লার্জ ল্যাঙ্গুয়েজ মডেল (এলএলএম) সাধারণত ডোমেন অজ্ঞেয়বাদী বৃহৎ সর্বজনীনভাবে উপলব্ধ ডেটাসেটগুলিতে প্রশিক্ষিত হয়। উদাহরণ স্বরূপ, মেটার লামা মডেলগুলি যেমন ডেটাসেটের উপর প্রশিক্ষণপ্রাপ্ত হয় কমনক্রল, C4, উইকিপিডিয়া, এবং ArXiv. এই ডেটাসেটগুলি বিষয় এবং ডোমেনগুলির একটি বিস্তৃত পরিসরকে অন্তর্ভুক্ত করে৷ যদিও ফলস্বরূপ মডেলগুলি সাধারণ কাজগুলির জন্য আশ্চর্যজনকভাবে ভাল ফলাফল দেয়, যেমন টেক্সট জেনারেশন এবং সত্তার স্বীকৃতি, তবে প্রমাণ রয়েছে যে ডোমেন-নির্দিষ্ট ডেটাসেটগুলির সাথে প্রশিক্ষিত মডেলগুলি এলএলএম কর্মক্ষমতা আরও উন্নত করতে পারে। উদাহরণস্বরূপ, প্রশিক্ষণের জন্য ব্যবহৃত ডেটা ব্লুমবার্গজিপিটি আর্থিক খবর, ফাইলিং এবং অন্যান্য আর্থিক উপকরণ সহ 51% ডোমেন-নির্দিষ্ট নথি। ফলস্বরূপ এলএলএম অর্থ-নির্দিষ্ট কাজগুলিতে পরীক্ষা করা হলে অ-ডোমেন-নির্দিষ্ট ডেটাসেটে প্রশিক্ষণপ্রাপ্ত এলএলএমগুলিকে ছাড়িয়ে যায়। এর লেখকরা ব্লুমবার্গজিপিটি উপসংহারে পৌঁছেছে যে তাদের মডেলটি পাঁচটি আর্থিক কাজের মধ্যে চারটির জন্য পরীক্ষিত অন্যান্য সমস্ত মডেলকে ছাড়িয়ে গেছে। ব্লুমবার্গের অভ্যন্তরীণ আর্থিক কাজগুলির জন্য বিস্তৃত ব্যবধানে পরীক্ষিত হলে মডেলটি আরও ভাল পারফরম্যান্স প্রদান করে—যতটা 60 পয়েন্ট ভাল (100টির মধ্যে)। যদিও আপনি ব্যাপক মূল্যায়ন ফলাফল সম্পর্কে আরো জানতে পারেন কাগজ, নিম্নলিখিত নমুনা থেকে বন্দী ব্লুমবার্গজিপিটি কাগজ আপনাকে আর্থিক ডোমেন-নির্দিষ্ট ডেটা ব্যবহার করে LLM প্রশিক্ষণের সুবিধার একটি আভাস দিতে পারে। উদাহরণে দেখানো হয়েছে, ব্লুমবার্গজিপিটি মডেল সঠিক উত্তর প্রদান করেছে যখন অন্যান্য অ-ডোমেন-নির্দিষ্ট মডেলগুলি সংগ্রাম করেছে:
এই পোস্টটি বিশেষ করে আর্থিক ডোমেনের জন্য এলএলএম প্রশিক্ষণের জন্য একটি নির্দেশিকা প্রদান করে। আমরা নিম্নলিখিত মূল ক্ষেত্রগুলি কভার করি:
- তথ্য সংগ্রহ এবং প্রস্তুতি - কার্যকর মডেল প্রশিক্ষণের জন্য প্রাসঙ্গিক আর্থিক ডেটা সোর্সিং এবং কিউরেট করার নির্দেশিকা
- ক্রমাগত প্রাক-প্রশিক্ষণ বনাম ফাইন-টিউনিং - কখন আপনার এলএলএম-এর কর্মক্ষমতা অপ্টিমাইজ করতে প্রতিটি কৌশল ব্যবহার করবেন
- দক্ষ ক্রমাগত প্রাক-প্রশিক্ষণ - ক্রমাগত প্রাক-প্রশিক্ষণ প্রক্রিয়াকে স্ট্রিমলাইন করার কৌশল, সময় এবং সংস্থান সাশ্রয়
এই পোস্টটি অ্যামাজন ফাইন্যান্স টেকনোলজি এবং গ্লোবাল ফিনান্সিয়াল ইন্ডাস্ট্রির জন্য AWS ওয়ার্ল্ডওয়াইড স্পেশালিস্ট টিমের মধ্যে প্রয়োগকৃত বিজ্ঞান গবেষণা দলের দক্ষতাকে একত্রিত করে। কিছু বিষয়বস্তু কাগজের উপর ভিত্তি করে ডোমেন নির্দিষ্ট বড় ভাষার মডেল তৈরির জন্য দক্ষ ক্রমাগত প্রাক-প্রশিক্ষণ.
