في كانون الثاني / يناير شنومكس، الأمازون SageMaker أطلق إصدارًا جديدًا (0.26.0) حاويات التعلم العميق (DLCs) لاستدلال النماذج الكبيرة (LMI). يقدم هذا الإصدار دعمًا للنماذج الجديدة (بما في ذلك مزيج من الخبراء)، وتحسينات في الأداء وسهولة الاستخدام عبر الواجهات الخلفية للاستدلال، بالإضافة إلى تفاصيل الجيل الجديد لزيادة التحكم وقابلية تفسير التنبؤ (مثل سبب اكتمال التوليد واحتمالات سجل مستوى الرمز المميز).
تقدم LMI DLCs واجهة منخفضة الكود تعمل على تبسيط استخدام أحدث تقنيات وأجهزة تحسين الاستدلال. يسمح لك LMI بتطبيق توازي الموتر؛ أحدث تقنيات الاهتمام والتجميع والتكميم وإدارة الذاكرة الفعالة؛ تدفق الرمز المميز؛ وأكثر من ذلك بكثير، فقط من خلال طلب معرف النموذج ومعلمات النموذج الاختيارية. باستخدام محتويات LMI DLC على SageMaker، يمكنك تسريع الوقت المستغرق للحصول على القيمة لمشروعك الذكاء الاصطناعي التوليدي (AI) التطبيقات، وتفريغ الأحمال الثقيلة المتعلقة بالبنية التحتية، وتحسين نماذج اللغات الكبيرة (LLMs) للأجهزة التي تختارها لتحقيق أفضل أداء من حيث السعر في فئتها.
في هذا المنشور، نستكشف أحدث الميزات المقدمة في هذا الإصدار، ونفحص معايير الأداء، ونقدم دليلاً تفصيليًا حول نشر LLMs الجديدة مع LMI DLCs بأداء عالٍ.
ميزات جديدة مع LMI DLCs
في هذا القسم، نناقش الميزات الجديدة عبر واجهات LMI الخلفية، ونتعمق في بعض الميزات الأخرى الخاصة بالواجهة الخلفية. يدعم LMI حاليًا الواجهات الخلفية التالية:
- المكتبة الموزعة LMI - هذا هو إطار عمل AWS لتشغيل الاستدلال مع LLMs، المستوحى من OSS، لتحقيق أفضل زمن وصول ودقة ممكنة في النتيجة
- LMI vLLM - هذا هو تطبيق AWS الخلفي لكفاءة الذاكرة vLLM مكتبة الاستدلال
- مجموعة أدوات LMI TensorRT-LLM - هذا هو تطبيق الواجهة الخلفية لـ AWS نفيديا TensorRT-LLM، الذي ينشئ محركات خاصة بوحدة معالجة الرسومات لتحسين الأداء على وحدات معالجة الرسومات المختلفة
- LMI ديب سبيد - هذا هو تكييف AWS لـ السرعة العميقة، مما يضيف الدفع المستمر الحقيقي، وتكميم SmoothQuant، والقدرة على ضبط الذاكرة ديناميكيًا أثناء الاستدلال
- LMI نيورونكس – يمكنك استخدام هذا للنشر على AWS الاستدلال 2 و تدريب AWS-مثيلات قائمة على أساس، تتميز بالتجميع المستمر الحقيقي وعمليات التسريع، بناءً على AWS العصبية SDK
يلخص الجدول التالي الميزات المضافة حديثًا، العامة والخاصة بالواجهة الخلفية.
|
مشترك عبر الواجهات الخلفية |
|||
|
|||
|
الخلفية محددة |
|||
|
LMI الموزعة |
vLLM | TensorRT-LLM |
نيورونكس |
|
|
|
|
نماذج جديدة معتمدة
يتم دعم النماذج الشائعة الجديدة عبر الواجهات الخلفية، مثل Mistral-7B (جميع الواجهات الخلفية)، وMixtral المستند إلى MoE (جميع الواجهات الخلفية باستثناء Transformers-NeuronX)، وLlama2-70B (Transformers-NeuronX).
