Amazon SageMaker Canvas is a no-code workspace that enables analysts and citizen data scientists to generate accurate machine learning (ML) predictions for their business needs. Starting today, SageMaker Canvas supports advanced model build configurations such as selecting a training method (ensemble or hyperparameter optimization) and algorithms, customizing the training and validation data split ratio, and setting limits on autoML iterations and job run time, thus allowing users to customize model building configurations without having to write a single line of code. This flexibility can provide more robust and insightful model development. Non-technical stakeholders can use the no-code features with default settings, while citizen data scientists can experiment with various ML algorithms and techniques, helping them understand which methods work best for their data and optimize to ensure the model’s quality and performance.
In addition to model building configurations, SageMaker Canvas now also provides a model leaderboard. A leaderboard allows you to compare key performance metrics (for example, accuracy, precision, recall, and F1 score) for different models’ configurations to identify the best model for your data, thereby improving transparency into model building and helping you make informed decisions on model choices. You can also view the entire model building workflow, including suggested preprocessing steps, algorithms, and hyperparameter ranges in a notebook. To access these functionalities, sign out and sign back in to SageMaker Canvas and choose Configure model when building models.
In this post, we walk you through the process to use the new SageMaker Canvas advanced model build configurations to initiate an ensemble and hyperparameter optimization (HPO) training.
Solution overview
In this section, we show you step-by-step instructions for the new SageMaker Canvas advanced model build configurations to initiate an ensemble and hyperparameter optimization (HPO) training to analyze our dataset, build high-quality ML models, and see the model leaderboard to decide which model to publish for inference. SageMaker Canvas can automatically select the training method based on the dataset size, or you can select it manually. The choices are:
- Ensemble: Uses the AutoGluon library to train several base models. To find the best combination for your dataset, ensemble mode runs 10 trials with different model and meta parameter settings. It then combines these models using a stacking ensemble method to create an optimal predictive model. In ensemble mode, SageMaker Canvas supports the following types of machine learning algorithms:
- Light GBM: An optimized framework that uses tree-based algorithms with gradient boosting. This algorithm uses trees that grow in breadth rather than depth and is highly optimized for speed.
- CatBoost: A framework that uses tree-based algorithms with gradient boosting. Optimized for handling categorical variables.
- XGBoost: A framework that uses tree-based algorithms with gradient boosting that grows in depth rather than breadth.
- Random forest: A tree-based algorithm that uses several decision trees on random sub-samples of the data with replacement. The trees are split into optimal nodes at each level. The decisions of each tree are averaged together to prevent overfitting and improve predictions.
- Extra trees: A tree-based algorithm that uses several decision trees on the entire dataset. The trees are split randomly at each level. The decisions of each tree are average to prevent overfitting and to improve predictions. Extra trees add a degree of randomization in comparison to the random forest algorithm.
- Linear models: A framework that uses a linear equation to model the relationship between two variables in observed data.
- Neural network torch: A neural network model that’s implemented using Pytorch.
- Neural network fast.ai: A neural network model that’s implemented using fast.ai.
- Hyperparameter optimization (HPO): SageMaker Canvas finds the best version of a model by tuning hyperparameters using Bayesian optimization or multi-fidelity optimization while running training jobs on your dataset. HPO mode selects the algorithms that are most relevant to your dataset and selects the best range of hyperparameters to tune your models. To tune your models, HPO mode runs up to 100 trials (default) to find the optimal hyperparameters settings within the selected range. If your dataset size is less than 100 MB, SageMaker Canvas uses Bayesian optimization. SageMaker Canvas chooses multi-fidelity optimization if your dataset is larger than 100 MB. In multi-fidelity optimization, metrics are continuously emitted from the training containers. A trial that is performing poorly against a selected objective metric is stopped early. A trial that is performing well is allocated more resources. In HPO mode, SageMaker Canvas supports the following types of machine learning algorithms:
- Linear learner: A supervised learning algorithm that can solve either classification or regression problems.
- XGBoost: A supervised learning algorithm that attempts to accurately predict a target variable by combining an ensemble of estimates from a set of simpler and weaker models.
- Deep learning algorithm: A multilayer perceptron (MLP) and feedforward artificial neural network. This algorithm can handle data that is not linearly separable.
- Auto: SageMaker Canvas automatically chooses either ensemble mode or HPO mode based on your dataset size. If your dataset is larger than 100 MB, SageMaker Canvas chooses HPO. Otherwise, it chooses ensemble mode.
Prerequisites
For this post, you must complete the following prerequisites:
- Have an AWS account.
- Set up SageMaker Canvas. See Prerequisites for setting up Amazon SageMaker Canvas.
- Download the classic Titanic dataset to your local computer.
Create a model
We walk you through using the Titanic dataset and SageMaker Canvas to create a model that predicts which passengers survived the Titanic shipwreck. This is a binary classification problem. We focus on creating a Canvas experiment using the ensemble training mode and compare the results of the F1 score and overall runtime with a SageMaker Canvas experiment using HPO training mode (100 trials).
| Column name | Description |
| Passengerid | Identification number |
| Survivied | Survival |
| Pclass | Ticket class |
| Name | Passenger name |
| Sex | Sex |
| Age | Age in years |
| Sibsp | Number of siblings or spouses aboard the Titanic |
| Parch | Number of parents or children aboard the Titanic |
| Ticket | Ticket number |
| Fare | Passenger fair |
| Cabin | Cabin number |
| Emarked | Port of embarkation |
The Titanic dataset has 890 rows and 12 columns. It contains demographic information about the passengers (age, sex, ticket class, and so on) and the Survived (yes/no) target column.
- Start by importing the dataset into SageMaker Canvas. Name the dataset Titanic.

