed indikerer ny viden for LLM, og sådanne data anses for at være sværere at lære. Dette opdaterer generiske LLM'er med intensiv domæneviden under løbende fortræning. Diversity fanger på den anden side mangfoldigheden af distributioner af tokentyper i domænekorpuset, hvilket er blevet dokumenteret som et nyttigt træk i forskningen i curriculum learning om sprogmodellering.
Følgende figur sammenligner et eksempel på ETS-DACP (venstre) vs. ETA-DACP (højre).
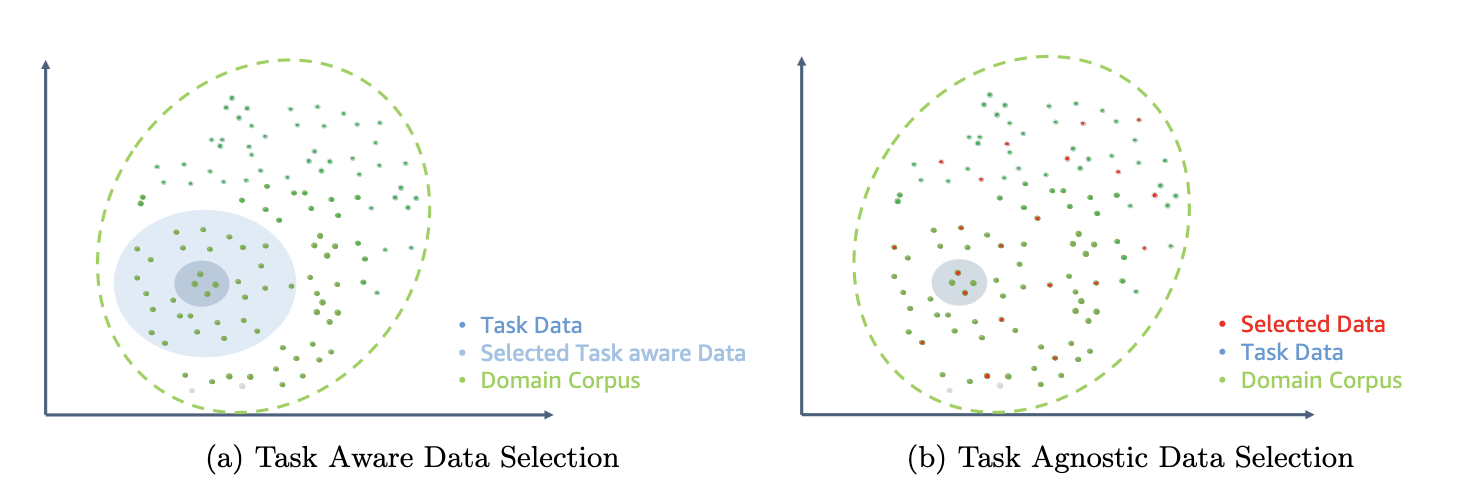
Vi anvender to prøveudtagningsordninger til aktivt at vælge datapunkter fra kurateret finansielt korpus: hård prøveudtagning og blød prøveudtagning. Førstnævnte gøres ved først at rangordne det finansielle korpus efter tilsvarende metrikker og derefter vælge top-k prøverne, hvor k er forudbestemt i henhold til træningsbudgettet. For sidstnævnte tildeler forfatterne prøveudtagningsvægte for hvert datapunkt i henhold til de metriske værdier og prøver derefter tilfældigt k datapunkter for at opfylde træningsbudgettet.
Resultat og analyse
Forfatterne evaluerer de resulterende finansielle LLM'er på en række finansielle opgaver for at undersøge effektiviteten af kontinuerlig fortræning:
- Finansiel sætning Bank – En holdningsklassificeringsopgave om finansielle nyheder.
- FiQA SA – En aspektbaseret holdningsklassificeringsopgave baseret på finansielle nyheder og overskrifter.
- Overskrift – En binær klassifikationsopgave om, hvorvidt en overskrift på en finansiel enhed indeholder visse oplysninger.
- NER – En finansiel navngivet enhedsudvindingsopgave baseret på kreditrisikovurderingsafsnittet i SEC-rapporter. Ord i denne opgave er kommenteret med PER, LOC, ORG og DIVERSE.
