এটি NXP SEMICONDUCTORS N.V. এবং AWS মেশিন লার্নিং সলিউশন ল্যাব (MLSL) এর যৌথ পোস্ট
মেশিন লার্নিং (ML) বিভিন্ন শিল্পে ব্যবহার করা হচ্ছে ডেটা থেকে ক্রিয়াশীল অন্তর্দৃষ্টি বের করে প্রসেস স্ট্রীমলাইন করতে এবং রাজস্ব উৎপাদন উন্নত করতে। এই পোস্টে, আমরা দেখিয়েছি কিভাবে এনএক্সপি, সেমিকন্ডাক্টর সেক্টরের একটি শিল্প নেতা, এর সাথে সহযোগিতা করেছে AWS মেশিন লার্নিং সলিউশন ল্যাব (MLSL) এর বরাদ্দ অপ্টিমাইজ করার জন্য ML কৌশল ব্যবহার করতে এনএক্সপি গবেষণা ও উন্নয়ন (R&D) বাজেট তাদের বিনিয়োগের উপর দীর্ঘমেয়াদী রিটার্ন (ROI) সর্বোচ্চ করতে।
NXP তার R&D প্রচেষ্টাকে প্রধানত নতুন সেমিকন্ডাক্টর সলিউশনের বিকাশের দিকে পরিচালিত করে যেখানে তারা বৃদ্ধির জন্য উল্লেখযোগ্য সুযোগ দেখতে পায়। বাজারের বৃদ্ধিকে ছাড়িয়ে যাওয়ার জন্য, NXP দ্রুত বর্ধনশীল, বড় বাজারের অংশগুলির উপর জোর দিয়ে শীর্ষস্থানীয় বাজারের অবস্থান প্রসারিত করতে বা তৈরি করতে গবেষণা এবং উন্নয়নে বিনিয়োগ করে। এই ব্যস্ততার জন্য, তারা বিভিন্ন উপাদান গ্রুপ এবং ব্যবসায়িক লাইন জুড়ে নতুন এবং বিদ্যমান পণ্যগুলির জন্য মাসিক বিক্রয় পূর্বাভাস তৈরি করতে চেয়েছিল। এই পোস্টে, আমরা MLSL এবং NXP কিভাবে নিযুক্ত করে তা প্রদর্শন করি আমাজন পূর্বাভাস এবং বিভিন্ন NXP পণ্যের দীর্ঘমেয়াদী বিক্রয় পূর্বাভাসের জন্য অন্যান্য কাস্টম মডেল।
“আমরা অ্যামাজন মেশিন লার্নিং সলিউশন ল্যাবের বিজ্ঞানী এবং বিশেষজ্ঞদের দলের সাথে নিযুক্ত হয়েছি যাতে নতুন পণ্য বিক্রয়ের পূর্বাভাস দেওয়ার জন্য একটি সমাধান তৈরি করা যায় এবং বুঝতে পারি যে কোন অতিরিক্ত বৈশিষ্ট্যগুলি R&D ব্যয়কে অপ্টিমাইজ করার জন্য সিদ্ধান্ত গ্রহণের প্রক্রিয়াকে জানাতে সাহায্য করতে পারে। মাত্র কয়েক সপ্তাহের মধ্যে, দলটি আমাদের কিছু ব্যবসায়িক লাইন, উপাদান গোষ্ঠী এবং [একটি] পৃথক পণ্য স্তরে একাধিক সমাধান এবং বিশ্লেষণ প্রদান করেছে। এমএলএসএল একটি বিক্রয় পূর্বাভাস মডেল সরবরাহ করেছে, যা আমাদের ম্যানুয়াল পূর্বাভাসের পরিপূরক এবং আমাদেরকে আমাজন পূর্বাভাস এবং অ্যামাজন সেজমেকার ব্যবহার করে নতুন মেশিন লার্নিং পদ্ধতির সাথে পণ্যের জীবনচক্রকে মডেল করতে সাহায্য করেছে। আমাদের দলের সাথে একটি অবিচ্ছিন্ন সহযোগিতামূলক কর্মধারা বজায় রাখার সময়, MLSL আমাদের পেশাদারদের উন্নত করতে সাহায্য করেছে যখন এটি AWS অবকাঠামো ব্যবহার করে ML বিকাশের বৈজ্ঞানিক উৎকর্ষ এবং সর্বোত্তম অনুশীলনের ক্ষেত্রে আসে।"
- বার্ট জিম্যান, এনএক্সপি সেমিকন্ডাক্টরের সিটিও অফিসের কৌশলবিদ এবং বিশ্লেষক।
লক্ষ্য এবং ব্যবহার ক্ষেত্রে
NXP এবং MLSL দলের মধ্যে ব্যস্ততার লক্ষ্য হল বিভিন্ন শেষ বাজারে NXP-এর সামগ্রিক বিক্রয়ের পূর্বাভাস দেওয়া। সাধারণভাবে, NXP টিম ম্যাক্রো-স্তরের বিক্রয়ে আগ্রহী যেটিতে বিভিন্ন ব্যবসায়িক লাইনের (BLs) বিক্রয় অন্তর্ভুক্ত রয়েছে, যেটিতে একাধিক উপাদান গোষ্ঠী (MAGs) রয়েছে। অধিকন্তু, NXP টিম নতুন প্রবর্তিত পণ্যের পণ্যের জীবনচক্রের পূর্বাভাস দিতেও আগ্রহী। একটি পণ্যের জীবনচক্র চারটি ভিন্ন পর্যায়ে বিভক্ত (পরিচয়, বৃদ্ধি, পরিপক্কতা এবং হ্রাস)। পণ্যের জীবনচক্রের পূর্বাভাস NXP টিমকে প্রতিটি পণ্যের দ্বারা উত্পন্ন রাজস্ব সনাক্ত করতে সক্ষম করে যাতে R&D কার্যকলাপের জন্য ROI সর্বাধিক করার সর্বোচ্চ সম্ভাবনা সহ সর্বোচ্চ পরিমাণে বিক্রয় বা পণ্য তৈরি করে এমন পণ্যগুলির জন্য আরও R&D তহবিল বরাদ্দ করা যায়। উপরন্তু, তারা একটি মাইক্রো লেভেলে দীর্ঘমেয়াদী বিক্রয়ের ভবিষ্যদ্বাণী করতে পারে, যা তাদের সময়ের সাথে তাদের রাজস্ব কীভাবে পরিবর্তিত হয় তার উপর নিচের দিকে নজর দেয়।