- Select the Titanic dataset and choose Create new model. Enter a name for the model, select Predictive Analysis as the problem type, and choose Create.

- Under Select a column to predict, use the Target column drop down to select Survived. The Survived target column is a binary data type with values of 0 (did not survive) and 1 (survived).
Configure and run the model
In the first experiment, you configure SageMaker Canvas to run an ensemble training on the dataset with accuracy as your objective metric. A higher accuracy score indicates that the model is making more correct predictions, while a lower accuracy score suggests the model is making more errors. Accuracy works well for balanced datasets. For ensemble training, select XGBoost, Random Forest, CatBoost, and Linear Models as your algorithms. Leave the data split at the default 80/20 for training and validation. And finally, configure the training job to run for a maximum job runtime of 1 hour.
- Begin by choosing Configure model.

- This brings up a modal window for Configure model. Select Advanced from the navigation pane.

- Start configuring your model by selecting Objective metric. For this experiment, select Accuracy. The accuracy score tells you how often the model’s predictions are correct overall.

- Select Training method and algorithms and select Ensemble. Ensemble methods in machine learning involve creating multiple models and then combining them to produce improved results. This technique is used to increase prediction accuracy by taking advantage of the strengths of different algorithms. Ensemble methods are known to produce more accurate solutions than a single model would, as demonstrated in various machine learning competitions and real-world applications.

- Select the various algorithms to use for the ensemble. For this experiment, select XGBoost, Linear, CatBoost, and Random Forest. Clear all other algorithms.

- Select Data split from the navigation pane. For this experiment, leave the default training and validation split as 80/20. The next iteration of the experiment uses a different split to see if it results in better model performance.

- Select Max candidates and runtime from the navigation pane and set the Max job runtime to 1 hour and choose Save.

- Choose Standard build to start the build.

At this point, SageMaker Canvas is invoking the model training based on the configuration you provided. Because you specified a max runtime for the training job of 1 hour, SageMaker Canvas will take up to an hour to run through the training job.

