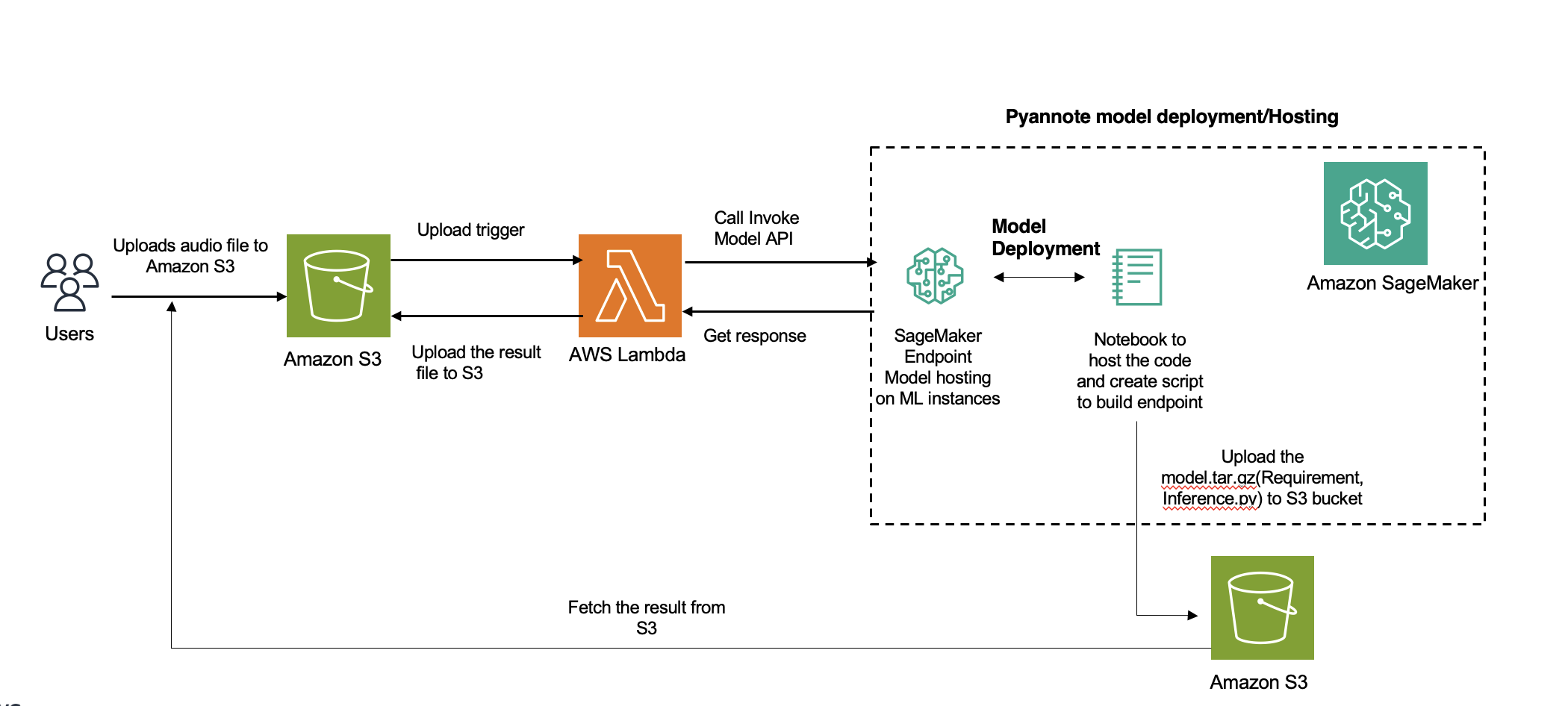
تعمل عملية تسجيل المتحدث، وهي عملية أساسية في التحليل الصوتي، على تقسيم الملف الصوتي بناءً على هوية المتحدث. يتعمق هذا المنشور في دمج PyAnnote الخاص بـ Hugging Face لتسجيل مذكرات المتحدث معه الأمازون SageMaker نقاط النهاية غير المتزامنة
نحن نقدم دليلاً شاملاً حول كيفية نشر حلول تجزئة المتحدثين وتجميعهم باستخدام SageMaker على سحابة AWS. يمكنك استخدام هذا الحل للتطبيقات التي تتعامل مع تسجيلات صوتية متعددة السماعات (أكثر من 100).