অর্থ সংক্রান্ত তথ্য সংগ্রহ এবং প্রস্তুত করা
ডোমেনের ক্রমাগত প্রাক-প্রশিক্ষণের জন্য একটি বড় মাপের, উচ্চ-মানের, ডোমেন-নির্দিষ্ট ডেটাসেট প্রয়োজন। ডোমেন ডেটাসেট কিউরেশনের জন্য নিম্নলিখিত প্রধান ধাপগুলি হল:
- তথ্য উত্স সনাক্ত করুন - ডোমেইন কর্পাসের সম্ভাব্য ডেটা উৎসের মধ্যে রয়েছে ওপেন ওয়েব, উইকিপিডিয়া, বই, সোশ্যাল মিডিয়া এবং অভ্যন্তরীণ নথি।
- ডোমেন ডেটা ফিল্টার - যেহেতু চূড়ান্ত লক্ষ্য হল ডোমেন কর্পাসকে কিউরেট করা, তাই আপনাকে লক্ষ্য ডোমেনের সাথে অপ্রাসঙ্গিক নমুনাগুলি ফিল্টার করার জন্য অতিরিক্ত পদক্ষেপগুলি প্রয়োগ করতে হতে পারে৷ এটি ক্রমাগত প্রাক-প্রশিক্ষণের জন্য অকেজো কর্পাস হ্রাস করে এবং প্রশিক্ষণের খরচ কমায়।
- প্রাক প্রসেসিং - আপনি ডেটা গুণমান এবং প্রশিক্ষণের দক্ষতা উন্নত করার জন্য প্রি-প্রসেসিং পদক্ষেপগুলির একটি সিরিজ বিবেচনা করতে পারেন। উদাহরণ স্বরূপ, কিছু ডেটা উৎসে ন্যায্য সংখ্যক গোলমাল টোকেন থাকতে পারে; ডেটার গুণমান উন্নত করতে এবং প্রশিক্ষণের খরচ কমাতে ডিডুপ্লিকেশনকে একটি কার্যকর পদক্ষেপ হিসেবে বিবেচনা করা হয়।
আর্থিক LLM বিকাশ করতে, আপনি দুটি গুরুত্বপূর্ণ ডেটা উত্স ব্যবহার করতে পারেন: News CommonCrawl এবং SEC ফাইলিং। একটি এসইসি ফাইলিং হল একটি আর্থিক বিবৃতি বা মার্কিন সিকিউরিটিজ অ্যান্ড এক্সচেঞ্জ কমিশন (এসইসি) এ জমা দেওয়া অন্যান্য আনুষ্ঠানিক নথি। সর্বজনীনভাবে তালিকাভুক্ত কোম্পানিগুলিকে নিয়মিত বিভিন্ন নথি ফাইল করতে হবে। এটি বছরের পর বছর ধরে প্রচুর নথি তৈরি করে। News CommonCrawl হল 2016 সালে CommonCrawl দ্বারা প্রকাশিত একটি ডেটাসেট৷ এতে সারা বিশ্বের সংবাদ সাইটগুলির সংবাদ নিবন্ধ রয়েছে৷
News CommonCrawl এ উপলব্ধ আমাজন সিম্পল স্টোরেজ সার্ভিস (Amazon S3) তে commoncrawl বালতি এ crawl-data/CC-NEWS/. আপনি ব্যবহার করে ফাইলের তালিকা পেতে পারেন এডাব্লুএস কমান্ড লাইন ইন্টারফেস (AWS CLI) এবং নিম্নলিখিত কমান্ড:
In ডোমেন নির্দিষ্ট বড় ভাষার মডেল তৈরির জন্য দক্ষ ক্রমাগত প্রাক-প্রশিক্ষণ, লেখকরা জেনেরিক সংবাদ থেকে আর্থিক সংবাদ নিবন্ধগুলি ফিল্টার করার জন্য একটি URL এবং কীওয়ার্ড-ভিত্তিক পদ্ধতি ব্যবহার করেন। বিশেষ করে, লেখকরা গুরুত্বপূর্ণ আর্থিক সংবাদ আউটলেটগুলির একটি তালিকা এবং আর্থিক খবরের সাথে সম্পর্কিত কীওয়ার্ডগুলির একটি সেট বজায় রাখেন। আমরা একটি নিবন্ধকে আর্থিক সংবাদ হিসাবে চিহ্নিত করি যদি এটি আর্থিক সংবাদ আউটলেট থেকে আসে বা URL-এ কোনো কীওয়ার্ড দেখা যায়। এই সহজ কিন্তু কার্যকর পদ্ধতি আপনাকে শুধুমাত্র আর্থিক নিউজ আউটলেট নয় বরং জেনেরিক নিউজ আউটলেটের অর্থ বিভাগ থেকে আর্থিক খবর সনাক্ত করতে সক্ষম করে।
এসইসি ফাইলিংগুলি এসইসির EDGAR (ইলেক্ট্রনিক ডেটা সংগ্রহ, বিশ্লেষণ এবং পুনরুদ্ধার) ডাটাবেসের মাধ্যমে অনলাইনে পাওয়া যায়, যা খোলা ডেটা অ্যাক্সেস প্রদান করে। আপনি সরাসরি EDGAR থেকে ফাইলিংগুলি স্ক্র্যাপ করতে পারেন, বা এপিআই ব্যবহার করতে পারেন৷ আমাজন সেজমেকার কোডের কয়েকটি লাইন সহ, যেকোনো সময়ের জন্য এবং প্রচুর সংখ্যক টিকারের জন্য (যেমন, এসইসি নির্ধারিত শনাক্তকারী)। আরো জানতে, পড়ুন SEC ফাইলিং পুনরুদ্ধার.