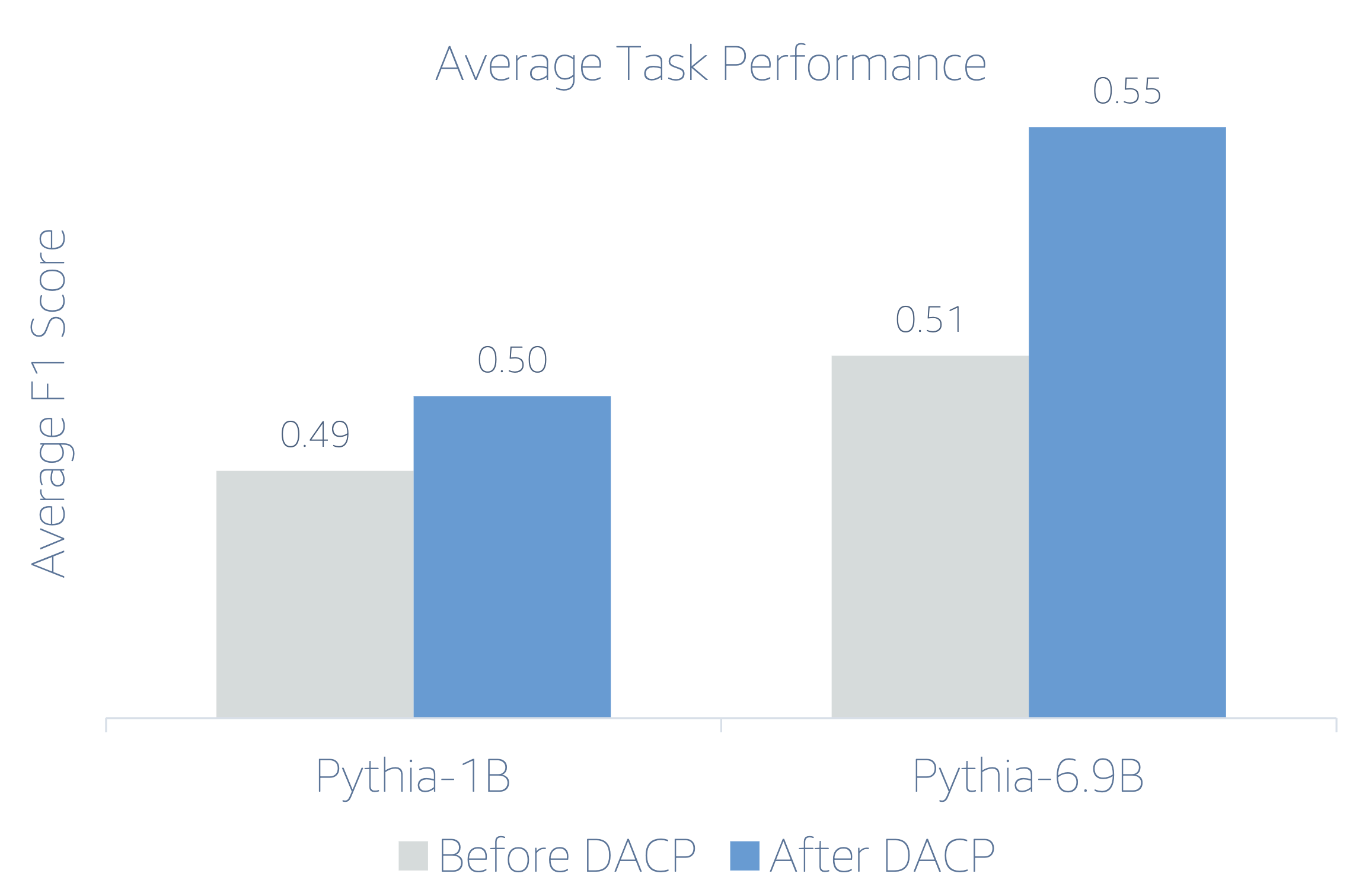
Fordi finansielle LLM'er er instruktion finjusteret, evaluerer forfatterne modeller i en 5-skuds indstilling for hver opgave for robusthedens skyld. I gennemsnit overgår FinPythia 6.9B Pythia 6.9B med 10 % på tværs af fire opgaver, hvilket demonstrerer effektiviteten af domænespecifik kontinuerlig fortræning. For 1B-modellen er forbedringen mindre dyb, men ydeevnen forbedres stadig med 2 % i gennemsnit.
Følgende figur illustrerer ydeevneforskellen før og efter DACP på begge modeller.
Følgende figur viser to kvalitative eksempler genereret af Pythia 6.9B og FinPythia 6.9B. For to finansrelaterede spørgsmål vedrørende en investormanager og et finansielt udtryk forstår Pythia 6.9B ikke udtrykket eller genkender navnet, hvorimod FinPythia 6.9B genererer detaljerede svar korrekt. De kvalitative eksempler viser, at løbende fortræning gør det muligt for LLM'erne at tilegne sig domæneviden under processen.

