Improving how users discover new content is critical to increase user engagement and satisfaction on media platforms. Keyword search alone has challenges capturing semantics and user intent, leading to results that lack relevant context; for example, finding date night or Christmas-themed movies. This can drive lower retention rates if users can’t reliably find the content they want. However, with large language models (LLMs), there is an opportunity to solve these semantic and user intent challenges. By combining embeddings that capture semantics with a technique called Retrieval Augmented Generation (RAG), you can generate more relevant answers based on retrieved context from your own data sources.
In this post, we show you how to securely create a movie chatbot by implementing RAG with your own data using Knowledge Bases for Amazon Bedrock. We use the IMDb and Box Office Mojo dataset to simulate a catalog for media and entertainment customers and showcase how you can build your own RAG solution in just a couple of steps.
Solution overview
The IMDb and Box Office Mojo Movies/TV/OTT licensable data package provides a wide range of entertainment metadata, including over 1.6 billion user ratings; credits for more than 13 million cast and crew members; 10 million movie, TV, and entertainment titles; and global box office reporting data from more than 60 countries. Many AWS media and entertainment customers license IMDb data through AWS Data Exchange to improve content discovery and increase customer engagement and retention.
Introduction to Knowledge Bases for Amazon Bedrock
To equip an LLM with up-to-date proprietary information, organizations use RAG, a technique that involves fetching data from company data sources and enriching the prompt with that data to deliver more relevant and accurate responses. Knowledge Bases for Amazon Bedrock enable a fully managed RAG capability that allows you to customize LLM responses with contextual and relevant company data. Knowledge Bases automate the end-to-end RAG workflow, including ingestion, retrieval, prompt augmentation, and citations, eliminating the need for you to write custom code to integrate data sources and manage queries. Knowledge Bases for Amazon Bedrock also enable multi-turn conversations so that the LLM can answer complex user queries with the correct answer.
We use the following services as part of this solution:
We walk through the following high-level steps:
- Preprocess the IMDb data to create documents from every movie record and upload the data into an Amazon Simple Storage Service (Amazon S3) bucket.
- Create a knowledge base.
- Sync your knowledge base with your data source.
- Use the knowledge base to answer semantic queries about the movie catalog.
Prerequisites
The IMDb data used in this post requires a commercial content license and paid subscription to IMDb and Box Office Mojo Movies/TV/OTT licensing package on AWS Data Exchange. To inquire about a license and access sample data, visit developer.imdb.com. To access the dataset, refer to Power recommendation and search using an IMDb knowledge graph – Part 1 and follow the Access the IMDb data section.
Preprocess the IMDb data
Before we create a knowledge base, we need to preprocess the IMDb dataset into text files and upload them to an S3 bucket. In this post, we simulate a customer catalog using the IMDb dataset. We take 10,000 popular movies from the IMDb dataset for the catalog and build the dataset.
Use the following notebook to create the dataset with additional info like actors, director, and producer names. We use the following code to create a single file for a movie with all the information stored in the file in an unstructured text that can be understood by LLMs:
After you have the data in .txt format, you can upload the data into Amazon S3 using the following command:
Create the IMDb Knowledge Base
Complete the following steps to create your knowledge base:
- On the Amazon Bedrock console, choose Knowledge base in the navigation pane.
- Choose Create knowledge base.
- For Knowledge base name, enter
imdb. - For Knowledge base description, enter an optional description, such as Knowledge base for ingesting and storing imdb data.
- For IAM permissions, select Create and use a new service role, then enter a name for your new service role.
- Choose Next.