تقنيات تمديد نافذة السياق
يتوفر الآن مقياس السياق القائم على التضمين الموضعي الدوار (RoPE) على الواجهات الخلفية LMI-Dist وvLLM وTensorRT-LLM. يتيح تحجيم RoPE تمديد طول تسلسل النموذج أثناء الاستدلال إلى أي حجم تقريبًا، دون الحاجة إلى الضبط الدقيق.
فيما يلي اعتباران مهمان عند استخدام RoPE:
- الحيرة النموذجية - كلما زاد طول التسلسل، لذلك يمكن نماذج الحيرة. يمكن تعويض هذا التأثير جزئيًا عن طريق إجراء الحد الأدنى من الضبط الدقيق على تسلسلات الإدخال الأكبر من تلك المستخدمة في التدريب الأصلي. للحصول على فهم متعمق لكيفية تأثير RoPE على جودة النموذج، راجع تمديد حبل.
- أداء الاستدلال - ستستهلك أطوال التسلسل الأطول ذاكرة النطاق الترددي العالي للمسرع (HBM). يمكن أن يؤثر هذا الاستخدام المتزايد للذاكرة سلبًا على عدد الطلبات المتزامنة التي يمكن للمسرع الخاص بك التعامل معها.
وأضاف تفاصيل الجيل
يمكنك الآن الحصول على تفاصيل دقيقة حول نتائج الإنشاء:
- Finish_reason - وهذا يعطي سبب اكتمال الإنشاء، والذي يمكن أن يصل إلى الحد الأقصى لطول الإنشاء، أو إنشاء رمز مميز لنهاية الجملة (EOS)، أو إنشاء رمز توقف محدد من قبل المستخدم. يتم إرجاعه مع آخر قطعة تسلسل متدفقة.
- log_probs - يُرجع هذا احتمال السجل المعين بواسطة النموذج لكل رمز مميز في قطعة التسلسل المتدفقة. يمكنك استخدام هذه كتقدير تقريبي لثقة النموذج عن طريق حساب الاحتمال المشترك للتسلسل كمجموع
log_probsمن الرموز الفردية، والتي يمكن أن تكون مفيدة لتسجيل النتائج وتصنيف مخرجات النموذج. ضع في اعتبارك أن احتمالات رمز LLM تكون مفرطة الثقة بشكل عام دون معايرة.
يمكنك تمكين مخرجات نتائج الإنشاء عن طريق إضافة تفاصيل = صحيح في حمولة الإدخال الخاصة بك إلى LMI، مع ترك جميع المعلمات الأخرى دون تغيير:
payload = {“inputs”:“your prompt”,
“parameters”:{max_new_tokens”:256,...,“details”:True}
}معلمات التكوين الموحدة
وأخيرًا، تم أيضًا دمج معلمات تكوين LMI. لمزيد من المعلومات حول جميع معلمات تكوين النشر العامة والخاصة بالواجهة الخلفية، راجع تكوينات الاستدلال النموذجي الكبير.
الواجهة الخلفية الموزعة LMI
في AWS re:Invent 2023، أضاف LMI-Dist عمليات جماعية جديدة ومحسنة لتسريع الاتصال بين وحدات معالجة الرسومات، مما أدى إلى زمن وصول أقل وإنتاجية أعلى للنماذج الكبيرة جدًا بالنسبة لوحدة معالجة رسومات واحدة. تتوفر هذه المجموعات حصريًا لـ SageMaker، لمثيلات p4d.
في حين أن التكرار السابق يدعم فقط التجزئة عبر جميع وحدات معالجة الرسوميات الثمانية، يقدم LMI 8 دعمًا لدرجة موتر متوازية تبلغ 0.26.0، في نمط جزئي شامل. يمكن دمج هذا مع مكونات الاستدلال SageMaker، والتي يمكنك من خلالها تكوين عدد المسرعات التي يجب تخصيصها لكل نموذج يتم نشره خلف نقطة النهاية. توفر هذه الميزات معًا تحكمًا أفضل في استخدام الموارد للمثيل الأساسي، مما يتيح لك زيادة الإيجار المتعدد للنموذج من خلال استضافة نماذج مختلفة خلف نقطة نهاية واحدة، أو ضبط الإنتاجية الإجمالية للنشر الخاص بك لتتناسب مع خصائص النموذج وحركة المرور.