নিম্নলিখিত সারণীতে উভয় ডেটা উৎসের মূল বিবরণ সংক্ষিপ্ত করা হয়েছে।
| . | নিউজ কমনক্রল | এসইসি ফাইলিং |
| কভারেজ | 2016-2022 | 1993-2022 |
| আয়তন | 25.8 বিলিয়ন শব্দ | 5.1 বিলিয়ন শব্দ |
প্রশিক্ষণের অ্যালগরিদমে ডেটা খাওয়ানোর আগে লেখকরা কয়েকটি অতিরিক্ত প্রিপ্রসেসিং ধাপের মধ্য দিয়ে যান। প্রথমত, আমরা লক্ষ্য করি যে SEC ফাইলিংয়ে টেবিল এবং চিত্রগুলি অপসারণের কারণে শোরগোলপূর্ণ পাঠ্য রয়েছে, তাই লেখকরা ছোট বাক্যগুলি সরিয়ে দেন যা টেবিল বা চিত্র লেবেল হিসাবে বিবেচিত হয়। দ্বিতীয়ত, আমরা নতুন নিবন্ধ এবং ফাইলিং ডিডপ্লিকেট করার জন্য একটি স্থানীয় সংবেদনশীল হ্যাশিং অ্যালগরিদম প্রয়োগ করি। SEC ফাইলিংয়ের জন্য, আমরা নথি স্তরের পরিবর্তে বিভাগ স্তরে অনুলিপি করি। সবশেষে, আমরা নথিগুলিকে একটি দীর্ঘ স্ট্রিং-এ সংযুক্ত করি, এটিকে টোকেনাইজ করি এবং টোকেনাইজেশনকে প্রশিক্ষিত করার জন্য মডেল দ্বারা সমর্থিত সর্বাধিক ইনপুট দৈর্ঘ্যের টুকরোগুলিতে ভাগ করি। এটি ক্রমাগত প্রাক-প্রশিক্ষণের থ্রুপুট উন্নত করে এবং প্রশিক্ষণের খরচ কমায়।
ক্রমাগত প্রাক-প্রশিক্ষণ বনাম ফাইন-টিউনিং
বেশিরভাগ উপলব্ধ এলএলএম সাধারণ উদ্দেশ্য এবং ডোমেন-নির্দিষ্ট ক্ষমতার অভাব। ডোমেন এলএলএম মেডিকেল, ফিনান্স বা বৈজ্ঞানিক ডোমেনে যথেষ্ট পারফরম্যান্স দেখিয়েছে। একটি এলএলএম-এর জন্য ডোমেন-নির্দিষ্ট জ্ঞান অর্জনের জন্য, চারটি পদ্ধতি রয়েছে: স্ক্র্যাচ থেকে প্রশিক্ষণ, ক্রমাগত প্রাক-প্রশিক্ষণ, ডোমেন কাজগুলিতে নির্দেশনা ফাইন-টিউনিং এবং পুনরুদ্ধার অগমেন্টেড জেনারেশন (RAG)।
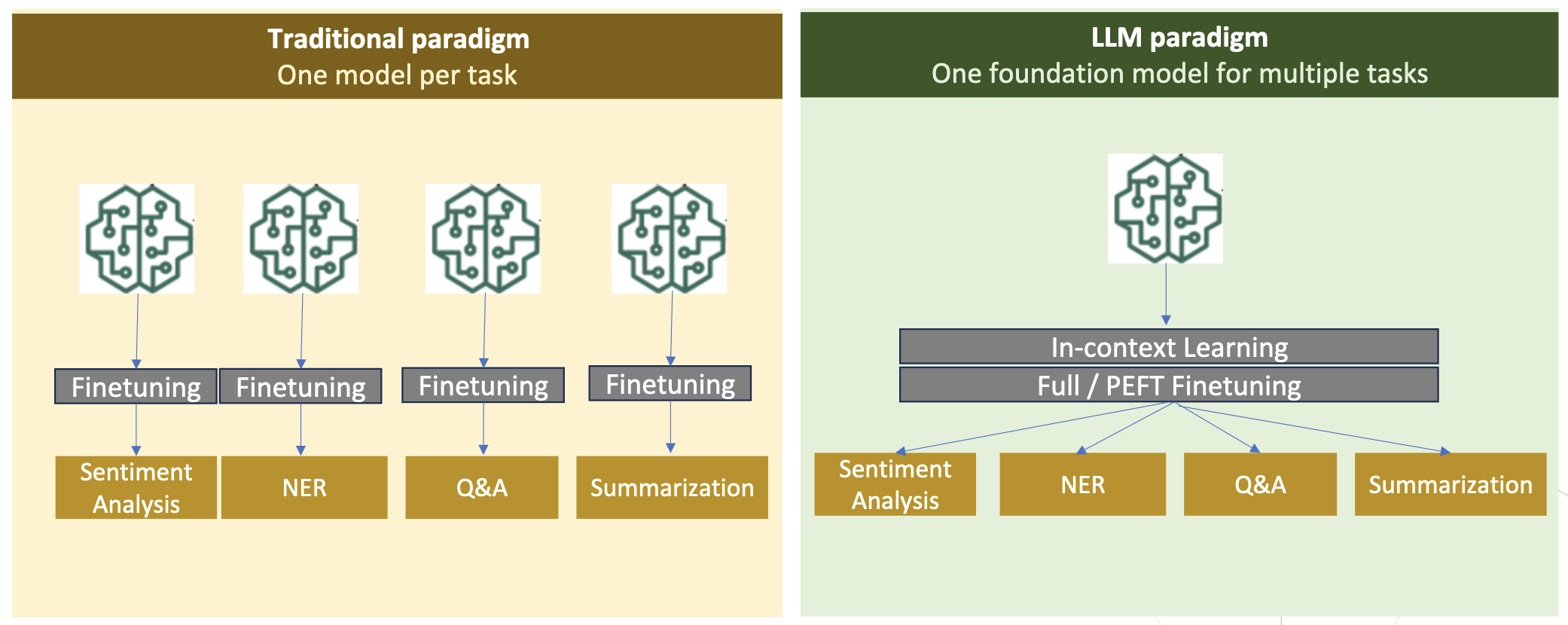
ঐতিহ্যগত মডেলগুলিতে, ফাইন-টিউনিং সাধারণত একটি ডোমেনের জন্য টাস্ক-নির্দিষ্ট মডেল তৈরি করতে ব্যবহৃত হয়। এর অর্থ হল সত্তা নিষ্কাশন, অভিপ্রায় শ্রেণীবিভাগ, অনুভূতি বিশ্লেষণ বা প্রশ্নের উত্তর দেওয়ার মতো একাধিক কাজের জন্য একাধিক মডেল বজায় রাখা। এলএলএম-এর আবির্ভাবের সঙ্গে, ইন-কনটেক্সট লার্নিং বা প্রম্পটিং-এর মতো কৌশল ব্যবহার করে আলাদা মডেল বজায় রাখার প্রয়োজনীয়তা অপ্রচলিত হয়ে পড়েছে। এটি সম্পর্কিত কিন্তু স্বতন্ত্র কাজের জন্য মডেলগুলির একটি স্ট্যাক বজায় রাখার জন্য প্রয়োজনীয় প্রচেষ্টা সংরক্ষণ করে।
স্বজ্ঞাতভাবে, আপনি ডোমেন-নির্দিষ্ট ডেটা দিয়ে স্ক্র্যাচ থেকে এলএলএম প্রশিক্ষণ দিতে পারেন। যদিও ডোমেইন এলএলএম তৈরির বেশিরভাগ কাজ স্ক্র্যাচ থেকে প্রশিক্ষণের উপর দৃষ্টি নিবদ্ধ করেছে, এটি নিষিদ্ধভাবে ব্যয়বহুল। উদাহরণস্বরূপ, GPT-4 মডেলের দাম $ 100 মিলিয়ন প্রশিক্ষণ দিতে. এই মডেলগুলিকে ওপেন ডোমেইন ডেটা এবং ডোমেন ডেটার মিশ্রণে প্রশিক্ষণ দেওয়া হয়। ক্রমাগত প্রাক-প্রশিক্ষণ মডেলগুলিকে স্ক্র্যাচ থেকে প্রাক-প্রশিক্ষণের খরচ ছাড়াই ডোমেন-নির্দিষ্ট জ্ঞান অর্জন করতে সাহায্য করতে পারে কারণ আপনি শুধুমাত্র ডোমেন ডেটার উপর একটি বিদ্যমান ওপেন ডোমেন এলএলএম-কে প্রাক-প্রশিক্ষণ দেন।