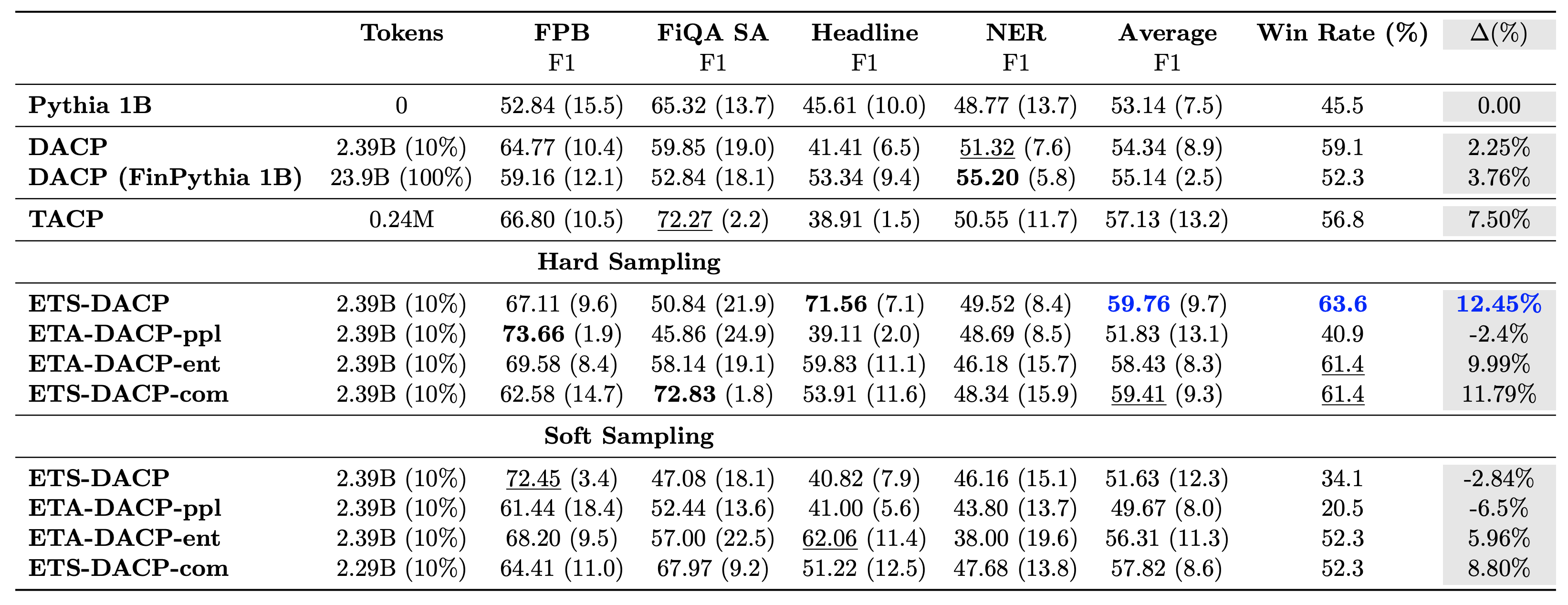
Følgende tabel sammenligner forskellige effektive, løbende fortræningstilgange. ETA-DACP-ppl er ETA-DACP baseret på forvirring (nyhed), og ETA-DACP-ent er baseret på entropi (diversitet). ETS-DACP-com ligner DACP med dataudvælgelse ved at tage et gennemsnit af alle tre metrics. Følgende er et par ting fra resultaterne:
- Dataudvælgelsesmetoder er effektive – De overgår standard løbende fortræning med kun 10 % af træningsdata. Effektiv kontinuerlig fortræning inklusive Task-Similar DACP (ETS-DACP), Task-Agnostic DACP baseret på entropi (ESA-DACP-ent) og Task-Similar DACP baseret på alle tre metrics (ETS-DACP-com) overgår standard DACP i gennemsnit på trods af, at de kun er uddannet på 10 % af det finansielle korpus.
- Opgavebevidst datavalg fungerer bedst i overensstemmelse med forskning i små sprogmodeller – ETS-DACP registrerer den bedste gennemsnitlige ydeevne blandt alle metoderne og, baseret på alle tre målinger, registrerer den næstbedste opgaveydeevne. Dette tyder på, at brug af umærkede opgavedata stadig er en effektiv tilgang til at øge opgavens ydeevne i tilfælde af LLM'er.