Review the results
Upon completion of the training job, SageMaker Canvas automatically brings you back into the Analyze view and shows the objective metrics results you had configured for the model training experiment. In this case, you see that the model accuracy is 86.034 percent.
- Choose the collapse arrow button next to Model leaderboard to review the model performance data.
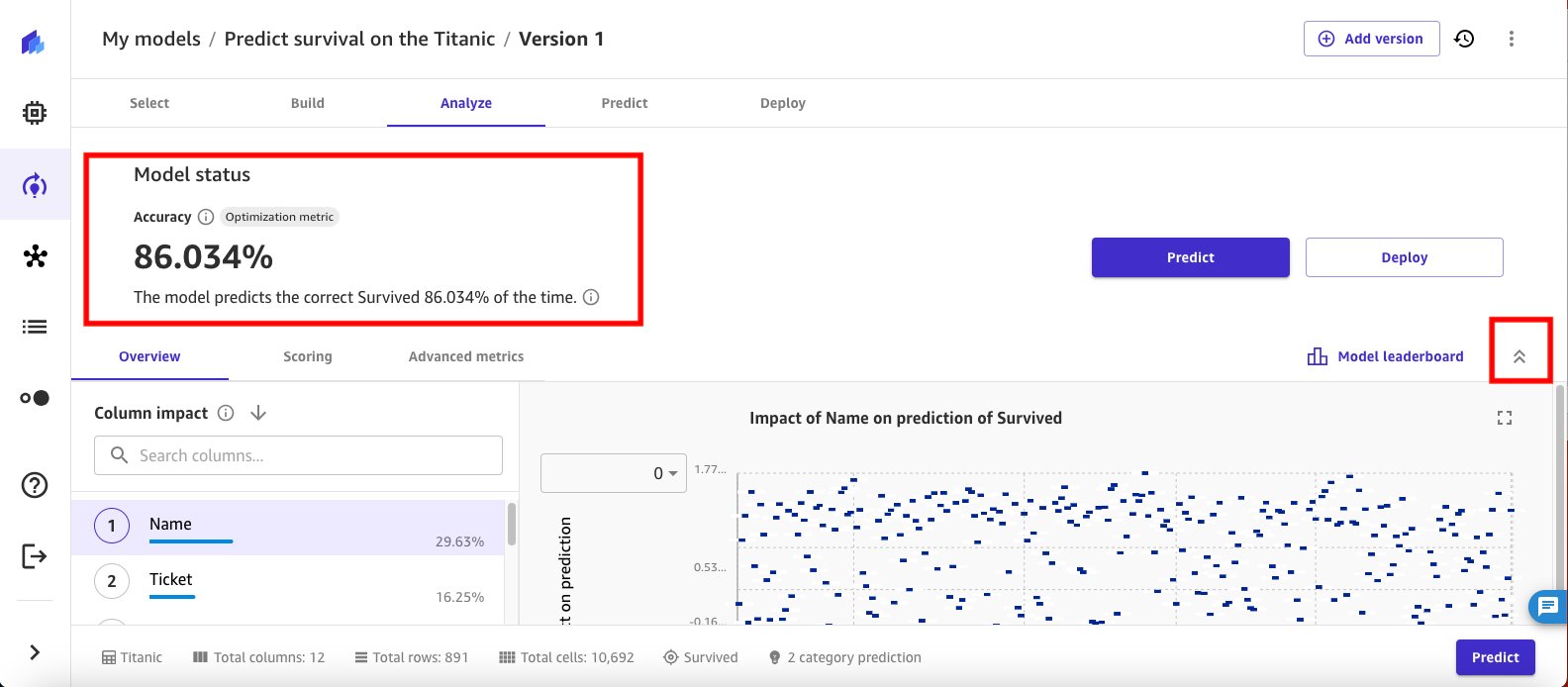
- Select the Scoring tab to dive deeper into the model accuracy insights. The trained model is reporting that it can predict the not survived passengers correctly 89.72 percent of the time.

- Select the Advanced metrics tab to evaluate additional model performance details. Start by selecting Metrics table to review metrics details such as F1, Precision, Recall, and AUC.

- SageMaker Canvas also helps visualize the Confusion matrix for the trained model.

- And visualizes the Precision recall curve. An AUPRC of 0.86 signals high classification accuracy, which is good.

- Choose Model leaderboard to compare key performance metrics (such as accuracy, precision, recall, and F1 score) for different models evaluated by SageMaker Canvas to determine the best model for the data, based on the configuration you set for this experiment. The default model with the best performance is highlighted with the default model label on the model leaderboard.

- You can use the context menu at the side to dive deeper into the details of any of the models or to make a model the default model. Select View model details on the second model in the leaderboard to see details.

- SageMaker Canvas changes the view to show details of the selected model candidate. While details of the default model are already available, the alternate model detail view takes 10–15 minutes to paint the details.

Create a second model
Now that you’ve built, run, and reviewed a model, let’s build a second model for comparison.
- Return to the default model view by choosing X in the top corner. Now, choose Add version to create a new version of the model.