নির্দেশনা ফাইন-টিউনিং এর সাথে, আপনি মডেলটিকে ডোমেন জ্ঞান অর্জন করতে পারবেন না কারণ LLM শুধুমাত্র নির্দেশনা ফাইন-টিউনিং ডেটাসেটে থাকা ডোমেন তথ্য অর্জন করে। নির্দেশনা ফাইন-টিউনিংয়ের জন্য একটি খুব বড় ডেটাসেট ব্যবহার করা না হলে, এটি ডোমেন জ্ঞান অর্জনের জন্য যথেষ্ট নয়। উচ্চ-মানের নির্দেশনা ডেটাসেট সোর্স করা সাধারণত চ্যালেঞ্জিং এবং প্রথম স্থানে এলএলএম ব্যবহার করার কারণ। এছাড়াও, একটি টাস্কে নির্দেশনা ফাইন-টিউনিং অন্যান্য কাজের পারফরম্যান্সকে প্রভাবিত করতে পারে (যেমনটিতে দেখা গেছে এই কাগজ) যাইহোক, নির্দেশনা ফাইন-টিউনিং প্রাক-প্রশিক্ষণ বিকল্পগুলির যে কোনোটির চেয়ে বেশি সাশ্রয়ী।
নিম্নলিখিত চিত্রটি ঐতিহ্যগত টাস্ক-নির্দিষ্ট ফাইন-টিউনিং তুলনা করে। বনাম ইন-প্রেক্ষাপটে LLMs সহ শিক্ষার দৃষ্টান্ত।
 একটি ডোমেনে ভিত্তি করে প্রতিক্রিয়া তৈরি করতে LLM-কে গাইড করার সবচেয়ে কার্যকর উপায় হল RAG। যদিও এটি সহায়ক তথ্য হিসাবে ডোমেন থেকে তথ্য প্রদান করে প্রতিক্রিয়া তৈরি করতে একটি মডেলকে গাইড করতে পারে, তবে এটি ডোমেন-নির্দিষ্ট ভাষা অর্জন করে না কারণ LLM এখনও প্রতিক্রিয়া তৈরি করতে অ-ডোমেন ভাষা শৈলীর উপর নির্ভর করে।
একটি ডোমেনে ভিত্তি করে প্রতিক্রিয়া তৈরি করতে LLM-কে গাইড করার সবচেয়ে কার্যকর উপায় হল RAG। যদিও এটি সহায়ক তথ্য হিসাবে ডোমেন থেকে তথ্য প্রদান করে প্রতিক্রিয়া তৈরি করতে একটি মডেলকে গাইড করতে পারে, তবে এটি ডোমেন-নির্দিষ্ট ভাষা অর্জন করে না কারণ LLM এখনও প্রতিক্রিয়া তৈরি করতে অ-ডোমেন ভাষা শৈলীর উপর নির্ভর করে।
ক্রমাগত প্রাক-প্রশিক্ষণ হল প্রাক-প্রশিক্ষণ এবং নির্দেশের মধ্যে একটি মাঝারি স্থল যেখানে খরচের দিক থেকে সূক্ষ্ম টিউনিং করা হয় যখন ডোমেন-নির্দিষ্ট জ্ঞান এবং শৈলী অর্জনের একটি শক্তিশালী বিকল্প। এটি একটি সাধারণ মডেল প্রদান করতে পারে যার উপরে সীমিত নির্দেশের ডেটার উপর আরও নির্দেশনা ফাইন-টিউনিং করা যেতে পারে। অবিচ্ছিন্ন প্রাক-প্রশিক্ষণ বিশেষায়িত ডোমেনের জন্য একটি সাশ্রয়ী কৌশল হতে পারে যেখানে ডাউনস্ট্রিম কাজের সেট বড় বা অজানা এবং লেবেলযুক্ত নির্দেশ টিউনিং ডেটা সীমিত। অন্যান্য পরিস্থিতিতে, নির্দেশ ফাইন-টিউনিং বা RAG আরও উপযুক্ত হতে পারে।
ফাইন-টিউনিং, RAG, এবং মডেল প্রশিক্ষণ সম্পর্কে আরও জানতে, পড়ুন ফাইন-টিউন একটি ভিত্তি মডেল, পুনরুদ্ধার অগমেন্টেড জেনারেশন (RAG), এবং Amazon SageMaker এর সাথে একটি মডেলকে প্রশিক্ষণ দিন, যথাক্রমে। এই পোস্টের জন্য, আমরা দক্ষ ক্রমাগত প্রাক-প্রশিক্ষণের উপর ফোকাস করি।
দক্ষ ক্রমাগত প্রাক-প্রশিক্ষণের পদ্ধতি
ক্রমাগত প্রাক-প্রশিক্ষণ নিম্নলিখিত পদ্ধতি নিয়ে গঠিত:
- ডোমেন-অ্যাডাপ্টিভ কন্টিনিউয়াল প্রি-ট্রেনিং (DACP) - কাগজে ডোমেন নির্দিষ্ট বড় ভাষার মডেল তৈরির জন্য দক্ষ ক্রমাগত প্রাক-প্রশিক্ষণ, লেখকরা ক্রমাগত আর্থিক কর্পাসে Pythia ভাষার মডেল স্যুটটিকে আর্থিক ডোমেনের সাথে খাপ খাইয়ে নিতে প্রাক-প্রশিক্ষণ দিয়ে থাকেন। উদ্দেশ্য পুরো আর্থিক ডোমেন থেকে একটি ওপেন-সোর্স মডেলে ডেটা ফিড করে আর্থিক LLM তৈরি করা। যেহেতু প্রশিক্ষণ কর্পাসে ডোমেনের সমস্ত কিউরেটেড ডেটাসেট রয়েছে, ফলে মডেলটিকে আর্থিক-নির্দিষ্ট জ্ঞান অর্জন করতে হবে, যার ফলে বিভিন্ন আর্থিক কাজের জন্য একটি বহুমুখী মডেল হয়ে উঠবে। এর ফলে FinPythia মডেল হয়।
- টাস্ক-অ্যাডাপ্টিভ কন্টিনিউয়াল প্রি-ট্রেনিং (TACP) - লেখকরা লেবেলযুক্ত এবং লেবেলবিহীন টাস্ক ডেটাতে মডেলগুলিকে নির্দিষ্ট কাজের জন্য উপযোগী করার জন্য আরও প্রাক-প্রশিক্ষণ দেন। নির্দিষ্ট পরিস্থিতিতে, ডেভেলপাররা ডোমেন-জেনেরিক মডেলের পরিবর্তে ইন-ডোমেন টাস্কগুলির একটি গ্রুপে আরও ভাল পারফরম্যান্স সরবরাহকারী মডেল পছন্দ করতে পারে। TACP-কে ক্রমাগত প্রাক-প্রশিক্ষণ হিসাবে ডিজাইন করা হয়েছে যার লক্ষ্য লেবেলযুক্ত ডেটার প্রয়োজনীয়তা ছাড়াই লক্ষ্যযুক্ত কাজগুলিতে কর্মক্ষমতা বাড়ানোর লক্ষ্যে। বিশেষ করে, লেখকরা ক্রমাগত টাস্ক টোকেনে (লেবেল ছাড়া) ওপেন সোর্সড মডেলগুলিকে প্রাক-প্রশিক্ষণ দিয়ে থাকেন। TACP-এর প্রাথমিক সীমাবদ্ধতা হল ফাউন্ডেশন এলএলএম-এর পরিবর্তে টাস্ক-নির্দিষ্ট এলএলএম তৈরি করা, প্রশিক্ষণের জন্য লেবেলবিহীন টাস্ক ডেটার একমাত্র ব্যবহারের কারণে। যদিও DACP একটি অনেক বড় কর্পাস ব্যবহার করে, এটি নিষিদ্ধভাবে ব্যয়বহুল। এই সীমাবদ্ধতাগুলির ভারসাম্য বজায় রাখার জন্য, লেখক দুটি পন্থা প্রস্তাব করেছেন যেগুলির লক্ষ্য ডোমেন-নির্দিষ্ট ফাউন্ডেশন LLM তৈরি করা এবং লক্ষ্য কাজগুলিতে উচ্চতর কর্মক্ষমতা সংরক্ষণ করা:
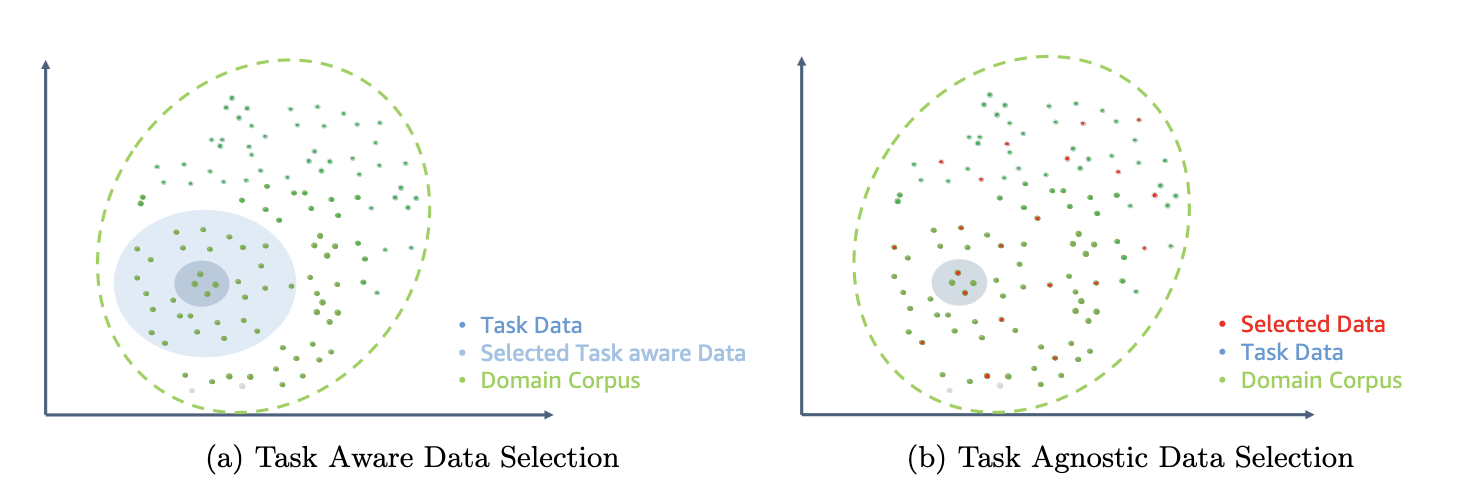
- দক্ষ টাস্ক-অনুরূপ DACP (ETS-DACP) - লেখকরা এম্বেডিং সাদৃশ্য ব্যবহার করে টাস্ক ডেটার সাথে অত্যন্ত সাদৃশ্যপূর্ণ আর্থিক সংস্থার একটি উপসেট নির্বাচন করার প্রস্তাব করেছেন। এই উপসেটটিকে আরও দক্ষ করে তোলার জন্য ক্রমাগত প্রাক-প্রশিক্ষণের জন্য ব্যবহার করা হয়। বিশেষত, লেখকরা ক্রমাগত ওপেন সোর্সড এলএলএম-এর প্রাক-প্রশিক্ষণ দিয়ে থাকেন আর্থিক সংস্থা থেকে প্রাপ্ত একটি ছোট কর্পাসের উপর যা বণ্টনের লক্ষ্যমাত্রার কাছাকাছি। এটি টাস্ক পারফরম্যান্স উন্নত করতে সাহায্য করতে পারে কারণ লেবেলযুক্ত ডেটার প্রয়োজন না হওয়া সত্ত্বেও আমরা টাস্ক টোকেন বিতরণের মডেলটি গ্রহণ করি।
- দক্ষ টাস্ক-অ্যাগনস্টিক DACP (ETA-DACP) - লেখকরা বিভ্রান্তি এবং টোকেন টাইপ এনট্রপির মতো মেট্রিক্স ব্যবহার করার প্রস্তাব করেছেন যাতে দক্ষ ক্রমাগত প্রাক-প্রশিক্ষণের জন্য আর্থিক সংস্থা থেকে নমুনা নির্বাচন করার জন্য টাস্ক ডেটার প্রয়োজন হয় না। এই পদ্ধতিটি এমন পরিস্থিতিতে মোকাবেলা করার জন্য ডিজাইন করা হয়েছে যেখানে টাস্ক ডেটা অনুপলব্ধ বা বিস্তৃত ডোমেনের জন্য আরও বহুমুখী ডোমেন মডেল পছন্দ করা হয়। প্রাক-প্রশিক্ষণ ডোমেন ডেটার একটি উপসেট থেকে