নিম্নলিখিত বিভাগগুলিতে, আমরা দীর্ঘমেয়াদী বিক্রয় পূর্বাভাসের জন্য শক্তিশালী এবং দক্ষ মডেলগুলি বিকাশের সাথে সম্পর্কিত মূল চ্যালেঞ্জগুলি উপস্থাপন করি। আমরা কাঙ্ক্ষিত নির্ভুলতা অর্জনের জন্য নিযুক্ত বিভিন্ন মডেলিং কৌশলগুলির পিছনে অন্তর্দৃষ্টি বর্ণনা করি। তারপরে আমরা আমাদের চূড়ান্ত মডেলগুলির মূল্যায়ন উপস্থাপন করি, যেখানে আমরা NXP-এর বাজার বিশেষজ্ঞদের সাথে বিক্রয় পূর্বাভাসের পরিপ্রেক্ষিতে প্রস্তাবিত মডেলগুলির কর্মক্ষমতা তুলনা করি। আমরা আমাদের অত্যাধুনিক পয়েন্ট ক্লাউড-ভিত্তিক পণ্য জীবনচক্র ভবিষ্যদ্বাণী অ্যালগরিদমের কার্যক্ষমতাও প্রদর্শন করি।
চ্যালেঞ্জ
বিক্রয়ের পূর্বাভাসের জন্য পণ্য-স্তরের মডেলগুলির মতো সূক্ষ্ম-শস্যযুক্ত বা মাইক্রো-লেভেল মডেলিং ব্যবহার করার সময় আমরা যে চ্যালেঞ্জগুলির মুখোমুখি হয়েছিলাম তার মধ্যে একটি ছিল বিক্রয় ডেটা অনুপস্থিত। অনুপস্থিত ডেটা প্রতি মাসে বিক্রয়ের অভাবের ফলাফল। একইভাবে, ম্যাক্রো-স্তরের বিক্রয় পূর্বাভাসের জন্য, ঐতিহাসিক বিক্রয় ডেটার দৈর্ঘ্য সীমিত ছিল। অনুপস্থিত বিক্রয় ডেটা এবং ঐতিহাসিক বিক্রয় ডেটার সীমিত দৈর্ঘ্য উভয়ই 2026 সালে দীর্ঘমেয়াদী বিক্রয় ভবিষ্যদ্বাণীর মডেল নির্ভুলতার পরিপ্রেক্ষিতে উল্লেখযোগ্য চ্যালেঞ্জ তৈরি করে। আমরা অনুসন্ধানমূলক ডেটা বিশ্লেষণ (EDA) এর সময় লক্ষ্য করেছি যে আমরা মাইক্রো-লেভেল সেলস থেকে সরে গিয়ে ( পণ্য স্তর) থেকে ম্যাক্রো-স্তরের বিক্রয় (BL স্তর), অনুপস্থিত মানগুলি কম তাৎপর্যপূর্ণ হয়ে ওঠে। যাইহোক, ঐতিহাসিক বিক্রয় ডেটার সর্বোচ্চ দৈর্ঘ্য (সর্বোচ্চ দৈর্ঘ্য 140 মাস) এখনও মডেলের নির্ভুলতার ক্ষেত্রে উল্লেখযোগ্য চ্যালেঞ্জ তৈরি করেছে।
মডেলিং কৌশল
EDA-এর পর, আমরা BL এবং MAG স্তরে এবং NXP-এর জন্য সবচেয়ে বড় শেষ বাজারগুলির একটির (অটোমোবাইল শেষ বাজার) জন্য পণ্য স্তরে পূর্বাভাস দেওয়ার দিকে মনোনিবেশ করেছি। যাইহোক, আমরা যে সমাধানগুলি তৈরি করেছি তা অন্য প্রান্তের বাজারে প্রসারিত করা যেতে পারে। BL, MAG, বা পণ্য স্তরে মডেলিং এর নিজস্ব সুবিধা এবং অসুবিধা রয়েছে মডেলের কার্যকারিতা এবং ডেটা উপলব্ধতার ক্ষেত্রে। নিম্নলিখিত সারণী প্রতিটি স্তরের জন্য এই ধরনের সুবিধা এবং অসুবিধা সারসংক্ষেপ. ম্যাক্রো-স্তরের বিক্রয় ভবিষ্যদ্বাণীর জন্য, আমরা আমাদের চূড়ান্ত সমাধানের জন্য Amazon Forecast AutoPredictor নিয়োগ করেছি। একইভাবে, মাইক্রো-লেভেল বিক্রয় পূর্বাভাসের জন্য, আমরা একটি অভিনব পয়েন্ট ক্লাউড-ভিত্তিক পদ্ধতির বিকাশ করেছি।

ম্যাক্রো বিক্রয় পূর্বাভাস (উপর-নিচে)
ম্যাক্রো স্তরে দীর্ঘ মেয়াদী বিক্রয় মান (2026) ভবিষ্যদ্বাণী করতে, আমরা Amazon Forecast, GluonTS, এবং N-BEATS (GluonTS এবং PyTorch-এ বাস্তবায়িত) সহ বিভিন্ন পদ্ধতি পরীক্ষা করেছি। সামগ্রিকভাবে, পূর্বাভাস ম্যাক্রো-স্তরের বিক্রয় পূর্বাভাসের জন্য ব্যাকটেস্টিং পদ্ধতির (পরে এই পোস্টে মূল্যায়ন মেট্রিক্স বিভাগে বর্ণিত) উপর ভিত্তি করে অন্যান্য সমস্ত পদ্ধতিকে ছাড়িয়ে গেছে। আমরা মানুষের ভবিষ্যদ্বাণীগুলির বিপরীতে অটোপ্রেডিকরের যথার্থতার তুলনা করেছি।
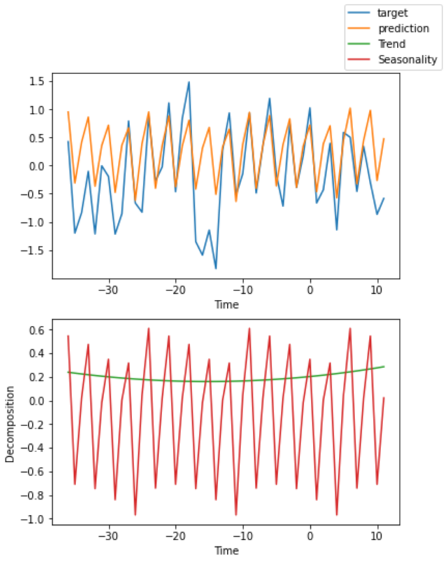
আমরা এর ব্যাখ্যামূলক বৈশিষ্ট্যের কারণে N-BEATS ব্যবহার করার প্রস্তাবও দিয়েছি। N-BEATS একটি খুব সাধারণ কিন্তু শক্তিশালী আর্কিটেকচারের উপর ভিত্তি করে তৈরি করা হয়েছে যা ফিডফরওয়ার্ড নেটওয়ার্কগুলির একটি সংকলন ব্যবহার করে যা পূর্বাভাসের জন্য স্তুপীকৃত অবশিষ্ট ব্লকগুলির সাথে অবশিষ্ট সংযোগগুলি নিয়োগ করে। এই স্থাপত্যটি তার স্থাপত্যে প্রবর্তক পক্ষপাতকে আরও এনকোড করে টাইম সিরিজ মডেলকে প্রবণতা এবং মৌসুমীতা বের করতে সক্ষম করে তোলে (নিচের চিত্রটি দেখুন)। এই ব্যাখ্যাগুলি PyTorch পূর্বাভাস ব্যবহার করে তৈরি করা হয়েছিল।
মাইক্রো বিক্রয় পূর্বাভাস (নিচে-আপ)