حل نظرة عامة
الأمازون النسخ هي الخدمة المفضلة لتدوين المتحدثين في AWS. ومع ذلك، بالنسبة للغات غير المدعومة، يمكنك استخدام نماذج أخرى (في حالتنا، PyAnnote) التي سيتم نشرها في SageMaker للاستدلال. بالنسبة للملفات الصوتية القصيرة التي يستغرق الاستدلال فيها ما يصل إلى 60 ثانية، يمكنك استخدامها الاستدلال في الوقت الحقيقي. لمدة أطول من 60 ثانية، غير المتزامن ينبغي استخدام الاستدلال. الميزة الإضافية للاستدلال غير المتزامن هي توفير التكاليف عن طريق التوسيع التلقائي لعدد المثيلات إلى الصفر عندما لا تكون هناك طلبات للمعالجة.
وجه يعانق يعد مركزًا مفتوح المصدر شائعًا لنماذج التعلم الآلي (ML). AWS وHugging Face لديهما شراكة يتيح التكامل السلس من خلال SageMaker مع مجموعة من حاويات التعلم العميق (DLC) الخاصة بـ AWS للتدريب والاستدلال في PyTorch أو TensorFlow، وأجهزة تقدير وتوقعات Hugging Face لـ SageMaker Python SDK. تساعد ميزات وإمكانات SageMaker المطورين وعلماء البيانات على البدء في معالجة اللغة الطبيعية (NLP) على AWS بسهولة.
يتضمن التكامل لهذا الحل استخدام نموذج تسجيل مكبرات الصوت المدرب مسبقًا من Hugging Face باستخدام مكتبة PyAnnote. PyAnnote عبارة عن مجموعة أدوات مفتوحة المصدر مكتوبة بلغة Python لتدوين المتحدثين. يتيح هذا النموذج، الذي تم تدريبه على مجموعة بيانات الصوت، التقسيم الفعال لمكبرات الصوت في الملفات الصوتية. يتم نشر النموذج على SageMaker كإعداد غير متزامن لنقطة النهاية، مما يوفر معالجة فعالة وقابلة للتطوير لمهام التدوين.
يوضح الرسم البياني التالي بنية الحل.
لهذا المنصب، نستخدم الملف الصوتي التالي.
يتم تلقائيًا خلط ملفات الصوت المجسمة أو متعددة القنوات إلى ملفات أحادية عن طريق حساب متوسط القنوات. يتم إعادة تشكيل ملفات الصوت التي تم أخذ عينات منها بمعدل مختلف إلى 16 كيلو هرتز تلقائيًا عند التحميل.
تأكد من أن حساب AWS لديه حصة خدمة لاستضافة نقطة نهاية SageMaker لمثيل ml.g5.2xlarge.
قم بإنشاء وظيفة نموذجية للوصول إلى تدوين مكبر الصوت PyAnnote من Hugging Face
يمكنك استخدام Hugging Face Hub للوصول إلى ما تم تدريبه مسبقًا نموذج PyAnnote لتدوين المتحدث. يمكنك استخدام نفس البرنامج النصي لتنزيل ملف النموذج عند إنشاء نقطة نهاية SageMaker.