ডোমেন তথ্য পাওয়ার জন্য গুরুত্বপূর্ণ ডেটা নমুনা নির্বাচন করতে লেখকরা দুটি মাত্রা গ্রহণ করেন: নতুনত্ব এবং বৈচিত্র্য। অভিনবত্ব, লক্ষ্য মডেল দ্বারা রেকর্ড করা বিভ্রান্তি দ্বারা পরিমাপ করা হয়, সেই তথ্যকে বোঝায় যা LLM এর আগে অদেখা ছিল। উচ্চ অভিনবত্ব সহ ডেটা এলএলএম-এর জন্য অভিনব জ্ঞান নির্দেশ করে এবং এই জাতীয় ডেটা শেখা আরও কঠিন হিসাবে দেখা হয়। এটি ক্রমাগত প্রাক-প্রশিক্ষণের সময় নিবিড় ডোমেন জ্ঞান সহ জেনেরিক এলএলএম আপডেট করে। বৈচিত্র্য, অন্যদিকে, ডোমেন কর্পাসে টোকেন ধরণের বিতরণের বৈচিত্র্যকে ক্যাপচার করে, যা ভাষা মডেলিংয়ের পাঠ্যক্রম শিক্ষার গবেষণায় একটি দরকারী বৈশিষ্ট্য হিসাবে নথিভুক্ত করা হয়েছে।
নিম্নলিখিত চিত্রটি ETS-DACP (বাম) বনাম ETA-DACP (ডান) এর একটি উদাহরণ তুলনা করে।
কিউরেটেড ফাইন্যান্সিয়াল কর্পাস থেকে সক্রিয়ভাবে ডেটা পয়েন্ট নির্বাচন করতে আমরা দুটি স্যাম্পলিং স্কিম গ্রহণ করি: হার্ড স্যাম্পলিং এবং নরম স্যাম্পলিং। প্রাক্তনটি প্রথমে সংশ্লিষ্ট মেট্রিক্সের মাধ্যমে আর্থিক সংস্থার র্যাঙ্কিং করে এবং তারপর টপ-কে নমুনা নির্বাচন করে করা হয়, যেখানে k প্রশিক্ষণের বাজেট অনুযায়ী পূর্বনির্ধারিত। পরেরটির জন্য, লেখকরা মেট্রিক মান অনুসারে প্রতিটি ডেটা পয়েন্টের জন্য নমুনা ওজন নির্ধারণ করেন এবং তারপরে প্রশিক্ষণের বাজেট পূরণের জন্য এলোমেলোভাবে কে ডেটা পয়েন্টের নমুনা দেন।
ফলাফল এবং বিশ্লেষণ
ক্রমাগত প্রাক-প্রশিক্ষণের কার্যকারিতা তদন্ত করার জন্য লেখকরা আর্থিক কাজের একটি অ্যারের উপর ফলস্বরূপ আর্থিক এলএলএমগুলি মূল্যায়ন করেন:
- আর্থিক বাক্যাংশ ব্যাংক - আর্থিক খবরে একটি অনুভূতি শ্রেণীবিভাগের কাজ।
- FiQA SA - আর্থিক খবর এবং শিরোনামের উপর ভিত্তি করে একটি দিক-ভিত্তিক অনুভূতি শ্রেণীবিভাগের কাজ।
- শিরোনাম - একটি আর্থিক সত্তার শিরোনামে নির্দিষ্ট তথ্য রয়েছে কিনা তা নিয়ে একটি বাইনারি শ্রেণীবিভাগের কাজ৷
- নেরের – এসইসি রিপোর্টের ক্রেডিট রিস্ক অ্যাসেসমেন্ট বিভাগের উপর ভিত্তি করে একটি আর্থিক নামে সত্তা নিষ্কাশন কাজ। এই টাস্কের শব্দগুলি PER, LOC, ORG, এবং MISC দিয়ে টীকা করা হয়েছে৷
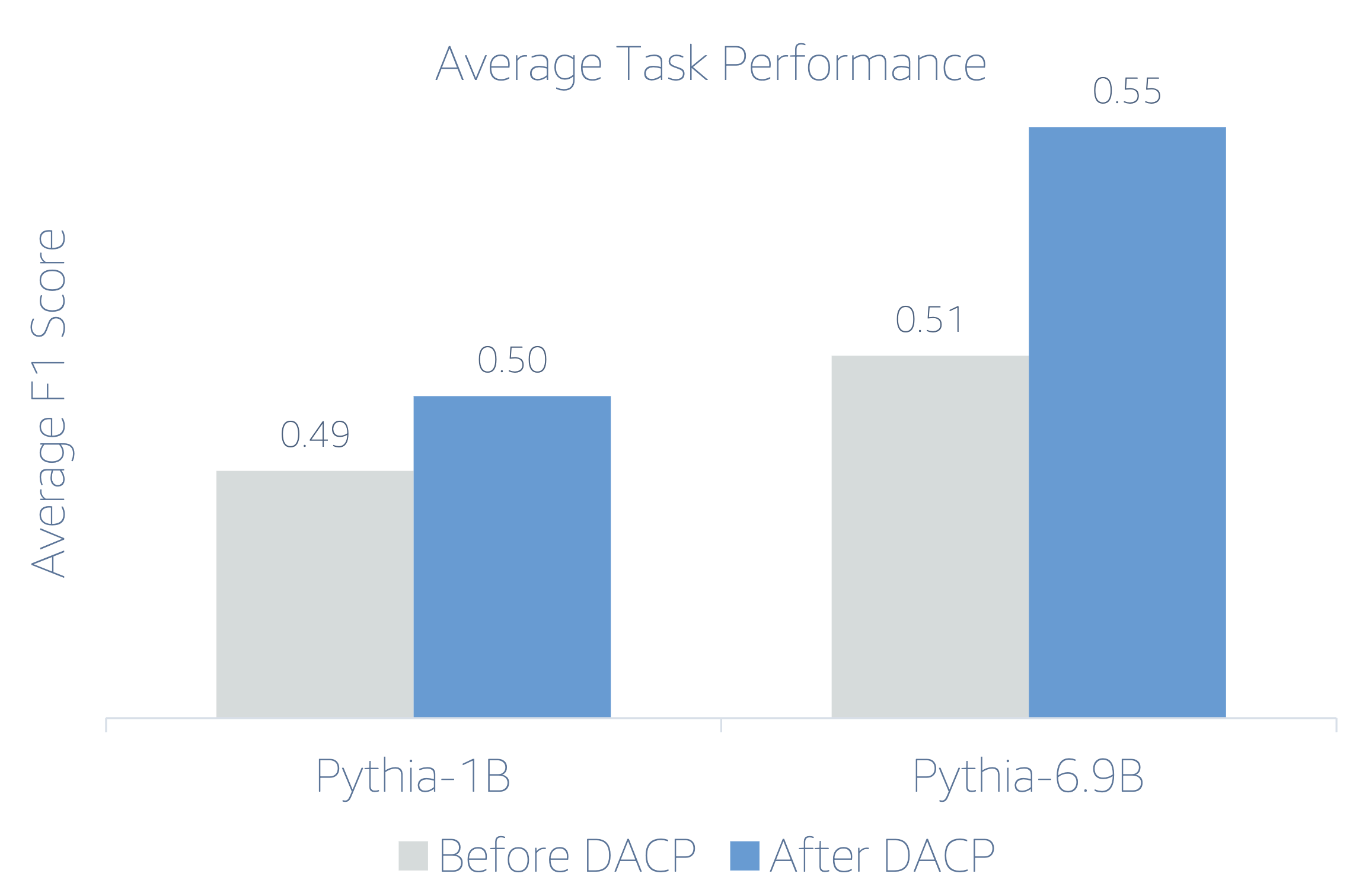
যেহেতু আর্থিক এলএলএমগুলি নির্দেশনা সূক্ষ্ম-সুরক্ষিত, লেখক দৃঢ়তার স্বার্থে প্রতিটি কাজের জন্য 5-শট সেটিংয়ে মডেলগুলিকে মূল্যায়ন করেন। গড়ে, ফিনপিথিয়া 6.9B চারটি কাজের মধ্যে 6.9% দ্বারা Pythia 10B-কে ছাড়িয়ে যায়, যা ডোমেন-নির্দিষ্ট ক্রমাগত প্রাক-প্রশিক্ষণের কার্যকারিতা প্রদর্শন করে। 1B মডেলের জন্য, উন্নতি কম গভীর, কিন্তু কর্মক্ষমতা এখনও গড়ে 2% উন্নত।
নিম্নলিখিত চিত্রটি উভয় মডেলে DACP এর আগে এবং পরে কর্মক্ষমতা পার্থক্যকে চিত্রিত করে।