এই বিভাগে, আমরা কোল্ড স্টার্ট পণ্য বিবেচনা করার সময় নিম্নলিখিত চিত্রে দেখানো পণ্যের জীবনচক্রের পূর্বাভাস দেওয়ার জন্য একটি অভিনব পদ্ধতি নিয়ে আলোচনা করেছি। আমরা PyTorch অন ব্যবহার করে এই পদ্ধতিটি প্রয়োগ করেছি অ্যামাজন সেজমেকার স্টুডিও. প্রথমত, আমরা একটি পয়েন্ট ক্লাউড-ভিত্তিক পদ্ধতি চালু করেছি। এই পদ্ধতিটি প্রথমে বিক্রয় ডেটাকে একটি পয়েন্ট ক্লাউডে রূপান্তর করে, যেখানে প্রতিটি পয়েন্ট পণ্যের একটি নির্দিষ্ট বয়সে বিক্রয় ডেটা উপস্থাপন করে। পয়েন্ট ক্লাউড-ভিত্তিক নিউরাল নেটওয়ার্ক মডেলটিকে পণ্যের জীবনচক্র বক্ররেখার পরামিতিগুলি শিখতে এই ডেটা ব্যবহার করে আরও প্রশিক্ষিত করা হয়েছে (নিচের চিত্রটি দেখুন)। এই পদ্ধতিতে, আমরা পণ্যের জীবনচক্র বক্ররেখার পূর্বাভাস দেওয়ার জন্য কোল্ড স্টার্ট সমস্যা মোকাবেলা করার জন্য শব্দের ব্যাগ হিসাবে পণ্যের বিবরণ সহ অতিরিক্ত বৈশিষ্ট্যগুলিও অন্তর্ভুক্ত করেছি।

পয়েন্ট ক্লাউড-ভিত্তিক পণ্য জীবনচক্র পূর্বাভাস হিসাবে সময় সিরিজ
পণ্যের জীবনচক্র এবং মাইক্রো-লেভেল বিক্রয়ের পূর্বাভাস দেওয়ার জন্য আমরা একটি অভিনব পয়েন্ট ক্লাউড-ভিত্তিক পদ্ধতির বিকাশ করেছি। কোল্ড স্টার্ট প্রোডাক্ট লাইফসাইকেল ভবিষ্যদ্বাণীর মডেল নির্ভুলতা আরও উন্নত করতে আমরা অতিরিক্ত বৈশিষ্ট্যগুলিও অন্তর্ভুক্ত করেছি। এই বৈশিষ্ট্যগুলির মধ্যে পণ্য তৈরির কৌশল এবং পণ্যগুলির সাথে সম্পর্কিত অন্যান্য সম্পর্কিত শ্রেণীগত তথ্য অন্তর্ভুক্ত রয়েছে। এই ধরনের অতিরিক্ত ডেটা মডেলটিকে একটি নতুন পণ্যের বিক্রির পূর্বাভাস দিতে সাহায্য করতে পারে এমনকি পণ্য বাজারে ছাড়ার আগেই (কোল্ড স্টার্ট)। নিম্নলিখিত চিত্রটি বিন্দু ক্লাউড-ভিত্তিক পদ্ধতির প্রদর্শন করে। মডেলটি ইনপুট হিসাবে পণ্যের স্বাভাবিক বিক্রয় এবং বয়স (পণ্যটি চালু হওয়ার পর থেকে মাসের সংখ্যা) নেয়। এই ইনপুটগুলির উপর ভিত্তি করে, মডেলটি গ্রেডিয়েন্ট ডিসেন্ট ব্যবহার করে প্রশিক্ষণের সময় পরামিতিগুলি শিখে। পূর্বাভাসের পর্যায়ে, কোল্ড স্টার্ট পণ্যের বৈশিষ্ট্য সহ পরামিতিগুলি জীবনচক্রের পূর্বাভাস দেওয়ার জন্য ব্যবহৃত হয়। পণ্য স্তরে ডেটাতে অনুপস্থিত মানগুলির বিপুল সংখ্যক বিদ্যমান টাইম সিরিজ মডেলগুলির প্রায় সমস্তকে নেতিবাচকভাবে প্রভাবিত করে৷ এই অভিনব সমাধানটি লাইফসাইকেল মডেলিং এবং অনুপস্থিত মানগুলিকে প্রশমিত করার জন্য পয়েন্ট ক্লাউড হিসাবে টাইম সিরিজ ডেটা ব্যবহার করার ধারণাগুলির উপর ভিত্তি করে।

নিম্নলিখিত চিত্রটি দেখায় যে কীভাবে আমাদের পয়েন্ট ক্লাউড-ভিত্তিক জীবনচক্র পদ্ধতি অনুপস্থিত ডেটা মানগুলিকে সম্বোধন করে এবং খুব কম প্রশিক্ষণের নমুনা সহ পণ্যের জীবনচক্রের পূর্বাভাস দিতে সক্ষম। X-অক্ষ সময়ের মধ্যে বয়সকে প্রতিনিধিত্ব করে, এবং Y-অক্ষ একটি পণ্যের বিক্রয় প্রতিনিধিত্ব করে। কমলা বিন্দুগুলি প্রশিক্ষণের নমুনাগুলিকে প্রতিনিধিত্ব করে, সবুজ বিন্দুগুলি পরীক্ষার নমুনাগুলিকে প্রতিনিধিত্ব করে এবং নীল রেখাটি মডেল দ্বারা একটি পণ্যের পূর্বাভাসিত জীবনচক্র প্রদর্শন করে৷

প্রণালী বিজ্ঞান
ম্যাক্রো-স্তরের বিক্রয়ের পূর্বাভাস দিতে, আমরা অন্যান্য কৌশলগুলির মধ্যে অ্যামাজন পূর্বাভাস নিযুক্ত করেছি। একইভাবে, মাইক্রো বিক্রয়ের জন্য, আমরা একটি অত্যাধুনিক পয়েন্ট ক্লাউড-ভিত্তিক কাস্টম মডেল তৈরি করেছি। মডেল পারফরম্যান্সের ক্ষেত্রে পূর্বাভাস অন্যান্য সমস্ত পদ্ধতিকে ছাড়িয়ে গেছে। আমরা একটি ডেটা প্রসেসিং পাইপলাইন তৈরি করতে Amazon SageMaker নোটবুক উদাহরণ ব্যবহার করেছি যা Amazon Simple Storage Service (Amazon S3) থেকে প্রশিক্ষণের উদাহরণ বের করেছে। একটি মডেলকে প্রশিক্ষণ দিতে এবং দীর্ঘমেয়াদী বিক্রয়ের পূর্বাভাস দেওয়ার জন্য প্রশিক্ষণের ডেটা আরও পূর্বাভাসের জন্য ইনপুট হিসাবে ব্যবহার করা হয়েছিল।