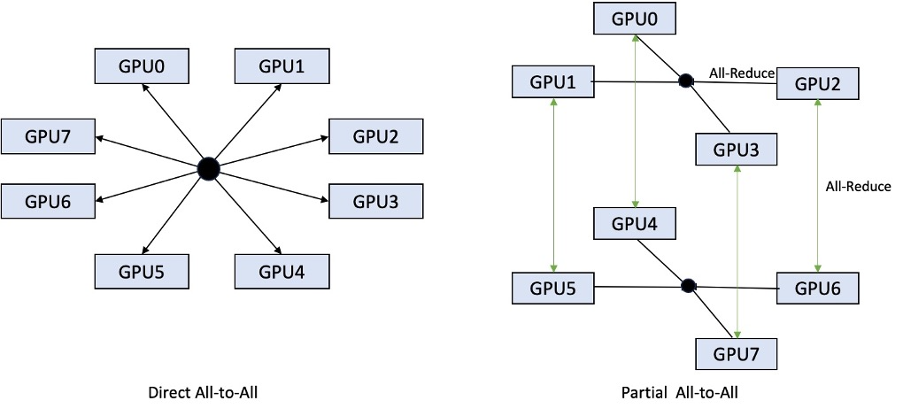
يقارن الشكل التالي الكل إلى الكل المباشر مع الكل إلى الكل الجزئي.
الواجهة الخلفية لـ TensorRT-LLM
تم تقديم TensorRT-LLM من NVIDIA كجزء من إصدار LMI DLC السابق (0.25.0)، مما يتيح أداء وتحسينات GPU المتطورة مثل SmoothQuant وFP8 والدفع المستمر لـ LLMs عند استخدام وحدات معالجة الرسومات NVIDIA.
يتطلب TensorRT-LLM تجميع النماذج في محركات فعالة قبل النشر. يمكن لـ LMI TensorRT-LLM DLC التعامل تلقائيًا مع تجميع قائمة النماذج المدعومة في الوقت المناسب (JIT)، قبل بدء تشغيل الخادم وتحميل النموذج للاستدلال في الوقت الفعلي. يعمل الإصدار 0.26.0 من المحتوى القابل للتنزيل (DLC) على زيادة قائمة النماذج المدعومة لتجميع JIT، حيث يقدم نماذج Baichuan وChatGLM وGPT2 وGPT-J وInternLM وMistral وMixtral وQwen وSantaCoder وStarCoder.
يضيف تجميع JIT عدة دقائق من الحمل الزائد لتوفير نقطة النهاية وقياس الوقت، لذلك يوصى دائمًا بتجميع النموذج الخاص بك مسبقًا. للحصول على دليل حول كيفية القيام بذلك وقائمة النماذج المدعومة، راجع TensorRT-LLM تجميع مسبق للنماذج التعليمية. إذا لم يكن الطراز الذي اخترته مدعومًا بعد، فارجع إلى برنامج TensorRT-LLM للتجميع اليدوي للنماذج التعليمية لتجميع أي نموذج آخر يدعمه TensorRT-LLM.
بالإضافة إلى ذلك، يعرض LMI الآن التكميم الأصلي لـ TensorRT-LLM SmootQuant، مع معلمات للتحكم في ألفا وعامل القياس حسب الرمز المميز أو القناة. لمزيد من المعلومات حول التكوينات ذات الصلة، راجع TensorRT-LLM.
الواجهة الخلفية vLLM
يتميز الإصدار المحدث من vLLM المتضمن في LMI DLC بتحسينات في الأداء تصل إلى 50% مدعومة بوضع الرسم البياني CUDA بدلاً من الوضع المتحمس. تعمل الرسوم البيانية CUDA على تسريع أعباء عمل وحدة معالجة الرسومات من خلال إطلاق العديد من عمليات وحدة معالجة الرسومات دفعة واحدة بدلاً من تشغيلها بشكل فردي، مما يقلل من النفقات العامة. وهذا فعال بشكل خاص للنماذج الصغيرة عند استخدام التوازي الموتر.