নিম্নলিখিত চিত্রটি Pythia 6.9B এবং FinPythia 6.9B দ্বারা উত্পন্ন দুটি গুণগত উদাহরণ দেখায়। একজন বিনিয়োগকারী ব্যবস্থাপক এবং একটি আর্থিক পদ সম্পর্কিত দুটি অর্থ-সম্পর্কিত প্রশ্নের জন্য, Pythia 6.9B শব্দটি বোঝে না বা নামটি চিনতে পারে না, যেখানে FinPythia 6.9B সঠিকভাবে বিস্তারিত উত্তর তৈরি করে। গুণগত উদাহরণগুলি দেখায় যে ক্রমাগত প্রাক-প্রশিক্ষণ প্রক্রিয়া চলাকালীন এলএলএম-কে ডোমেন জ্ঞান অর্জন করতে সক্ষম করে।

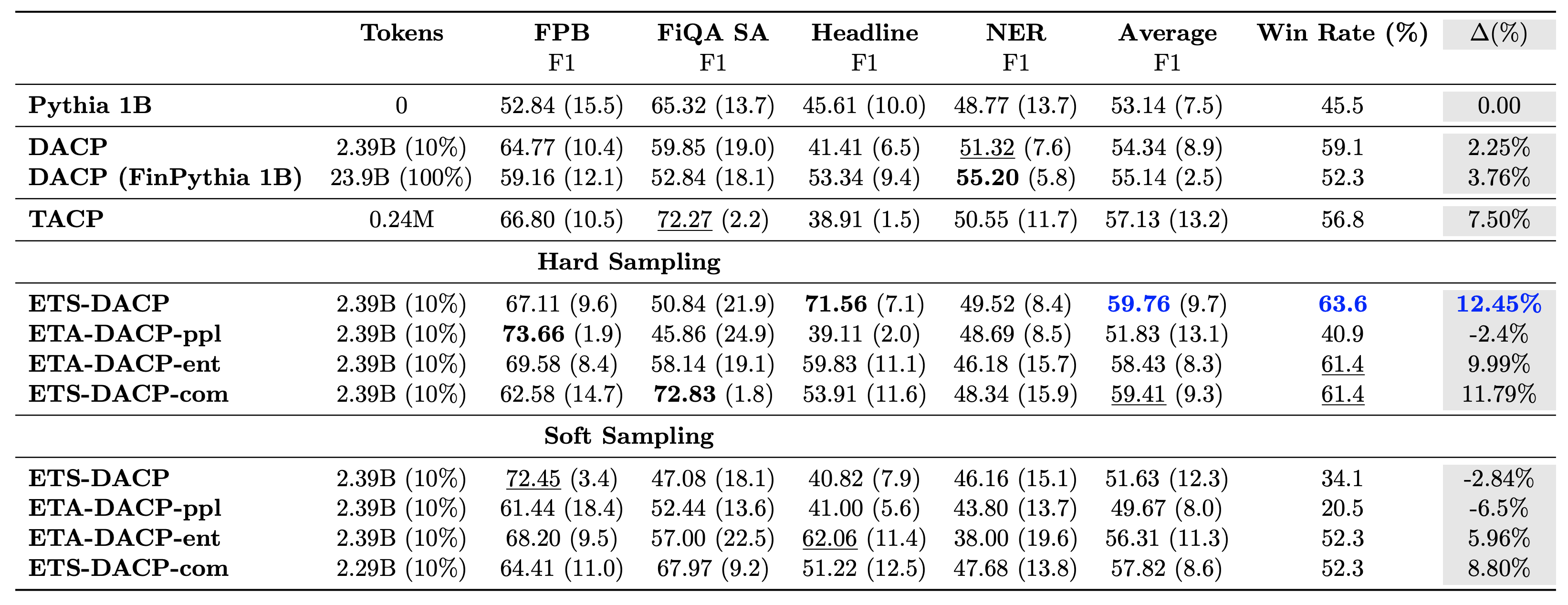
নিম্নলিখিত সারণী বিভিন্ন দক্ষ ক্রমাগত প্রাক-প্রশিক্ষণ পদ্ধতির তুলনা করে। ETA-DACP-ppl হল ETA-DACP ভিত্তিক বিভ্রান্তির (অভিনবত্ব), এবং ETA-DACP-ent হল এনট্রপি (বৈচিত্র্য) এর উপর ভিত্তি করে। ETS-DACP-com তিনটি মেট্রিকের গড় করে ডেটা নির্বাচনের সাথে DACP-এর মতো। নিম্নলিখিত ফলাফল থেকে কিছু গ্রহণ করা হয়েছে:
- তথ্য নির্বাচন পদ্ধতি দক্ষ - তারা মাত্র 10% প্রশিক্ষণের ডেটা দিয়ে মানক ক্রমাগত প্রাক-প্রশিক্ষণকে অতিক্রম করে। টাস্ক-সিমিলার DACP (ETS-DACP), টাস্ক-অ্যাগনস্টিক DACP ভিত্তিক এনট্রপি (ESA-DACP-ent) এবং তিনটি মেট্রিক্সের উপর ভিত্তি করে টাস্ক-সিমিলার DACP সহ দক্ষ ক্রমাগত প্রাক-প্রশিক্ষণ (ETS-DACP-com) স্ট্যান্ডার্ড DACP-কে ছাড়িয়ে যায় তারা আর্থিক সংস্থার মাত্র 10% এ প্রশিক্ষণপ্রাপ্ত হওয়া সত্ত্বেও গড়ে।
- টাস্ক-সচেতন ডেটা নির্বাচন ছোট ভাষা মডেল গবেষণার সাথে সামঞ্জস্যপূর্ণ কাজ করে – ETS-DACP সমস্ত পদ্ধতির মধ্যে সেরা গড় পারফরম্যান্স রেকর্ড করে এবং তিনটি মেট্রিকের উপর ভিত্তি করে দ্বিতীয়-সেরা টাস্ক পারফরম্যান্স রেকর্ড করে। এটি পরামর্শ দেয় যে লেবেলবিহীন টাস্ক ডেটা ব্যবহার করা এখনও LLM-এর ক্ষেত্রে টাস্ক পারফরম্যান্স বাড়ানোর জন্য একটি কার্যকর পদ্ধতি।
- টাস্ক-অজ্ঞেয়বাদী ডেটা নির্বাচন দ্বিতীয় কাছাকাছি – ESA-DACP-ent টাস্ক-সচেতন ডেটা নির্বাচন পদ্ধতির পারফরম্যান্স অনুসরণ করে, যা বোঝায় যে আমরা এখনও নির্দিষ্ট কাজের সাথে আবদ্ধ না থাকা উচ্চ-মানের নমুনাগুলি সক্রিয়ভাবে নির্বাচন করে টাস্ক পারফরম্যান্সকে বাড়িয়ে তুলতে পারি। এটি উচ্চতর টাস্ক পারফরম্যান্স অর্জনের সময় পুরো ডোমেনের জন্য আর্থিক LLM তৈরি করার পথ তৈরি করে।
ক্রমাগত প্রাক-প্রশিক্ষণ সম্পর্কিত একটি গুরুত্বপূর্ণ প্রশ্ন হল এটি নন-ডোমেন কাজগুলির কর্মক্ষমতাকে নেতিবাচকভাবে প্রভাবিত করে কিনা। লেখকরা চারটি ব্যাপকভাবে ব্যবহৃত জেনেরিক কাজগুলির উপর ক্রমাগত প্রাক-প্রশিক্ষিত মডেলের মূল্যায়ন করেন: ARC, MMLU, TruthQA এবং HellaSwag, যা প্রশ্নের উত্তর, যুক্তি এবং সমাপ্তির ক্ষমতা পরিমাপ করে। লেখকরা দেখতে পান যে ক্রমাগত প্রাক-প্রশিক্ষণ অ-ডোমেন কর্মক্ষমতাকে বিরূপভাবে প্রভাবিত করে না। আরো বিস্তারিত জানার জন্য, পড়ুন ডোমেন নির্দিষ্ট বড় ভাষার মডেল তৈরির জন্য দক্ষ ক্রমাগত প্রাক-প্রশিক্ষণ.
উপসংহার
এই পোস্টটি আর্থিক ডোমেনের জন্য LLM-এর প্রশিক্ষণের জন্য ডেটা সংগ্রহ এবং ক্রমাগত প্রাক-প্রশিক্ষণ কৌশলগুলির অন্তর্দৃষ্টি প্রদান করেছে। আপনি ব্যবহার করে আর্থিক কাজের জন্য আপনার নিজের এলএলএম প্রশিক্ষণ শুরু করতে পারেন আমাজন সেজমেকার প্রশিক্ষণ or আমাজন বেডরক আজ.