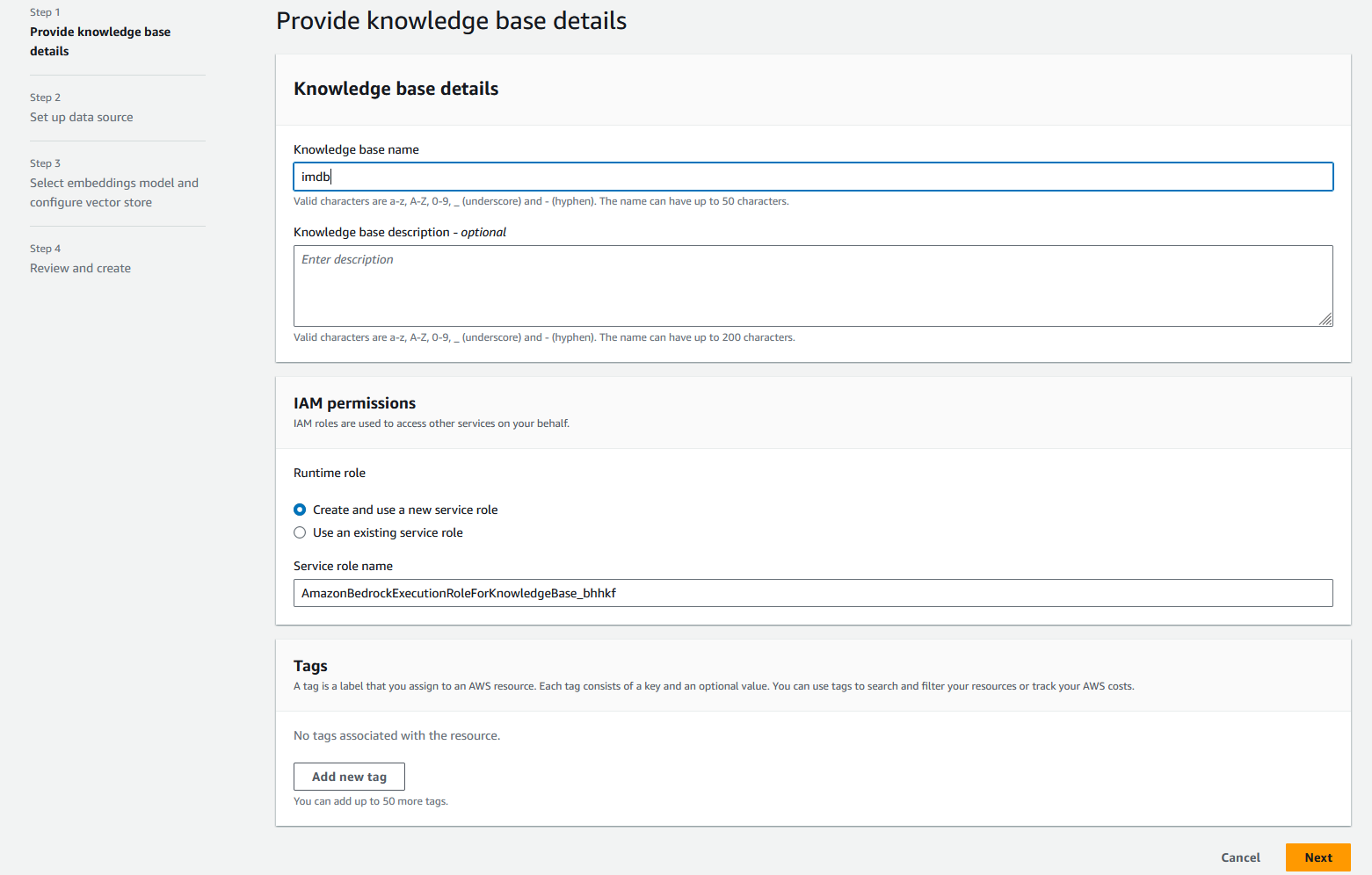
- For Data source name, enter
imdb-s3. - For S3 URI, enter the S3 URI that you uploaded the data to.
- In the Advanced settings – optional section, for Chunking strategy, choose No chunking.
- Choose Next.
Knowledge bases enable you to chunk your documents in smaller segments to make it straightforward for you to process large documents. In our case, we have already chunked the data into a smaller size document (one per movie).

- In the Vector database section, select Quick create a new vector store.
Amazon Bedrock will automatically create a fully managed OpenSearch Serverless vector search collection and configure the settings for embedding your data sources using the chosen Titan Embedding G1 – Text embedding model.