يأتي الأداء الإضافي بمقايضة استهلاك ذاكرة GPU المضافة. أصبح وضع الرسم البياني CUDA هو الوضع الافتراضي الآن لواجهة vLLM الخلفية، لذلك إذا كنت مقيدًا بحجم ذاكرة GPU المتاحة، فيمكنك تعيينه option.enforce_eager=True لإجبار وضع PyTorch المتلهف.
المحولات-NeuronX الخلفية
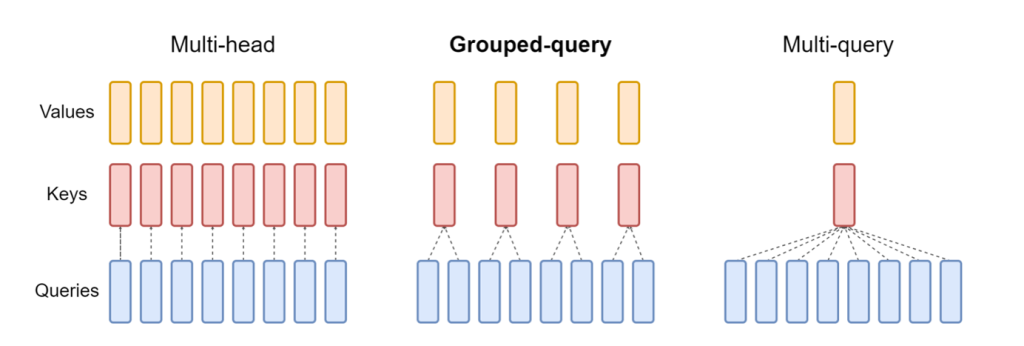
الإصدار المحدث من نيورونكس المضمن في LMI NeuronX DLC يدعم الآن النماذج التي تتميز بآلية انتباه الاستعلام المجمع، مثل Mistral-7B وLLama2-70B. يعد الاهتمام بالاستعلام المجمع بمثابة تحسين مهم لآلية انتباه المحول الافتراضية، حيث يتم تدريب النموذج باستخدام عدد أقل من رؤوس المفاتيح والقيم مقارنة برؤوس الاستعلام. يؤدي هذا إلى تقليل حجم ذاكرة التخزين المؤقت KV على ذاكرة وحدة معالجة الرسومات، مما يسمح بتزامن أكبر وتحسين أداء السعر.
يوضح الشكل التالي طرق الاهتمام متعددة الرؤوس والاستعلام المجمع والاستعلام المتعدد (مصدر).
تتوفر استراتيجيات مختلفة لتقسيم ذاكرة التخزين المؤقت لـ KV لتناسب أنواعًا مختلفة من أعباء العمل. لمزيد من المعلومات حول استراتيجيات التقسيم، راجع دعم الاهتمام بالاستعلام المجمع (GQA).. يمكنك تمكين الاستراتيجية التي تريدها (shard-over-headsعلى سبيل المثال) بالكود التالي:
بالإضافة إلى ذلك، يقدم التنفيذ الجديد لـ NeuronX DLC واجهة برمجة تطبيقات ذاكرة التخزين المؤقت لـ TransformerNeuronX التي تتيح الوصول إلى ذاكرة التخزين المؤقت KV. يسمح لك بإدراج وإزالة صفوف ذاكرة التخزين المؤقت KV من الطلبات الجديدة أثناء قيامك بتسليم الاستدلال المجمع. قبل تقديم واجهة برمجة التطبيقات هذه، تمت إعادة حساب ذاكرة التخزين المؤقت KV لأية طلبات مضافة حديثًا. بالمقارنة مع LMI V7 (0.25.0)، قمنا بتحسين زمن الاستجابة بأكثر من 33% مع الطلبات المتزامنة، ودعم إنتاجية أعلى بكثير.