- Select the Titanic dataset you created initially, and then choose Select dataset.

SageMaker Canvas automatically loads the model with the target column already selected. In this second experiment, you switch to HPO training to see if it yields better results for the dataset. For this model, you keep the same objective metrics (Accuracy) for comparison with the first experiment and use the XGBoost algorithm for HPO training. You change the data split for training and validation to 70/30 and configure the max candidates and runtime values for the HPO job to 20 candidates and max job runtime as 1 hour.
Configure and run the model
- Begin the second experiment by choosing Configure model to configure your model training details.
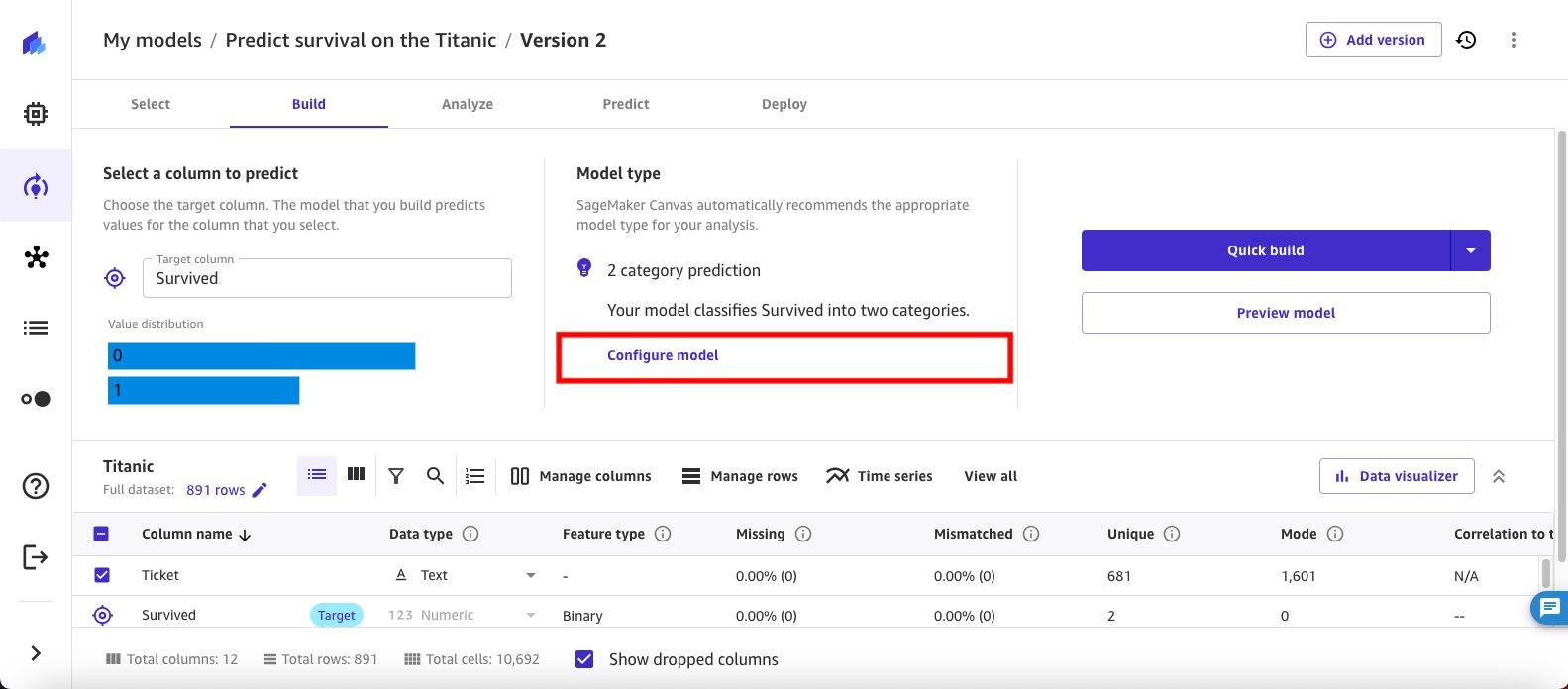
- In the Configure model window, select Objective metric from the navigation pane. For the Objective metric, use the dropdown to select Accuracy, this lets you see and compare all version outputs side by side.
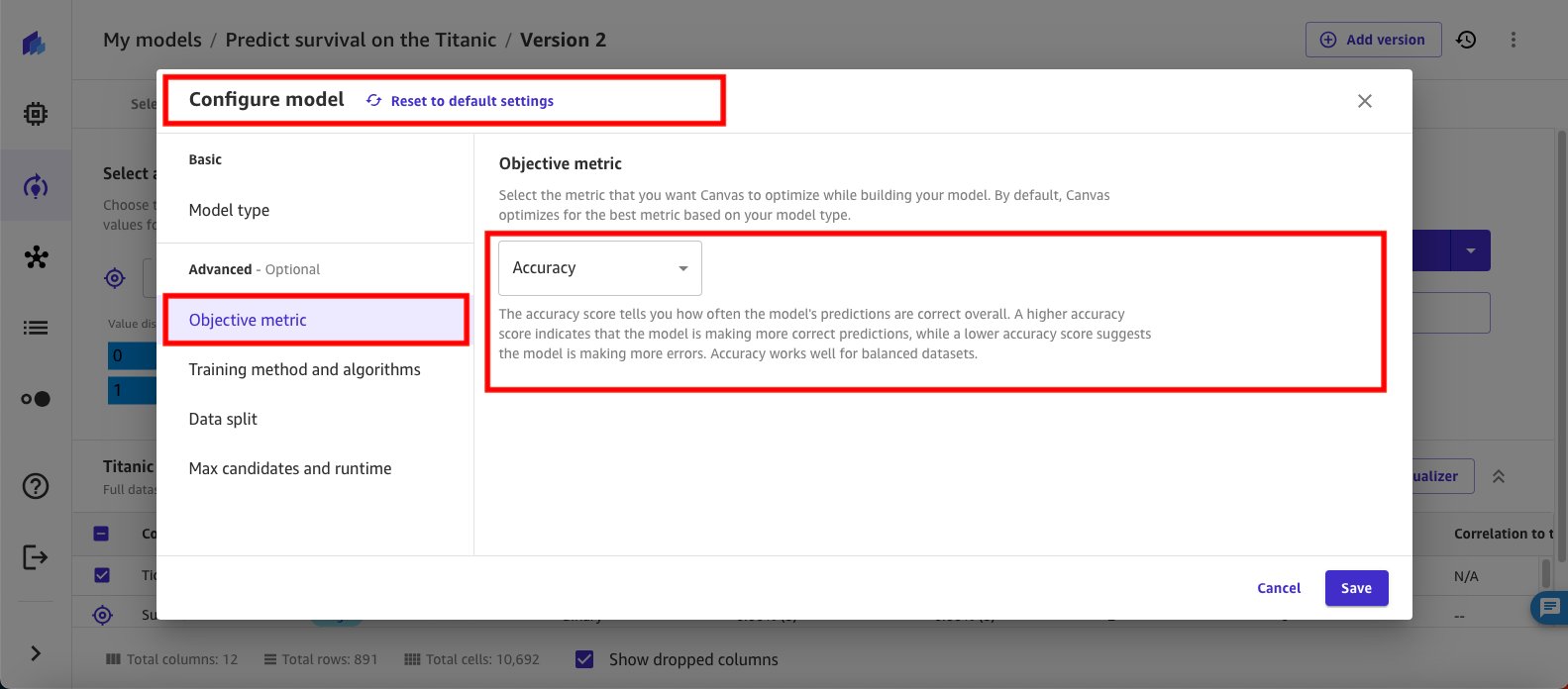
- Select Training method and algorithms. Select Hyperparameter optimization for the training method. Then, scroll down to select the algorithms.