انظر الكود التالي:
from PyAnnote.audio import Pipeline
def model_fn(model_dir):
# Load the model from the specified model directory
model = Pipeline.from_pretrained(
"PyAnnote/speaker-diarization-3.1",
use_auth_token="Replace-with-the-Hugging-face-auth-token")
return model
حزمة رمز النموذج
قم بإعداد الملفات الأساسية مثل inference.py، الذي يحتوي على رمز الاستدلال:
%%writefile model/code/inference.py
from PyAnnote.audio import Pipeline
import subprocess
import boto3
from urllib.parse import urlparse
import pandas as pd
from io import StringIO
import os
import torch
def model_fn(model_dir):
# Load the model from the specified model directory
model = Pipeline.from_pretrained(
"PyAnnote/speaker-diarization-3.1",
use_auth_token="hf_oBxxxxxxxxxxxx)
return model
def diarization_from_s3(model, s3_file, language=None):
s3 = boto3.client("s3")
o = urlparse(s3_file, allow_fragments=False)
bucket = o.netloc
key = o.path.lstrip("/")
s3.download_file(bucket, key, "tmp.wav")
result = model("tmp.wav")
data = {}
for turn, _, speaker in result.itertracks(yield_label=True):
data[turn] = (turn.start, turn.end, speaker)
data_df = pd.DataFrame(data.values(), columns=["start", "end", "speaker"])
print(data_df.shape)
result = data_df.to_json(orient="split")
return result
def predict_fn(data, model):
s3_file = data.pop("s3_file")
language = data.pop("language", None)
result = diarization_from_s3(model, s3_file, language)
return {
"diarization_from_s3": result
}
يحضر requirements.txt الملف، الذي يحتوي على مكتبات بايثون المطلوبة اللازمة لتشغيل الاستدلال:
with open("model/code/requirements.txt", "w") as f:
f.write("transformers==4.25.1n")
f.write("boto3n")
f.write("PyAnnote.audion")
f.write("soundfilen")
f.write("librosan")
f.write("onnxruntimen")
f.write("wgetn")
f.write("pandas")
وأخيرًا، قم بضغط inference.py وملفات Requirements.txt واحفظها باسم model.tar.gz:
!tar zcvf model.tar.gz *
قم بتكوين نموذج SageMaker
حدد مورد نموذج SageMaker عن طريق تحديد URI للصورة وموقع بيانات النموذج فيه خدمة تخزين أمازون البسيطة (S3)، ودور SageMaker:
import sagemaker
import boto3
sess = sagemaker.Session()
sagemaker_session_bucket = None
if sagemaker_session_bucket is None and sess is not None:
sagemaker_session_bucket = sess.default_bucket()
try:
role = sagemaker.get_execution_role()
except ValueError:
iam = boto3.client("iam")
role = iam.get_role(RoleName="sagemaker_execution_role")["Role"]["Arn"]
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
print(f"sagemaker role arn: {role}")
print(f"sagemaker bucket: {sess.default_bucket()}")
print(f"sagemaker session region: {sess.boto_region_name}")
قم بتحميل النموذج إلى Amazon S3
قم بتحميل ملف نموذج PyAnnote Hugging Face المضغوط إلى حاوية S3:
قم بتكوين نقطة نهاية غير متزامنة لنشر النموذج على SageMaker باستخدام تكوين الاستدلال غير المتزامن المقدم:
from sagemaker.huggingface.model import HuggingFaceModel
from sagemaker.async_inference.async_inference_config import AsyncInferenceConfig
from sagemaker.s3 import s3_path_join
from sagemaker.utils import name_from_base
async_endpoint_name = name_from_base("custom-asyc")
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
model_data=s3_location, # path to your model and script
role=role, # iam role with permissions to create an Endpoint
transformers_version="4.17", # transformers version used
pytorch_version="1.10", # pytorch version used
py_version="py38", # python version used
)
# create async endpoint configuration
async_config = AsyncInferenceConfig(
output_path=s3_path_join(
"s3://", sagemaker_session_bucket, "async_inference/output"
), # Where our results will be stored
# Add nofitication SNS if needed
notification_config={
# "SuccessTopic": "PUT YOUR SUCCESS SNS TOPIC ARN",
# "ErrorTopic": "PUT YOUR ERROR SNS TOPIC ARN",
}, # Notification configuration
)
env = {"MODEL_SERVER_WORKERS": "2"}
# deploy the endpoint endpoint
async_predictor = huggingface_model.deploy(
initial_instance_count=1,
instance_type="ml.xx",
async_inference_config=async_config,
endpoint_name=async_endpoint_name,
env=env,
)
اختبار نقطة النهاية
قم بتقييم وظيفة نقطة النهاية عن طريق إرسال ملف صوتي للتدوين واسترداد مخرجات JSON المخزنة في مسار إخراج S3 المحدد:
# Replace with a path to audio object in S3
from sagemaker.async_inference import WaiterConfig
res = async_predictor.predict_async(data=data)
print(f"Response output path: {res.output_path}")
print("Start Polling to get response:")
config = WaiterConfig(
max_attempts=10, # number of attempts
delay=10# time in seconds to wait between attempts
)
res.get_result(config)
#import waiterconfig
لنشر هذا الحل على نطاق واسع، نقترح استخدام AWS لامدا, خدمة إعلام أمازون البسيطة (أمازون SNS)، أو خدمة Amazon Simple Queue Service (أمازون إس كيو إس). تم تصميم هذه الخدمات لتحقيق قابلية التوسع والبنيات المستندة إلى الأحداث والاستخدام الفعال للموارد. يمكنها المساعدة في فصل عملية الاستدلال غير المتزامن عن معالجة النتائج، مما يسمح لك بقياس كل مكون بشكل مستقل والتعامل مع دفعات طلبات الاستدلال بشكل أكثر فعالية.