اختيار الخلفية الصحيحة
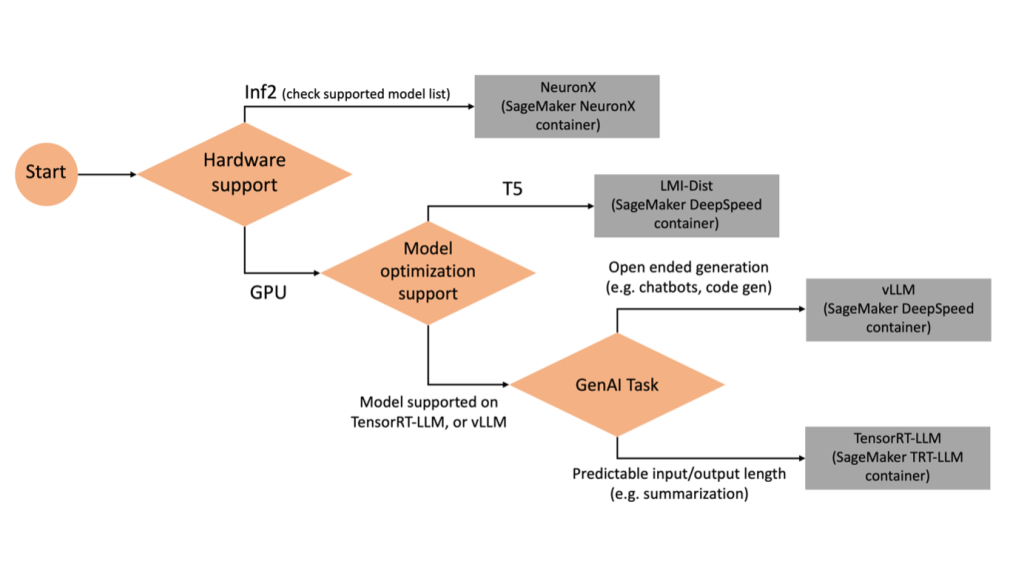
لتحديد الواجهة الخلفية التي سيتم استخدامها بناءً على النموذج والمهمة المحددة، استخدم المخطط الانسيابي التالي. للحصول على أدلة مستخدم الواجهة الخلفية الفردية بالإضافة إلى النماذج المدعومة، راجع أدلة مستخدم الواجهة الخلفية LMI.
انشر Mixtral مع LMI DLC بسمات إضافية
دعنا نتعرف على كيفية نشر نموذج Mixtral-8x7B مع حاوية LMI 0.26.0 وإنشاء تفاصيل إضافية مثل log_prob و finish_reason كجزء من الإخراج. نناقش أيضًا كيف يمكنك الاستفادة من هذه السمات الإضافية من خلال حالة استخدام إنشاء المحتوى.
دفتر الملاحظات الكامل مع التعليمات التفصيلية متاح في جيثب ريبو.
نبدأ باستيراد المكتبات وتكوين بيئة الجلسة:
يمكنك استخدام حاويات SageMaker LMI لاستضافة النماذج دون أي رمز استدلال إضافي. يمكنك تكوين الخادم النموذجي إما من خلال متغيرات البيئة أو serving.properties ملف. بشكل اختياري، يمكن أن يكون لديك model.py ملف لأي معالجة مسبقة أو معالجة لاحقة و requirements.txt ملف لأي حزم إضافية مطلوب تثبيتها.
في هذه الحالة نستخدم serving.properties ملف لتكوين المعلمات وتخصيص سلوك حاوية LMI. لمزيد من التفاصيل، راجع جيثب ريبو. يشرح الريبو تفاصيل معلمات التكوين المختلفة التي يمكنك تعيينها. نحن بحاجة إلى المعلمات الرئيسية التالية:
- محرك - يحدد محرك وقت التشغيل الذي سيستخدمه DJL. يؤدي هذا إلى تشغيل استراتيجية التجزئة وتحميل النموذج في مسرعات النموذج.
- option.model_id – يحدد خدمة تخزين أمازون البسيطة (Amazon S3) URI للنموذج المُدرب مسبقًا أو معرف النموذج للنموذج المُدرب مسبقًا والمستضاف داخل مستودع النماذج على وجه يعانق. في هذه الحالة، نقدم معرف النموذج لنموذج Mixtral-8x7B.