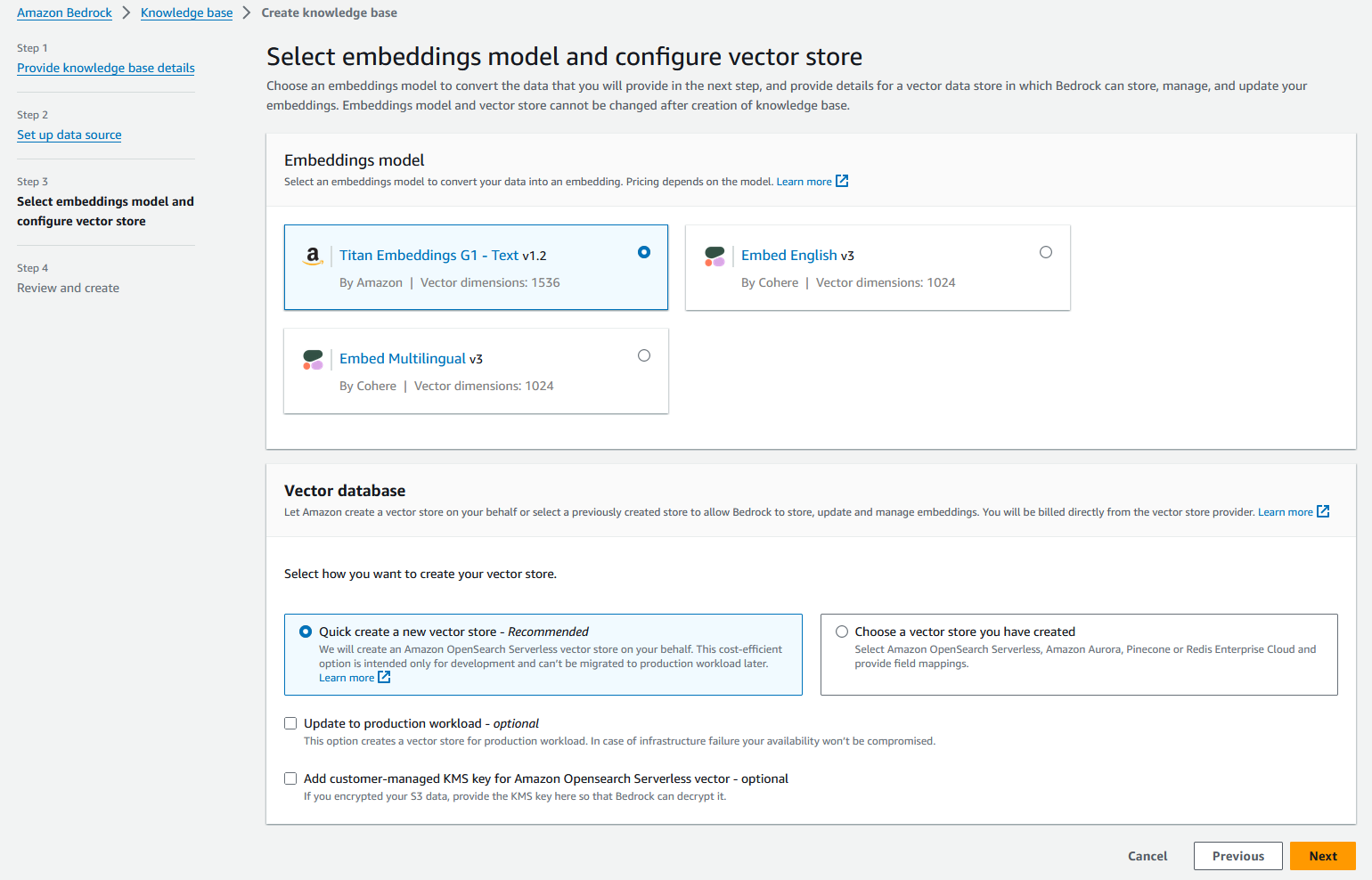
- Choose Next.

- Review your settings and choose Create knowledge base.
Sync your data with the knowledge base
Now that you have created your knowledge base, you can sync the knowledge base with your data.
- On the Amazon Bedrock console, navigate to your knowledge base.
- In the Data source section, choose Sync.

After the data source is synced, you’re ready to query the data.
Improve search using semantic results
Complete the following steps to test the solution and improve your search using semantic results:
- On the Amazon Bedrock console, navigate to your knowledge base.
- Select your knowledge base and choose Test knowledge base.
- Choose Select model, and choose Anthropic Claude v2.1.