Amazon Forecast ব্যবহার করে একটি টাইম সিরিজ মডেলের প্রশিক্ষণ দেওয়া তিনটি প্রধান ধাপ নিয়ে গঠিত। প্রথম ধাপে, আমরা Amazon S3 এ ঐতিহাসিক তথ্য আমদানি করেছি। দ্বিতীয়ত, একজন ভবিষ্যদ্বাণীকারীকে ঐতিহাসিক তথ্য ব্যবহার করে প্রশিক্ষণ দেওয়া হয়েছিল। অবশেষে, আমরা পূর্বাভাস তৈরি করতে প্রশিক্ষিত ভবিষ্যদ্বাণীকারীকে মোতায়েন করেছি। এই বিভাগে, আমরা প্রতিটি ধাপের কোড স্নিপেট সহ একটি বিশদ ব্যাখ্যা প্রদান করি।
আমরা সর্বশেষ বিক্রয় ডেটা বের করে শুরু করেছি। এই ধাপে সঠিক বিন্যাসে Amazon S3 এ ডেটাসেট আপলোড করা অন্তর্ভুক্ত। আমাজন পূর্বাভাস ইনপুট হিসাবে তিনটি কলাম নেয়: টাইমস্ট্যাম্প, আইটেম_আইডি এবং লক্ষ্য_মান (বিক্রয় ডেটা)। টাইমস্ট্যাম্প কলামে বিক্রয়ের সময় থাকে, যা প্রতি ঘণ্টায়, প্রতিদিনের মতো ফর্ম্যাট করা যেতে পারে। আইটেম_আইডি কলামে বিক্রি হওয়া আইটেমগুলির নাম রয়েছে এবং লক্ষ্য_মান কলামে বিক্রয় মান রয়েছে। এরপরে, আমরা আমাজন S3-তে অবস্থিত প্রশিক্ষণ ডেটার পথ ব্যবহার করেছি, টাইম সিরিজ ডেটাসেট ফ্রিকোয়েন্সি (H, D, W, M, Y) সংজ্ঞায়িত করেছি, একটি ডেটাসেটের নাম সংজ্ঞায়িত করেছি এবং ডেটাসেটের বৈশিষ্ট্যগুলি চিহ্নিত করেছি (এতে সংশ্লিষ্ট কলামগুলি ম্যাপ করা হয়েছে) ডেটাসেট এবং তাদের ডেটা প্রকার)। এরপরে, আমরা Boto3 API থেকে ডোমেইন, ডেটাসেট টাইপ, ডেটাসেটনাম, ডেটাসেট ফ্রিকোয়েন্সি এবং স্কিমার মতো বৈশিষ্ট্য সহ একটি ডেটাসেট তৈরি করতে Create_dataset ফাংশনকে কল করি। এই ফাংশনটি একটি JSON অবজেক্ট ফিরিয়ে দিয়েছে যাতে Amazon Resource Name (ARN) রয়েছে। এই ARN পরবর্তী ধাপে ব্যবহার করা হয়েছিল। নিম্নলিখিত কোড দেখুন:
dataset_path = "PATH_OF_DATASET_IN_S3"
DATASET_FREQUENCY = "M" # Frequency of dataset (H, D, W, M, Y) TS_DATASET_NAME = "NAME_OF_THE_DATASET"
TS_SCHEMA = { "Attributes":[ { "AttributeName":"item_id", "AttributeType":"string" }, { "AttributeName":"timestamp", "AttributeType":"timestamp" }, { "AttributeName":"target_value", "AttributeType":"float" } ]
} create_dataset_response = forecast.create_dataset(Domain="CUSTOM", DatasetType='TARGET_TIME_SERIES', DatasetName=TS_DATASET_NAME, DataFrequency=DATASET_FREQUENCY, Schema=TS_SCHEMA) ts_dataset_arn = create_dataset_response['DatasetArn']ডেটাসেট তৈরি হওয়ার পরে, এটি Boto3 ব্যবহার করে অ্যামাজন পূর্বাভাসে আমদানি করা হয়েছিল create_dataset_import_job ফাংশন দ্য create_dataset_import_job ফাংশন কাজের নাম (একটি স্ট্রিং মান), পূর্ববর্তী ধাপ থেকে ডেটাসেটের ARN, পূর্ববর্তী ধাপ থেকে Amazon S3-এ প্রশিক্ষণ ডেটার অবস্থান এবং আর্গুমেন্ট হিসাবে টাইম স্ট্যাম্প বিন্যাস নেয়। এটি ইম্পোর্ট জব ARN ধারণকারী একটি JSON অবজেক্ট প্রদান করে। নিম্নলিখিত কোড দেখুন:
TIMESTAMP_FORMAT = "yyyy-MM-dd"
TS_IMPORT_JOB_NAME = "SALES_DATA_IMPORT_JOB_NAME" ts_dataset_import_job_response = forecast.create_dataset_import_job(DatasetImportJobName=TS_IMPORT_JOB_NAME, DatasetArn=ts_dataset_arn, DataSource= { "S3Config" : { "Path": ts_s3_path, "RoleArn": role_arn } }, TimestampFormat=TIMESTAMP_FORMAT, TimeZone = TIMEZONE) ts_dataset_import_job_arn = ts_dataset_import_job_response['DatasetImportJobArn']আমদানি করা ডেটাসেটটি তারপর create_dataset_group ফাংশন ব্যবহার করে একটি ডেটাসেট গ্রুপ তৈরি করতে ব্যবহৃত হয়েছিল। এই ফাংশনটি ডোমেন (পূর্বাভাসের ডোমেনকে সংজ্ঞায়িত করে এমন স্ট্রিং মান), ডেটাসেট গ্রুপের নাম এবং ডেটাসেট এআরএনকে ইনপুট হিসেবে নেয়:
DATASET_GROUP_NAME = "SALES_DATA_GROUP_NAME"