- option.tensor_parallel_degree - يضبط عدد أجهزة GPU التي يحتاج Accelerate إلى تقسيم النموذج عليها. تتحكم هذه المعلمة أيضًا في عدد العاملين لكل نموذج والذي سيتم تشغيله عند تشغيل خدمة DJL. لقد وضعنا هذه القيمة على
max(الحد الأقصى لوحدة معالجة الرسومات على الجهاز الحالي). - option.rolling_batch - تمكين الخلط المستمر لتحسين استخدام المسرع والإنتاجية الإجمالية. بالنسبة لحاوية TensorRT-LLM، نستخدمها
auto. - option.model_loading_timeout - يضبط قيمة المهلة لتنزيل النموذج وتحميله لتقديم الاستدلال.
- option.max_rolling_batch - يضبط الحد الأقصى لحجم الدفعة المستمرة، ويحدد عدد التسلسلات التي يمكن معالجتها بالتوازي في أي وقت محدد.
نحن نحزم serving.properties ملف التكوين بتنسيق tar.gz، بحيث يلبي متطلبات استضافة SageMaker. نقوم بتكوين حاوية DJL LMI باستخدام tensorrtllm كمحرك الخلفية. بالإضافة إلى ذلك، نحدد الإصدار الأحدث من الحاوية (0.26.0).
بعد ذلك، نقوم بتحميل ملف القطران المحلي (الذي يحتوي على ملف serving.properties ملف التكوين) إلى بادئة S3. نحن نستخدم URI للصورة لحاوية DJL وموقع Amazon S3 الذي تم تحميل النموذج الذي يقدم عناصر tarball إليه، لإنشاء كائن نموذج SageMaker.
كجزء من LMI 0.26.0، يمكنك الآن استخدام تفصيلين إضافيين دقيقين حول المخرجات التي تم إنشاؤها:
- log_probs - هذا هو احتمال السجل الذي يعينه النموذج لكل رمز مميز في مقطع التسلسل المتدفق. يمكنك استخدام هذه كتقدير تقريبي لثقة النموذج عن طريق حساب الاحتمال المشترك للتسلسل كمجموع احتمالات السجل للرموز المميزة الفردية، والتي يمكن أن تكون مفيدة لتسجيل النتائج وتصنيف مخرجات النموذج. ضع في اعتبارك أن احتمالات رمز LLM تكون مفرطة الثقة بشكل عام دون معايرة.
- Finish_reason – هذا هو سبب اكتمال الإنشاء، والذي يمكن أن يصل إلى الحد الأقصى لطول الإنشاء، أو إنشاء رمز EOS المميز، أو إنشاء رمز توقف محدد من قبل المستخدم. يتم إرجاع هذا مع آخر قطعة تسلسل متدفقة.
يمكنك تمكين هذه عن طريق المرور "details"=True كجزء من مدخلاتك للنموذج.
دعونا نرى كيف يمكنك إنشاء هذه التفاصيل. نحن نستخدم مثالًا لإنشاء المحتوى لفهم تطبيقها.
نحدد أ LineIterator helper، التي لديها وظائف لجلب البايتات من تدفق الاستجابة بتكاسل، وتخزينها مؤقتًا، وتقسيم المخزن المؤقت إلى أسطر. تتمثل الفكرة في تقديم البايتات من المخزن المؤقت أثناء جلب المزيد من البايتات من الدفق بشكل غير متزامن.
قم بإنشاء واستخدام احتمالية الرمز المميز كتفاصيل إضافية
فكر في حالة استخدام حيث نقوم بإنشاء المحتوى. على وجه التحديد، نحن مكلفون بكتابة فقرة مختصرة حول فوائد ممارسة الرياضة بانتظام لموقع ويب يركز على نمط الحياة. نريد إنشاء محتوى وإخراج بعض النقاط الإرشادية للثقة التي يتمتع بها النموذج في المحتوى الذي تم إنشاؤه.
نحن نستدعي نقطة النهاية النموذجية من خلال موجهنا ونلتقط الاستجابة التي تم إنشاؤها. وضعنا "details": True كمعلمة وقت التشغيل ضمن المدخلات إلى النموذج. نظرًا لأنه يتم إنشاء احتمالية السجل لكل رمز مميز للإخراج، فإننا نلحق احتمالات السجل الفردية بالقائمة. نقوم أيضًا بالتقاط النص الكامل الذي تم إنشاؤه من الرد.