النتائج
يتم تخزين إخراج النموذج في s3://sagemaker-xxxx /async_inference/output/. يوضح الإخراج أن التسجيل الصوتي قد تم تقسيمه إلى ثلاثة أعمدة:
يمكنك ضبط سياسة القياس على الصفر عن طريق ضبط MinCapacity على 0؛ الاستدلال غير المتزامن يتيح لك القياس التلقائي إلى الصفر دون أي طلبات. لا تحتاج إلى حذف نقطة النهاية، فهي النطاقات من الصفر عند الحاجة إليها مرة أخرى، مما يقلل التكاليف عند عدم الاستخدام. انظر الكود التالي:
# Common class representing application autoscaling for SageMaker
client = boto3.client('application-autoscaling')
# This is the format in which application autoscaling references the endpoint
resource_id='endpoint/' + <endpoint_name> + '/variant/' + <'variant1'>
# Define and register your endpoint variant
response = client.register_scalable_target(
ServiceNamespace='sagemaker',
ResourceId=resource_id,
ScalableDimension='sagemaker:variant:DesiredInstanceCount', # The number of EC2 instances for your Amazon SageMaker model endpoint variant.
MinCapacity=0,
MaxCapacity=5
)
إذا كنت تريد حذف نقطة النهاية، استخدم الكود التالي:
يمكن للحل التعامل بكفاءة مع ملفات صوتية متعددة أو كبيرة.
يستخدم هذا المثال مثيل واحد للعرض التوضيحي. إذا كنت تريد استخدام هذا الحل لمئات أو آلاف مقاطع الفيديو واستخدام نقطة نهاية غير متزامنة للمعالجة عبر مثيلات متعددة، فيمكنك استخدام سياسة التحجيم التلقائي، وهو مصمم لعدد كبير من المستندات المصدر. يقوم القياس التلقائي بضبط عدد المثيلات المتوفرة للنموذج ديناميكيًا استجابة للتغيرات في عبء العمل لديك.
يعمل الحل على تحسين الموارد وتقليل حمل النظام عن طريق فصل المهام طويلة الأمد عن الاستدلال في الوقت الفعلي.
وفي الختام
في هذا المنشور، قدمنا أسلوبًا مباشرًا لنشر نموذج تدوين المتحدث الخاص بـ Hugging Face على SageMaker باستخدام نصوص Python النصية. يوفر استخدام نقطة النهاية غير المتزامنة وسيلة فعالة وقابلة للتطوير لتقديم تنبؤات التسجيل كخدمة، واستيعاب الطلبات المتزامنة بسلاسة.
ابدأ اليوم مع تدوين مكبر الصوت غير المتزامن لمشاريعك الصوتية. تواصل معنا في التعليقات إذا كانت لديك أي أسئلة حول تشغيل نقطة نهاية التدوين غير المتزامن الخاصة بك وتشغيلها.