DATASET_ARNS = [ts_dataset_arn] create_dataset_group_response = forecast.create_dataset_group(Domain="CUSTOM", DatasetGroupName=DATASET_GROUP_NAME, DatasetArns=DATASET_ARNS) dataset_group_arn = create_dataset_group_response['DatasetGroupArn']
এর পরে, আমরা পূর্বাভাস মডেল প্রশিক্ষণের জন্য ডেটাসেট গ্রুপ ব্যবহার করেছি। আমাজন পূর্বাভাস বিভিন্ন অত্যাধুনিক মডেল অফার করে; এই মডেলগুলির যে কোনও একটি প্রশিক্ষণের জন্য ব্যবহার করা যেতে পারে। আমরা আমাদের ডিফল্ট মডেল হিসাবে AutoPredictor ব্যবহার করেছি। AutoPredictor ব্যবহার করার প্রধান সুবিধা হল যে এটি স্বয়ংক্রিয়ভাবে আইটেম-স্তরের পূর্বাভাস তৈরি করে, ইনপুট ডেটাসেটের উপর ভিত্তি করে ছয়টি অত্যাধুনিক মডেলের একটি সমাহার থেকে সর্বোত্তম মডেল ব্যবহার করে। Boto3 API প্রদান করে তৈরি_স্বয়ংক্রিয়_ভবিষ্যদ্বাণী একটি স্বয়ংক্রিয় ভবিষ্যদ্বাণী মডেল প্রশিক্ষণের জন্য ফাংশন। এই ফাংশনের ইনপুট প্যারামিটার হল ভবিষ্যদ্বাণীকারীর নাম, পূর্বাভাস দিগন্ত, এবং পূর্বাভাস ফ্রিকোয়েন্সি. ব্যবহারকারীরা পূর্বাভাস দিগন্ত এবং ফ্রিকোয়েন্সি নির্বাচন করার জন্য দায়ী। পূর্বাভাস দিগন্ত ভবিষ্যতের পূর্বাভাসের উইন্ডো আকারের প্রতিনিধিত্ব করে, যা ঘন্টা, দিন, সপ্তাহ, মাস ইত্যাদি ফর্ম্যাট করা যেতে পারে। একইভাবে, পূর্বাভাস ফ্রিকোয়েন্সি পূর্বাভাসের মানগুলির গ্রানুলারিটি প্রতিনিধিত্ব করে, যেমন ঘন্টায়, দৈনিক, সাপ্তাহিক, মাসিক বা বার্ষিক। আমরা প্রধানত বিভিন্ন BL-এ NXP-এর মাসিক বিক্রির পূর্বাভাস দেওয়ার উপর ফোকাস করেছি। নিম্নলিখিত কোড দেখুন:
PREDICTOR_NAME = "SALES_PREDICTOR"
FORECAST_HORIZON = 24
FORECAST_FREQUENCY = "M" create_auto_predictor_response = forecast.create_auto_predictor(PredictorName = PREDICTOR_NAME, ForecastHorizon = FORECAST_HORIZON, ForecastFrequency = FORECAST_FREQUENCY, DataConfig = { 'DatasetGroupArn': dataset_group_arn }) predictor_arn = create_auto_predictor_response['PredictorArn']প্রশিক্ষিত ভবিষ্যদ্বাণীকারী তখন পূর্বাভাসের মান তৈরি করতে ব্যবহৃত হয়েছিল। ব্যবহার করে পূর্বাভাস তৈরি করা হয়েছিল সৃষ্টি_পূর্বাভাস পূর্বে প্রশিক্ষিত ভবিষ্যদ্বাণীকারী থেকে ফাংশন। এই ফাংশনটি পূর্বাভাসের নাম এবং ভবিষ্যদ্বাণীকারীর ARN ইনপুট হিসাবে নেয় এবং ভবিষ্যদ্বাণীতে সংজ্ঞায়িত দিগন্ত এবং ফ্রিকোয়েন্সির জন্য পূর্বাভাসের মান তৈরি করে:
FORECAST_NAME = "SALES_FORECAST" create_forecast_response = forecast.create_forecast(ForecastName=FORECAST_NAME, PredictorArn=predictor_arn)Amazon Forecast হল একটি সম্পূর্ণরূপে পরিচালিত পরিষেবা যা স্বয়ংক্রিয়ভাবে প্রশিক্ষণ এবং পরীক্ষার ডেটাসেট তৈরি করে এবং মডেল-উত্পন্ন পূর্বাভাসের নির্ভরযোগ্যতা মূল্যায়ন করার জন্য বিভিন্ন নির্ভুলতা মেট্রিক্স প্রদান করে। যাইহোক, ভবিষ্যদ্বাণী করা ডেটার উপর ঐক্যমত্য তৈরি করতে এবং মানুষের ভবিষ্যদ্বাণীগুলির সাথে পূর্বাভাসিত মানগুলির তুলনা করতে, আমরা আমাদের ঐতিহাসিক ডেটাকে প্রশিক্ষণের ডেটা এবং বৈধতা ডেটাতে ম্যানুয়ালি ভাগ করেছি৷ আমরা মডেলটিকে বৈধতা ডেটাতে প্রকাশ না করে প্রশিক্ষণ ডেটা ব্যবহার করে মডেলটিকে প্রশিক্ষণ দিয়েছি এবং বৈধতা ডেটার দৈর্ঘ্যের জন্য পূর্বাভাস তৈরি করেছি৷ মডেল পারফরম্যান্স মূল্যায়ন করার জন্য ভবিষ্যদ্বাণীকৃত মানগুলির সাথে বৈধতা ডেটা তুলনা করা হয়েছিল। বৈধতা মেট্রিক্সের মধ্যে অন্যদের মধ্যে গড় পরম শতাংশ ত্রুটি (MAPE) এবং ওজনযুক্ত পরম শতাংশ ত্রুটি (WAPE) অন্তর্ভুক্ত থাকতে পারে। আমরা WAPE কে আমাদের নির্ভুলতা মেট্রিক হিসাবে ব্যবহার করেছি, যেমনটি পরবর্তী বিভাগে আলোচনা করা হয়েছে।
মূল্যায়ন মেট্রিক্স