- Select XGBoost for the algorithm. XGBoost provides parallel tree boosting that solves many data science problems quickly and accurately, and offers a large range of hyperparameters that can be tuned to improve and take full advantage of the XGBoost model.

- Select Data Split. For this model, set the training and validation data split to 70/30.

- Select Max candidates and runtime and set the values for the HPO job to 20 for the Max candidates and 1 hour for the Max job runtime. Choose Save to finish configuring the second model.

- Now that you’ve configured the second model, choose Standard build to initiate training.

SageMaker Canvas uses the configuration to start the HPO job. Like the first job, this training job will take up to an hour to complete.

Review the results
When the HPO training job is complete (or the max runtime expires), SageMaker Canvas displays the output of the training job based on with the default model and showing the model’s accuracy score.
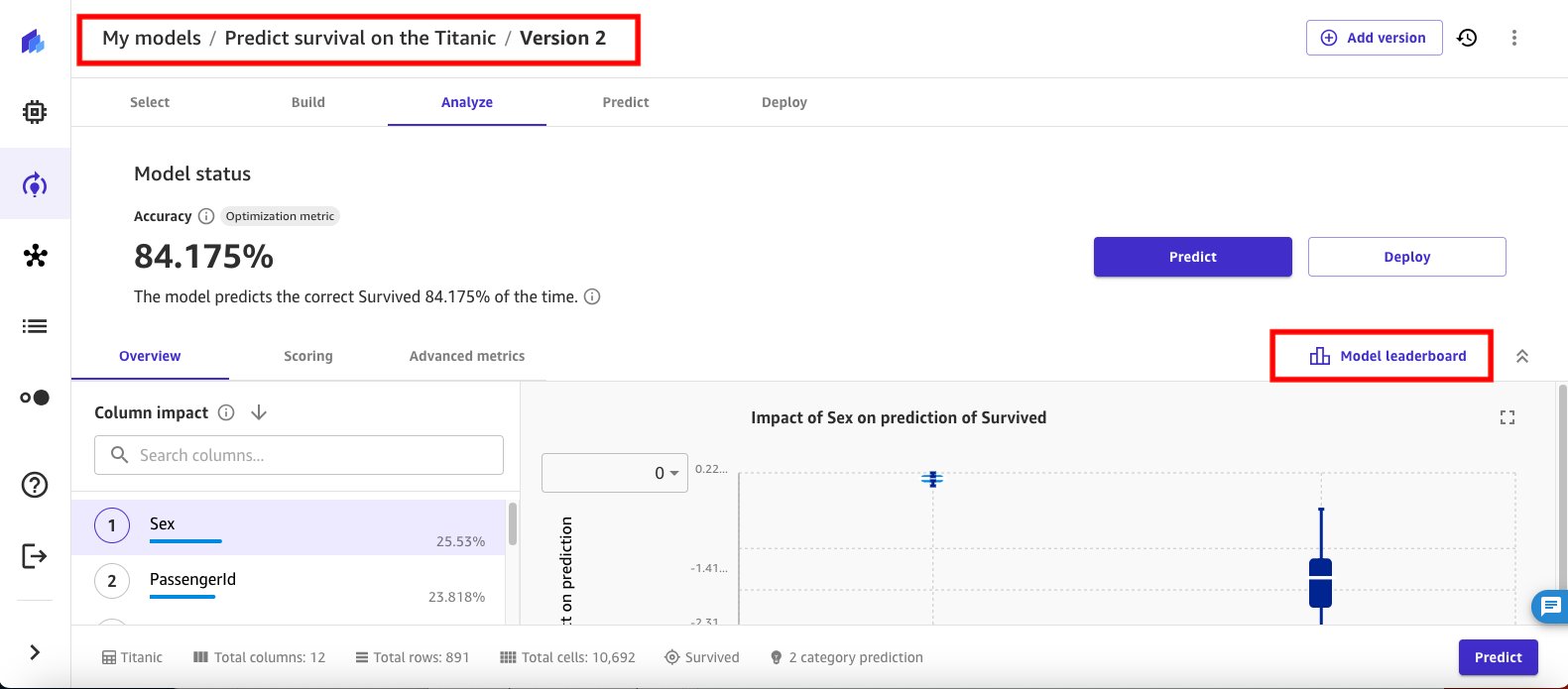
- Choose Model leaderboard to view the list of all 20 candidate models from the HPO training run. The best model, based on the objective to find the best accuracy, is marked as default.

While the accuracy of the default model is the best, another model from the HPO job run has a higher area under the ROC curve (AUC) score. The AUC score is used to evaluate the performance of a binary classification model. A higher AUC indicates that the model is better at distinguishing between the two classes, with 1 being a perfect score and 0.5 indicating a random guess.
- Use the context menu to make the model with the higher AUC the default model. Select the context menu for that model and select Change to default model option in the line menu as shown in Figure 31 that follows.