- Choose Apply.
Now you are ready to query the data.
We can ask some semantic questions, such as “Recommend me some Christmas themed movies.”
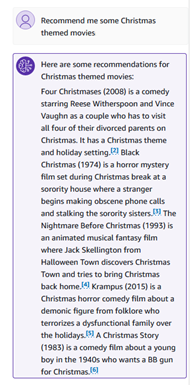
Knowledge base responses contain citations that you can explore for response correctness and factuality.
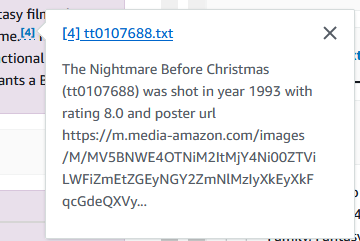
You can also drill down on any information that you need from these movies. In the following example, we ask “who directed nightmare before christmas?”

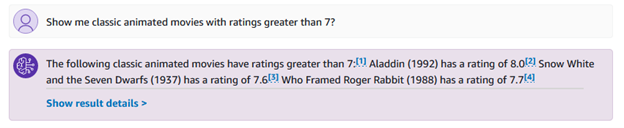
You can also ask more specific questions related to the genres and ratings, such as “show me classic animated movies with ratings greater than 7?”
Augment your knowledge base with agents
Agents for Amazon Bedrock help you automate complex tasks. Agents can break down the user query into smaller tasks and call custom APIs or knowledge bases to supplement information for running actions. With Agents for Amazon Bedrock, developers can integrate intelligent agents into their apps, accelerating the delivery of AI-powered applications and saving weeks of development time. With agents, you can augment your knowledge base by adding more functionality like recommendations from Amazon Personalize for user-specific recommendations or performing actions such as filtering movies based on user needs.
Conclusion
In this post, we showed how to build a conversational movie chatbot using Amazon Bedrock in a few steps to answer semantic search and conversational experiences based on your own data and the IMDb and Box Office Mojo Movies/TV/OTT licensed dataset. In the next post, we go through the process of adding more functionality to your solution using Agents for Amazon Bedrock. To get started with knowledge bases on Amazon Bedrock, refer to Knowledge Bases for Amazon Bedrock.
About the Authors
 Gaurav Rele is a Senior Data Scientist at the Generative AI Innovation Center, where he works with AWS customers across different verticals to accelerate their use of generative AI and AWS Cloud services to solve their business challenges.
Gaurav Rele is a Senior Data Scientist at the Generative AI Innovation Center, where he works with AWS customers across different verticals to accelerate their use of generative AI and AWS Cloud services to solve their business challenges.
 Divya Bhargavi is a Senior Applied Scientist Lead at the Generative AI Innovation Center, where she solves high-value business problems for AWS customers using generative AI methods. She works on image/video understanding & retrieval, knowledge graph augmented large language models and personalized advertising use cases.
Divya Bhargavi is a Senior Applied Scientist Lead at the Generative AI Innovation Center, where she solves high-value business problems for AWS customers using generative AI methods. She works on image/video understanding & retrieval, knowledge graph augmented large language models and personalized advertising use cases.
 Suren Gunturu is a Data Scientist working in the Generative AI Innovation Center, where he works with various AWS customers to solve high-value business problems. He specializes in building ML pipelines using Large Language Models, primarily through Amazon Bedrock and other AWS Cloud services.
Suren Gunturu is a Data Scientist working in the Generative AI Innovation Center, where he works with various AWS customers to solve high-value business problems. He specializes in building ML pipelines using Large Language Models, primarily through Amazon Bedrock and other AWS Cloud services.
 Vidya Sagar Ravipati is a Science Manager at the Generative AI Innovation Center, where he leverages his vast experience in large-scale distributed systems and his passion for machine learning to help AWS customers across different industry verticals accelerate their AI and cloud adoption.
Vidya Sagar Ravipati is a Science Manager at the Generative AI Innovation Center, where he leverages his vast experience in large-scale distributed systems and his passion for machine learning to help AWS customers across different industry verticals accelerate their AI and cloud adoption.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/build-a-movie-chatbot-for-tv-ott-platforms-using-retrieval-augmented-generation-in-amazon-bedrock/