দীর্ঘমেয়াদী বিক্রয় পূর্বাভাসের (2026 বিক্রয়) জন্য আমাদের পূর্বাভাস মডেলের ভবিষ্যদ্বাণী যাচাই করতে আমরা প্রথমে ব্যাকটেস্টিং ব্যবহার করে মডেলের কার্যকারিতা যাচাই করেছি। আমরা WAPE ব্যবহার করে মডেলের কর্মক্ষমতা মূল্যায়ন করেছি। WAPE মান যত কম, মডেল তত ভাল। MAPE-এর মতো অন্যান্য ত্রুটির মেট্রিকগুলির উপর WAPE ব্যবহার করার মূল সুবিধা হল যে WAPE প্রতিটি আইটেমের বিক্রয়ের পৃথক প্রভাবকে ওজন করে। অতএব, সামগ্রিক ত্রুটি গণনা করার সময় এটি মোট বিক্রয়ে প্রতিটি পণ্যের অবদানের জন্য অ্যাকাউন্ট করে। উদাহরণস্বরূপ, আপনি যদি $2 মিলিয়ন জেনারেট করে এমন একটি পণ্যে 30% এবং $10 জেনারেট করে এমন একটি পণ্যে 50,000% এর ত্রুটি করেন, আপনার MAPE পুরো গল্পটি বলবে না। 2% ত্রুটি আসলে 10% ত্রুটির চেয়ে ব্যয়বহুল, এমন কিছু যা আপনি MAPE ব্যবহার করে বলতে পারবেন না। তুলনামূলকভাবে, WAPE এই পার্থক্যগুলির জন্য দায়ী। আমরা মডেল পূর্বাভাসের উপরের এবং নীচের সীমানা প্রদর্শনের জন্য বিক্রয়ের জন্য বিভিন্ন শতাংশের মানও ভবিষ্যদ্বাণী করেছি।
ম্যাক্রো-স্তরের বিক্রয় পূর্বাভাস মডেলের বৈধতা
এর পরে, আমরা WAPE মানগুলির পরিপ্রেক্ষিতে মডেলের কার্যকারিতা যাচাই করেছি। আমরা পরীক্ষা এবং বৈধতা সেটে ডেটা বিভক্ত করে একটি মডেলের WAPE মান গণনা করেছি। উদাহরণস্বরূপ, 2019 WAPE মানতে, আমরা 2011-2018-এর মধ্যে বিক্রয় ডেটা ব্যবহার করে আমাদের মডেলকে প্রশিক্ষণ দিয়েছি এবং পরবর্তী 12 মাসের (2019 বিক্রয়) জন্য বিক্রয় মূল্যের পূর্বাভাস দিয়েছি। পরবর্তী, আমরা নিম্নলিখিত সূত্র ব্যবহার করে WAPE মান গণনা করেছি:

আমরা 2020 এবং 2021 এর জন্য WAPE মান গণনা করার জন্য একই পদ্ধতির পুনরাবৃত্তি করেছি। আমরা 2019, 2020 এবং 2021-এর জন্য অটো শেষ বাজারে সমস্ত BL-এর জন্য WAPE মূল্যায়ন করেছি। সামগ্রিকভাবে, আমরা লক্ষ্য করেছি যে Amazon Forecast এমনকি 0.33 WAPE মান অর্জন করতে পারে 2020 সাল (COVID-19 মহামারী চলাকালীন)। 2019 এবং 2020 সালে, আমাদের মডেল উচ্চ নির্ভুলতা প্রদর্শন করে 0.1 WAPE মান অর্জন করেছে।
ম্যাক্রো-স্তরের বিক্রয় পূর্বাভাস বেসলাইন তুলনা
আমরা 2019, 2020 এবং 2021 এর জন্য WAPE মানের পরিপ্রেক্ষিতে Amazon Forecast ব্যবহার করে তৈরি করা ম্যাক্রো বিক্রয় ভবিষ্যদ্বাণী মডেলগুলির কার্যকারিতাকে তিনটি বেসলাইন মডেলের সাথে তুলনা করেছি (নিচের চিত্রটি দেখুন)। আমাজন পূর্বাভাস হয় উল্লেখযোগ্যভাবে অন্যান্য বেসলাইন মডেলগুলিকে ছাড়িয়ে গেছে বা সমস্ত 3 বছরের জন্য সমানভাবে পারফর্ম করেছে৷ এই ফলাফলগুলি আমাদের চূড়ান্ত মডেল ভবিষ্যদ্বাণীগুলির কার্যকারিতাকে আরও যাচাই করে।

ম্যাক্রো-স্তরের বিক্রয় পূর্বাভাস মডেল বনাম মানুষের ভবিষ্যদ্বাণী
আমাদের ম্যাক্রো-স্তরের মডেলের আত্মবিশ্বাসকে আরও যাচাই করার জন্য, আমরা পরবর্তীতে আমাদের মডেলের কর্মক্ষমতাকে মানব-ভবিষ্যদ্বাণীকৃত বিক্রয় মানের সাথে তুলনা করেছি। প্রতি বছর চতুর্থ ত্রৈমাসিকের শুরুতে, NXP-এর বাজার বিশেষজ্ঞরা প্রতিটি BL-এর বিক্রয় মূল্যের ভবিষ্যদ্বাণী করে, বিশ্বব্যাপী বাজারের প্রবণতা এবং সেইসাথে অন্যান্য বৈশ্বিক সূচকগুলি বিবেচনা করে যা NXP পণ্যের বিক্রয়কে সম্ভাব্যভাবে প্রভাবিত করতে পারে। আমরা 2019, 2020 এবং 2021 সালে প্রকৃত বিক্রয় মানের সাথে মডেল ভবিষ্যদ্বাণী বনাম মানুষের ভবিষ্যদ্বাণীর শতকরা ত্রুটির তুলনা করি। আমরা 2011-2018 এর ডেটা ব্যবহার করে তিনটি মডেলকে প্রশিক্ষণ দিয়েছি এবং 2021 সাল পর্যন্ত বিক্রয় মূল্যের পূর্বাভাস দিয়েছি। আমরা পরবর্তীতে MAPE গণনা করেছি প্রকৃত বিক্রয় মান। তারপরে আমরা 2018 সালের শেষ নাগাদ মানব-ভবিষ্যদ্বাণী করা মানগুলি ব্যবহার করেছি (মডেল পূর্বাভাস 1Y এগিয়ে থেকে 3Y পূর্বাভাসটি পরীক্ষা করুন)। 2019 (1Y এগিয়ে পূর্বাভাস থেকে 2Y এগিয়ে পূর্বাভাস) এবং 2020 (1Y এগিয়ে পূর্বাভাসের জন্য) মানের পূর্বাভাস দিতে আমরা এই প্রক্রিয়াটি পুনরাবৃত্তি করেছি। সামগ্রিকভাবে, মডেলটি মানব ভবিষ্যদ্বাণীকারীদের সাথে সমান বা কিছু ক্ষেত্রে ভাল পারফর্ম করেছে। এই ফলাফলগুলি আমাদের মডেলের কার্যকারিতা এবং নির্ভরযোগ্যতা প্রদর্শন করে।