- Opgaveagnostisk dataudvælgelse er tæt på andet – ESA-DACP-ent følger udførelsen af den opgavebevidste dataudvælgelsestilgang, hvilket antyder, at vi stadig kunne øge opgavens ydeevne ved aktivt at udvælge prøver af høj kvalitet, der ikke er knyttet til specifikke opgaver. Dette baner vejen for at opbygge finansielle LLM'er for hele domænet, samtidig med at man opnår overlegen opgaveydelse.
Et kritisk spørgsmål vedrørende løbende fortræning er, om det påvirker ydeevnen på ikke-domæneopgaver negativt. Forfatterne evaluerer også den løbende præ-trænede model på fire almindeligt anvendte generiske opgaver: ARC, MMLU, TruthQA og HellaSwag, som måler evnen til at besvare spørgsmål, ræsonnere og færdiggøre. Forfatterne finder, at kontinuerlig fortræning ikke påvirker ikke-domæneydelsen negativt. For flere detaljer, se Effektiv løbende fortræning til opbygning af domænespecifikke store sprogmodeller.
Konklusion
Dette indlæg tilbød indsigt i dataindsamling og løbende fortræningsstrategier til træning af LLM'er til finansielt domæne. Du kan begynde at træne dine egne LLM'er til økonomiske opgaver ved hjælp af Amazon SageMaker træning or Amazonas grundfjeld i dag.
Om forfatterne
 Yong Xie er en anvendt videnskabsmand i Amazon FinTech. Han fokuserer på at udvikle store sprogmodeller og Generative AI-applikationer til finansiering.
Yong Xie er en anvendt videnskabsmand i Amazon FinTech. Han fokuserer på at udvikle store sprogmodeller og Generative AI-applikationer til finansiering.
 Karan Aggarwal er en Senior Applied Scientist hos Amazon FinTech med fokus på Generativ AI til finansieringsbrug. Karan har stor erfaring med tidsserieanalyse og NLP, med særlig interesse i at lære af begrænsede mærkede data
Karan Aggarwal er en Senior Applied Scientist hos Amazon FinTech med fokus på Generativ AI til finansieringsbrug. Karan har stor erfaring med tidsserieanalyse og NLP, med særlig interesse i at lære af begrænsede mærkede data
 Aitzaz Ahmad er en Applied Science Manager hos Amazon, hvor han leder et team af forskere, der bygger forskellige applikationer af Machine Learning og Generative AI i finans. Hans forskningsinteresser er i NLP, Generative AI og LLM Agents. Han modtog sin ph.d. i elektroteknik fra Texas A&M University.
Aitzaz Ahmad er en Applied Science Manager hos Amazon, hvor han leder et team af forskere, der bygger forskellige applikationer af Machine Learning og Generative AI i finans. Hans forskningsinteresser er i NLP, Generative AI og LLM Agents. Han modtog sin ph.d. i elektroteknik fra Texas A&M University.
 Qingwei Li er Machine Learning Specialist hos Amazon Web Services. Han fik sin ph.d. i Operations Research, efter at han brød sin rådgivers forskningsbevillingskonto og undlod at levere den nobelpris, han lovede. I øjeblikket hjælper han kunder inden for finansiel service med at bygge maskinlæringsløsninger på AWS.
Qingwei Li er Machine Learning Specialist hos Amazon Web Services. Han fik sin ph.d. i Operations Research, efter at han brød sin rådgivers forskningsbevillingskonto og undlod at levere den nobelpris, han lovede. I øjeblikket hjælper han kunder inden for finansiel service med at bygge maskinlæringsløsninger på AWS.
 Raghvender Arni leder Customer Acceleration Team (CAT) inden for AWS Industries. CAT er et globalt tværfunktionelt team af kundevendte cloud-arkitekter, softwareingeniører, dataforskere og AI/ML-eksperter og designere, der driver innovation via avanceret prototyping og driver cloud-operationel excellence via specialiseret teknisk ekspertise.
Raghvender Arni leder Customer Acceleration Team (CAT) inden for AWS Industries. CAT er et globalt tværfunktionelt team af kundevendte cloud-arkitekter, softwareingeniører, dataforskere og AI/ML-eksperter og designere, der driver innovation via avanceret prototyping og driver cloud-operationel excellence via specialiseret teknisk ekspertise.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/machine-learning/efficient-continual-pre-training-llms-for-financial-domains/