حول المؤلف
سانجاي تيواري هو مهندس حلول متخصص في الذكاء الاصطناعي/تعلم الآلة يقضي وقته في العمل مع العملاء الاستراتيجيين لتحديد متطلبات العمل، وتوفير جلسات L300 حول حالات استخدام محددة، وتصميم تطبيقات وخدمات الذكاء الاصطناعي/تعلم الآلة التي تكون قابلة للتطوير وموثوقة وعالية الأداء. لقد ساعد في إطلاق وتوسيع نطاق خدمة Amazon SageMaker التي تعمل بالذكاء الاصطناعي/التعلم الآلي، وقام بتنفيذ العديد من إثباتات المفهوم باستخدام خدمات Amazon AI. كما قام أيضًا بتطوير منصة التحليلات المتقدمة كجزء من رحلة التحول الرقمي.
كيران تشالابالي هو مطور أعمال في مجال التكنولوجيا العميقة مع القطاع العام في AWS. يتمتع بخبرة تزيد عن 8 سنوات في مجال الذكاء الاصطناعي/تعلم الآلة و23 عامًا من الخبرة الشاملة في تطوير البرمجيات والمبيعات. يساعد كيران شركات القطاع العام في جميع أنحاء الهند على استكشاف الحلول المستندة إلى السحابة والمشاركة في إنشائها والتي تستخدم تقنيات الذكاء الاصطناعي وتعلم الآلة والذكاء الاصطناعي التوليدي - بما في ذلك نماذج اللغات الكبيرة.
محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
 سانجاي تيواري هو مهندس حلول متخصص في الذكاء الاصطناعي/تعلم الآلة يقضي وقته في العمل مع العملاء الاستراتيجيين لتحديد متطلبات العمل، وتوفير جلسات L300 حول حالات استخدام محددة، وتصميم تطبيقات وخدمات الذكاء الاصطناعي/تعلم الآلة التي تكون قابلة للتطوير وموثوقة وعالية الأداء. لقد ساعد في إطلاق وتوسيع نطاق خدمة Amazon SageMaker التي تعمل بالذكاء الاصطناعي/التعلم الآلي، وقام بتنفيذ العديد من إثباتات المفهوم باستخدام خدمات Amazon AI. كما قام أيضًا بتطوير منصة التحليلات المتقدمة كجزء من رحلة التحول الرقمي.
سانجاي تيواري هو مهندس حلول متخصص في الذكاء الاصطناعي/تعلم الآلة يقضي وقته في العمل مع العملاء الاستراتيجيين لتحديد متطلبات العمل، وتوفير جلسات L300 حول حالات استخدام محددة، وتصميم تطبيقات وخدمات الذكاء الاصطناعي/تعلم الآلة التي تكون قابلة للتطوير وموثوقة وعالية الأداء. لقد ساعد في إطلاق وتوسيع نطاق خدمة Amazon SageMaker التي تعمل بالذكاء الاصطناعي/التعلم الآلي، وقام بتنفيذ العديد من إثباتات المفهوم باستخدام خدمات Amazon AI. كما قام أيضًا بتطوير منصة التحليلات المتقدمة كجزء من رحلة التحول الرقمي. كيران تشالابالي هو مطور أعمال في مجال التكنولوجيا العميقة مع القطاع العام في AWS. يتمتع بخبرة تزيد عن 8 سنوات في مجال الذكاء الاصطناعي/تعلم الآلة و23 عامًا من الخبرة الشاملة في تطوير البرمجيات والمبيعات. يساعد كيران شركات القطاع العام في جميع أنحاء الهند على استكشاف الحلول المستندة إلى السحابة والمشاركة في إنشائها والتي تستخدم تقنيات الذكاء الاصطناعي وتعلم الآلة والذكاء الاصطناعي التوليدي - بما في ذلك نماذج اللغات الكبيرة.
كيران تشالابالي هو مطور أعمال في مجال التكنولوجيا العميقة مع القطاع العام في AWS. يتمتع بخبرة تزيد عن 8 سنوات في مجال الذكاء الاصطناعي/تعلم الآلة و23 عامًا من الخبرة الشاملة في تطوير البرمجيات والمبيعات. يساعد كيران شركات القطاع العام في جميع أنحاء الهند على استكشاف الحلول المستندة إلى السحابة والمشاركة في إنشائها والتي تستخدم تقنيات الذكاء الاصطناعي وتعلم الآلة والذكاء الاصطناعي التوليدي - بما في ذلك نماذج اللغات الكبيرة.