SageMaker Canvas takes a few minutes to change the selected model to the new default model for version 2 of the experiment and move it to the top of the model list.

Compare the models
At this point, you have two versions of your model and can view them side by side by going to My models in SageMaker Canvas.
- Select Predict survival on the Titanic to see the available model versions.

- There are two versions and their performance is displayed in a tabular format for side-by-side comparison.

- You can see that version 1 of the model (which was trained using ensemble algorithms) has better accuracy. You can now use SageMaker Canvas to generate a SageMaker notebook—with code, comments, and instructions—to customize the AutoGluon trials and run the SageMaker Canvas workflow without writing a single line of code. You can generate the SageMaker notebook by choosing the context menu and selecting View Notebook.

- The SageMaker notebook appears in a pop-up window. The notebook helps you inspect and modify the parameters proposed by SageMaker Canvas. You can interactively select one of the configurations proposed by SageMaker Canvas, modify it, and run a processing job to train models based on the selected configuration in the SageMaker Studio environment.

Inference
Now that you’ve identified the best model, you can use the context menu to deploy it to an endpoint for real-time inferencing.

Or use the context menu to operationalize your ML model in production by registering the machine learning (ML) model to the SageMaker model registry.

Cleanup
To avoid incurring future charges, delete the resources you created while following this post. SageMaker Canvas bills you for the duration of the session, and we recommend signing out of SageMaker Canvas when you’re not using it.
See Logging out of Amazon SageMaker Canvas for more details.
Conclusion
SageMaker Canvas is a powerful tool that democratizes machine learning, catering to both non-technical stakeholders and citizen data scientists. The newly introduced features, including advanced model build configurations and the model leaderboard, elevate the platform’s flexibility and transparency. This enables you to tailor your machine learning models to specific business needs without delving into code. The ability to customize training methods, algorithms, data splits, and other parameters empowers you to experiment with various ML techniques, fostering a deeper understanding of model performance.
The introduction of the model leaderboard is a significant enhancement, providing a clear overview of key performance metrics for different configurations. This transparency allows users to make informed decisions about model choices and optimizations. By displaying the entire model building workflow, including suggested preprocessing steps, algorithms, and hyperparameter ranges in a notebook, SageMaker Canvas facilitates a comprehensive understanding of the model development process.
To start your low-code/no-code ML journey, see Amazon SageMaker Canvas.
Special thanks to everyone who contributed to the launch:
Esha Dutta, Ed Cheung, Max Kondrashov, Allan Johnson, Ridhim Rastogi, Ranga Reddy Pallelra, Ruochen Wen, Ruinong Tian, Sandipan Manna, Renu Rozera, Vikash Garg, Ramesh Sekaran, and Gunjan Garg
About the Authors
 Janisha Anand is a Senior Product Manager in the SageMaker Low/No Code ML team, which includes SageMaker Canvas and SageMaker Autopilot. She enjoys coffee, staying active, and spending time with her family.
Janisha Anand is a Senior Product Manager in the SageMaker Low/No Code ML team, which includes SageMaker Canvas and SageMaker Autopilot. She enjoys coffee, staying active, and spending time with her family.
 Indy Sawhney is a Senior Customer Solutions Leader with Amazon Web Services. Always working backwards from customer problems, Indy advises AWS enterprise customer executives through their unique cloud transformation journey. He has over 25 years of experience helping enterprise organizations adopt emerging technologies and business solutions. Indy is an area-of-depth specialist with the AWS Technical Field Community for artificial intelligence and machine learning (AI/ML), with specialization in generative AI and low-code/no-code (LCNC) SageMaker solutions.
Indy Sawhney is a Senior Customer Solutions Leader with Amazon Web Services. Always working backwards from customer problems, Indy advises AWS enterprise customer executives through their unique cloud transformation journey. He has over 25 years of experience helping enterprise organizations adopt emerging technologies and business solutions. Indy is an area-of-depth specialist with the AWS Technical Field Community for artificial intelligence and machine learning (AI/ML), with specialization in generative AI and low-code/no-code (LCNC) SageMaker solutions.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/build-and-evaluate-machine-learning-models-with-advanced-configurations-using-the-sagemaker-canvas-model-leaderboard/