মাইক্রো-স্তরের বিক্রয় পূর্বাভাস এবং পণ্য জীবনচক্র
নিম্নলিখিত চিত্রটি প্রতিটি পণ্যের জন্য খুব কম পর্যবেক্ষণে অ্যাক্সেস থাকার সময় পণ্য ডেটা ব্যবহার করে মডেলটি কীভাবে আচরণ করে তা চিত্রিত করে (যেমন পণ্যের জীবনচক্র পূর্বাভাসের জন্য ইনপুটে এক বা দুটি পর্যবেক্ষণ)। কমলা রঙের বিন্দুগুলি প্রশিক্ষণের ডেটা উপস্থাপন করে, সবুজ বিন্দুগুলি পরীক্ষার ডেটা উপস্থাপন করে এবং নীল রেখাটি মডেলের ভবিষ্যদ্বাণীকৃত পণ্যের জীবনচক্রকে উপস্থাপন করে।

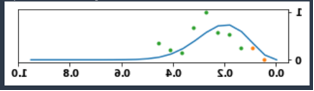

নতুন বিক্রয় ডেটা উপলব্ধ হওয়ার সাথে সাথে পুনরায় প্রশিক্ষণের প্রয়োজন ছাড়াই প্রেক্ষাপটের জন্য মডেলটিকে আরও পর্যবেক্ষণ দেওয়া যেতে পারে। নিম্নলিখিত চিত্রটি প্রদর্শন করে যে মডেলটি কীভাবে আচরণ করে যদি এটি আরও প্রসঙ্গ দেওয়া হয়। শেষ পর্যন্ত, আরও প্রসঙ্গ WAPE মানকে কমিয়ে দেয়।
উপরন্তু, আমরা প্রতিটি পণ্যের জন্য অতিরিক্ত বৈশিষ্ট্যগুলিকে অন্তর্ভুক্ত করতে পেরেছি, যার মধ্যে রয়েছে বানোয়াট কৌশল এবং অন্যান্য স্পষ্ট তথ্য। এই বিষয়ে, বাহ্যিক বৈশিষ্ট্যগুলি নিম্ন-প্রসঙ্গ শাসনে WAPE মান কমাতে সাহায্য করেছে (নিচের চিত্রটি দেখুন)। এই আচরণের জন্য দুটি ব্যাখ্যা আছে। প্রথমত, আমাদের উচ্চ-প্রসঙ্গ শাসনে ডেটাকে নিজের জন্য কথা বলতে দিতে হবে। অতিরিক্ত বৈশিষ্ট্যগুলি এই প্রক্রিয়াতে হস্তক্ষেপ করতে পারে। দ্বিতীয়ত, আমাদের আরও ভালো বৈশিষ্ট্য দরকার। আমরা 1,000 মাত্রিক এক-হট-এনকোডেড বৈশিষ্ট্য (শব্দের ব্যাগ) ব্যবহার করেছি। অনুমান হল যে আরও ভাল বৈশিষ্ট্য প্রকৌশল কৌশল WAPE কে আরও কমাতে সাহায্য করতে পারে।
এই ধরনের অতিরিক্ত তথ্য মডেলটিকে নতুন পণ্যের বিক্রির পূর্বাভাস দিতে সাহায্য করতে পারে এমনকি পণ্য বাজারে ছাড়ার আগেই। উদাহরণস্বরূপ, নিম্নলিখিত চিত্রে, আমরা প্লট করি যে আমরা কেবলমাত্র বাহ্যিক বৈশিষ্ট্যগুলি থেকে কত মাইলেজ পেতে পারি।

উপসংহার
এই পোস্টে, আমরা দেখিয়েছি কিভাবে MLSL এবং NXP দলগুলি NXP-এর জন্য ম্যাক্রো- এবং মাইক্রো-লেভেলের দীর্ঘমেয়াদী বিক্রয়ের পূর্বাভাস দিতে একসঙ্গে কাজ করেছে। NXP টিম এখন শিখবে কিভাবে এই বিক্রয় ভবিষ্যদ্বাণীগুলিকে তাদের প্রক্রিয়াগুলিতে ব্যবহার করতে হয়—উদাহরণস্বরূপ, এটিকে R&D ফান্ডিং সিদ্ধান্তের জন্য ইনপুট হিসাবে ব্যবহার করতে এবং ROI উন্নত করতে। আমরা ব্যবসায়িক লাইন (ম্যাক্রো বিক্রয়) বিক্রয়ের পূর্বাভাস দিতে Amazon পূর্বাভাস ব্যবহার করেছি, যাকে আমরা টপ-ডাউন পদ্ধতি হিসাবে উল্লেখ করেছি। আমরা পণ্য স্তরে (মাইক্রো লেভেল) হারিয়ে যাওয়া মান এবং কোল্ড স্টার্টের চ্যালেঞ্জগুলি মোকাবেলা করার জন্য পয়েন্ট ক্লাউড হিসাবে টাইম সিরিজ ব্যবহার করে একটি অভিনব পদ্ধতির প্রস্তাবও করেছি। আমরা এই পদ্ধতিটিকে বটম-আপ হিসাবে উল্লেখ করেছি, যেখানে আমরা প্রতিটি পণ্যের মাসিক বিক্রয়ের পূর্বাভাস দিয়েছি। আমরা কোল্ড স্টার্টের জন্য মডেলের কর্মক্ষমতা বাড়ানোর জন্য প্রতিটি পণ্যের বাহ্যিক বৈশিষ্ট্যগুলিকে আরও অন্তর্ভুক্ত করেছি।
সামগ্রিকভাবে, এই ব্যস্ততার সময় বিকশিত মডেলগুলি মানুষের ভবিষ্যদ্বাণীর তুলনায় সমানভাবে পারফর্ম করেছে৷ কিছু ক্ষেত্রে, মডেলগুলি দীর্ঘমেয়াদে মানুষের পূর্বাভাসের চেয়ে ভাল পারফর্ম করেছে। এই ফলাফলগুলি আমাদের মডেলগুলির কার্যকারিতা এবং নির্ভরযোগ্যতা প্রদর্শন করে৷
এই সমাধান কোনো পূর্বাভাস সমস্যার জন্য নিযুক্ত করা যেতে পারে. এমএল সলিউশন ডিজাইন এবং ডেভেলপ করার ক্ষেত্রে আরও সহায়তার জন্য, অনুগ্রহ করে নির্দ্বিধায় এর সাথে যোগাযোগ করুন এমএলএসএল টীম.