লেখক সম্পর্কে
 ইয়ং জি অ্যামাজন ফিনটেকের একজন ফলিত বিজ্ঞানী। তিনি অর্থের জন্য বৃহৎ ভাষার মডেল এবং জেনারেটিভ এআই অ্যাপ্লিকেশন বিকাশের দিকে মনোনিবেশ করেন।
ইয়ং জি অ্যামাজন ফিনটেকের একজন ফলিত বিজ্ঞানী। তিনি অর্থের জন্য বৃহৎ ভাষার মডেল এবং জেনারেটিভ এআই অ্যাপ্লিকেশন বিকাশের দিকে মনোনিবেশ করেন।
 করণ আগরওয়াল অ্যামাজন ফিনটেকের একজন সিনিয়র অ্যাপ্লাইড সায়েন্টিস্ট এবং আর্থিক ব্যবহারের ক্ষেত্রে জেনারেটিভ এআই-এর উপর ফোকাস করে৷ করণের টাইম-সিরিজ অ্যানালাইসিস এবং এনএলপিতে ব্যাপক অভিজ্ঞতা রয়েছে, সীমিত লেবেলযুক্ত ডেটা থেকে শেখার বিশেষ আগ্রহের সাথে
করণ আগরওয়াল অ্যামাজন ফিনটেকের একজন সিনিয়র অ্যাপ্লাইড সায়েন্টিস্ট এবং আর্থিক ব্যবহারের ক্ষেত্রে জেনারেটিভ এআই-এর উপর ফোকাস করে৷ করণের টাইম-সিরিজ অ্যানালাইসিস এবং এনএলপিতে ব্যাপক অভিজ্ঞতা রয়েছে, সীমিত লেবেলযুক্ত ডেটা থেকে শেখার বিশেষ আগ্রহের সাথে
 আইতজাজ আহমদ অ্যামাজনের একজন ফলিত বিজ্ঞান ব্যবস্থাপক যেখানে তিনি ফিনান্সে মেশিন লার্নিং এবং জেনারেটিভ এআই-এর বিভিন্ন অ্যাপ্লিকেশন তৈরির বিজ্ঞানীদের একটি দলের নেতৃত্ব দেন। তার গবেষণার আগ্রহ এনএলপি, জেনারেটিভ এআই এবং এলএলএম এজেন্টে। তিনি টেক্সাস এএন্ডএম ইউনিভার্সিটি থেকে ইলেক্ট্রিক্যাল ইঞ্জিনিয়ারিংয়ে পিএইচডি ডিগ্রি লাভ করেন।
আইতজাজ আহমদ অ্যামাজনের একজন ফলিত বিজ্ঞান ব্যবস্থাপক যেখানে তিনি ফিনান্সে মেশিন লার্নিং এবং জেনারেটিভ এআই-এর বিভিন্ন অ্যাপ্লিকেশন তৈরির বিজ্ঞানীদের একটি দলের নেতৃত্ব দেন। তার গবেষণার আগ্রহ এনএলপি, জেনারেটিভ এআই এবং এলএলএম এজেন্টে। তিনি টেক্সাস এএন্ডএম ইউনিভার্সিটি থেকে ইলেক্ট্রিক্যাল ইঞ্জিনিয়ারিংয়ে পিএইচডি ডিগ্রি লাভ করেন।
 কিংওয়েই লি অ্যামাজন ওয়েব সার্ভিসের একজন মেশিন লার্নিং বিশেষজ্ঞ। তিনি তার পিএইচ.ডি. অপারেশনস রিসার্চে যখন তিনি তার উপদেষ্টার গবেষণা অনুদানের হিসাব ভেঙ্গে দেন এবং নোবেল পুরস্কার প্রদানে ব্যর্থ হন তার প্রতিশ্রুতি। বর্তমানে তিনি আর্থিক পরিষেবায় গ্রাহকদের AWS-এ মেশিন লার্নিং সমাধান তৈরি করতে সহায়তা করেন।
কিংওয়েই লি অ্যামাজন ওয়েব সার্ভিসের একজন মেশিন লার্নিং বিশেষজ্ঞ। তিনি তার পিএইচ.ডি. অপারেশনস রিসার্চে যখন তিনি তার উপদেষ্টার গবেষণা অনুদানের হিসাব ভেঙ্গে দেন এবং নোবেল পুরস্কার প্রদানে ব্যর্থ হন তার প্রতিশ্রুতি। বর্তমানে তিনি আর্থিক পরিষেবায় গ্রাহকদের AWS-এ মেশিন লার্নিং সমাধান তৈরি করতে সহায়তা করেন।
 রাঘবেন্দর আর্নি AWS Industries-এর মধ্যে কাস্টমার অ্যাক্সিলারেশন টিম (CAT) নেতৃত্ব দেয়। CAT হল ক্লাউড আর্কিটেক্ট, সফ্টওয়্যার ইঞ্জিনিয়ার, ডেটা সায়েন্টিস্ট এবং AI/ML বিশেষজ্ঞ এবং ডিজাইনারদের মুখোমুখি গ্রাহকদের একটি বিশ্বব্যাপী ক্রস-ফাংশনাল দল যারা উন্নত প্রোটোটাইপিংয়ের মাধ্যমে উদ্ভাবন চালায় এবং বিশেষ প্রযুক্তিগত দক্ষতার মাধ্যমে ক্লাউড অপারেশনাল শ্রেষ্ঠত্ব চালনা করে।
রাঘবেন্দর আর্নি AWS Industries-এর মধ্যে কাস্টমার অ্যাক্সিলারেশন টিম (CAT) নেতৃত্ব দেয়। CAT হল ক্লাউড আর্কিটেক্ট, সফ্টওয়্যার ইঞ্জিনিয়ার, ডেটা সায়েন্টিস্ট এবং AI/ML বিশেষজ্ঞ এবং ডিজাইনারদের মুখোমুখি গ্রাহকদের একটি বিশ্বব্যাপী ক্রস-ফাংশনাল দল যারা উন্নত প্রোটোটাইপিংয়ের মাধ্যমে উদ্ভাবন চালায় এবং বিশেষ প্রযুক্তিগত দক্ষতার মাধ্যমে ক্লাউড অপারেশনাল শ্রেষ্ঠত্ব চালনা করে।
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- PlatoData.Network উল্লম্ব জেনারেটিভ Ai. নিজেকে ক্ষমতায়িত করুন। এখানে প্রবেশ করুন.
- প্লেটোএআইস্ট্রিম। Web3 ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- প্লেটোইএসজি। কার্বন, ক্লিনটেক, শক্তি, পরিবেশ সৌর, বর্জ্য ব্যবস্থাপনা. এখানে প্রবেশ করুন.
- প্লেটো হেলথ। বায়োটেক এবং ক্লিনিক্যাল ট্রায়াল ইন্টেলিজেন্স। এখানে প্রবেশ করুন.
- উত্স: https://aws.amazon.com/blogs/machine-learning/efficient-continual-pre-training-llms-for-financial-domains/