লেখক সম্পর্কে
 সৌদ বউতানে NXP-CTO-এর একজন ডেটা সায়েন্টিস্ট, যেখানে তিনি উন্নত সরঞ্জাম এবং কৌশল ব্যবহার করে ব্যবসায়িক সিদ্ধান্তকে সমর্থন করার জন্য বিভিন্ন ডেটাকে অর্থপূর্ণ অন্তর্দৃষ্টিতে রূপান্তরিত করছেন।
সৌদ বউতানে NXP-CTO-এর একজন ডেটা সায়েন্টিস্ট, যেখানে তিনি উন্নত সরঞ্জাম এবং কৌশল ব্যবহার করে ব্যবসায়িক সিদ্ধান্তকে সমর্থন করার জন্য বিভিন্ন ডেটাকে অর্থপূর্ণ অন্তর্দৃষ্টিতে রূপান্তরিত করছেন।
 বেন ফ্রিডোলিন এনএক্সপি-সিটিও-র একজন ডেটা সায়েন্টিস্ট, যেখানে তিনি এআই এবং ক্লাউড গ্রহণকে ত্বরান্বিত করার বিষয়ে সমন্বয় করেন। তিনি মেশিন লার্নিং, ডিপ লার্নিং এবং এন্ড-টু-এন্ড এমএল সমাধানের উপর ফোকাস করেন।
বেন ফ্রিডোলিন এনএক্সপি-সিটিও-র একজন ডেটা সায়েন্টিস্ট, যেখানে তিনি এআই এবং ক্লাউড গ্রহণকে ত্বরান্বিত করার বিষয়ে সমন্বয় করেন। তিনি মেশিন লার্নিং, ডিপ লার্নিং এবং এন্ড-টু-এন্ড এমএল সমাধানের উপর ফোকাস করেন।
 কর্নি জিনেন এটি NXP-এর ডেটা পোর্টফোলিওতে একটি প্রকল্পের নেতৃত্ব যা তথ্য কেন্দ্রিক হয়ে ওঠার দিকে প্রতিষ্ঠানের ডিজিটাল রূপান্তরে সহায়তা করে।
কর্নি জিনেন এটি NXP-এর ডেটা পোর্টফোলিওতে একটি প্রকল্পের নেতৃত্ব যা তথ্য কেন্দ্রিক হয়ে ওঠার দিকে প্রতিষ্ঠানের ডিজিটাল রূপান্তরে সহায়তা করে।
 বার্ট জিম্যান এনএক্সপি-সিটিও-তে ডেটা এবং বিশ্লেষণের প্রতি অনুরাগ সহ একজন কৌশলবিদ যেখানে তিনি আরও বৃদ্ধি এবং উদ্ভাবনের জন্য আরও ভাল ডেটা চালিত সিদ্ধান্তের জন্য চালনা করছেন।
বার্ট জিম্যান এনএক্সপি-সিটিও-তে ডেটা এবং বিশ্লেষণের প্রতি অনুরাগ সহ একজন কৌশলবিদ যেখানে তিনি আরও বৃদ্ধি এবং উদ্ভাবনের জন্য আরও ভাল ডেটা চালিত সিদ্ধান্তের জন্য চালনা করছেন।
 আহসান আলী তিনি অ্যামাজন মেশিন লার্নিং সলিউশন ল্যাবের একজন ফলিত বিজ্ঞানী, যেখানে তিনি অত্যাধুনিক AI/ML কৌশল ব্যবহার করে তাদের জরুরী এবং ব্যয়বহুল সমস্যার সমাধান করার জন্য বিভিন্ন ডোমেনের গ্রাহকদের সাথে কাজ করেন।
আহসান আলী তিনি অ্যামাজন মেশিন লার্নিং সলিউশন ল্যাবের একজন ফলিত বিজ্ঞানী, যেখানে তিনি অত্যাধুনিক AI/ML কৌশল ব্যবহার করে তাদের জরুরী এবং ব্যয়বহুল সমস্যার সমাধান করার জন্য বিভিন্ন ডোমেনের গ্রাহকদের সাথে কাজ করেন।
 ইফু হু অ্যামাজন মেশিন লার্নিং সলিউশন ল্যাবে একজন ফলিত বিজ্ঞানী, যেখানে তিনি বিভিন্ন শিল্পে গ্রাহকদের ব্যবসায়িক সমস্যা সমাধানের জন্য সৃজনশীল এমএল সমাধান ডিজাইন করতে সাহায্য করেন।
ইফু হু অ্যামাজন মেশিন লার্নিং সলিউশন ল্যাবে একজন ফলিত বিজ্ঞানী, যেখানে তিনি বিভিন্ন শিল্পে গ্রাহকদের ব্যবসায়িক সমস্যা সমাধানের জন্য সৃজনশীল এমএল সমাধান ডিজাইন করতে সাহায্য করেন।
 মেহেদী নূরী অ্যামাজন এমএল সলিউশন ল্যাবের একজন ফলিত বিজ্ঞান ব্যবস্থাপক, যেখানে তিনি বিভিন্ন শিল্প জুড়ে বৃহৎ প্রতিষ্ঠানের জন্য এমএল সলিউশন তৈরি করতে সাহায্য করেন এবং এনার্জি উল্লম্ব নেতৃত্ব দেন। গ্রাহকদের তাদের সাসটেইনেবিলিটি লক্ষ্য অর্জনে সাহায্য করার জন্য তিনি AI/ML ব্যবহার করার ব্যাপারে আগ্রহী।
মেহেদী নূরী অ্যামাজন এমএল সলিউশন ল্যাবের একজন ফলিত বিজ্ঞান ব্যবস্থাপক, যেখানে তিনি বিভিন্ন শিল্প জুড়ে বৃহৎ প্রতিষ্ঠানের জন্য এমএল সলিউশন তৈরি করতে সাহায্য করেন এবং এনার্জি উল্লম্ব নেতৃত্ব দেন। গ্রাহকদের তাদের সাসটেইনেবিলিটি লক্ষ্য অর্জনে সাহায্য করার জন্য তিনি AI/ML ব্যবহার করার ব্যাপারে আগ্রহী।
 হুজেফা রংওয়ালা AIRE, AWS-এর একজন সিনিয়র ফলিত বিজ্ঞান ব্যবস্থাপক। মেশিন লার্নিং ভিত্তিক ডেটা সম্পদের আবিষ্কার সক্ষম করতে তিনি বিজ্ঞানী এবং প্রকৌশলীদের একটি দলকে নেতৃত্ব দেন। তার গবেষণার আগ্রহ দায়ী এআই, ফেডারেটেড লার্নিং এবং স্বাস্থ্যসেবা এবং জীবন বিজ্ঞানে এমএল-এর প্রয়োগ।
হুজেফা রংওয়ালা AIRE, AWS-এর একজন সিনিয়র ফলিত বিজ্ঞান ব্যবস্থাপক। মেশিন লার্নিং ভিত্তিক ডেটা সম্পদের আবিষ্কার সক্ষম করতে তিনি বিজ্ঞানী এবং প্রকৌশলীদের একটি দলকে নেতৃত্ব দেন। তার গবেষণার আগ্রহ দায়ী এআই, ফেডারেটেড লার্নিং এবং স্বাস্থ্যসেবা এবং জীবন বিজ্ঞানে এমএল-এর প্রয়োগ।
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- প্লেটোব্লকচেন। Web3 মেটাভার্স ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- উত্স: https://aws.amazon.com/blogs/machine-learning/predicting-new-and-existing-product-sales-in-semiconductors-using-amazon-forecast/