لحساب درجة الثقة الإجمالية، نحسب متوسط جميع احتمالات الرمز المميز الفردية ثم نحصل بعد ذلك على القيمة الأسية بين 0 و1. هذه هي درجة الثقة الإجمالية المستنتجة للنص الذي تم إنشاؤه، والذي هو في هذه الحالة فقرة حول الفوائد من ممارسة التمارين الرياضية بانتظام.

كان هذا أحد الأمثلة على كيفية إنشاء واستخدام log_prob، في سياق حالة استخدام إنشاء المحتوى. وبالمثل، يمكنك استخدام log_prob كمقياس لدرجة الثقة لحالات استخدام التصنيف.
وبدلاً من ذلك، يمكنك استخدامه لتسلسل الإخراج الإجمالي أو التسجيل على مستوى الجملة لتقييم تأثير المعلمات مثل درجة الحرارة على الإخراج الذي تم إنشاؤه.
قم بإنشاء واستخدام سبب النهاية كتفاصيل إضافية
دعونا نبني على نفس حالة الاستخدام، ولكن هذه المرة نحن مكلفون بكتابة مقالة أطول. بالإضافة إلى ذلك، نريد التأكد من عدم اقتطاع الإخراج بسبب مشكلات طول الإنشاء (الحد الأقصى لطول الرمز المميز) أو بسبب مواجهة رموز التوقف المميزة.
ولتحقيق ذلك نستخدم finish_reason السمة التي تم إنشاؤها في المخرجات، ومراقبة قيمتها، ومواصلة الإنشاء حتى يتم إنشاء المخرجات بأكملها.
نحن نحدد وظيفة الاستدلال التي تأخذ مدخلات الحمولة وتستدعي نقطة نهاية SageMaker، وتقوم بتدفق الاستجابة مرة أخرى، وتعالج الاستجابة لاستخراج النص الذي تم إنشاؤه. تحتوي الحمولة على نص المطالبة كمدخلات ومعلمات مثل الحد الأقصى من الرموز المميزة والتفاصيل. تتم قراءة الاستجابة في دفق ومعالجتها سطرًا تلو الآخر لاستخراج الرموز النصية التي تم إنشاؤها في القائمة. نستخرج التفاصيل مثل finish_reason. نحن نستدعي وظيفة الاستدلال في حلقة (الطلبات المتسلسلة) مع إضافة المزيد من السياق في كل مرة، وتتبع عدد الرموز المميزة التي تم إنشاؤها وعدد الطلبات المرسلة حتى انتهاء النموذج.
كما نرى، على الرغم من max_new_token تم تعيين المعلمة على 256، ونحن نستخدم سمة تفاصيل Finish_reason كجزء من الإخراج لسلسلة طلبات متعددة إلى نقطة النهاية، حتى يتم إنشاء الإخراج بأكمله.
وبالمثل، بناءً على حالة الاستخدام الخاصة بك، يمكنك استخدام stop_reason لاكتشاف عدم كفاية طول تسلسل الإخراج المحدد لمهمة معينة أو الإكمال غير المقصود بسبب تسلسل التوقف البشري.
وفي الختام
في هذا المنشور، تناولنا الإصدار v0.26.0 من حاوية AWS LMI. لقد سلطنا الضوء على تحسينات الأداء الرئيسية ودعم الطراز الجديد وميزات سهولة الاستخدام الجديدة. باستخدام هذه الإمكانات، يمكنك تحقيق توازن أفضل بين خصائص التكلفة والأداء مع توفير تجربة أفضل للمستخدمين النهائيين.
لمعرفة المزيد حول إمكانيات LMI DLC، راجع التوازي النموذجي واستدلال النموذج الكبير. يسعدنا أن نرى كيف تستخدم هذه الإمكانات الجديدة من SageMaker.
عن المؤلفين
 جواو مورا هو أحد كبار مهندسي الحلول المتخصصة في الذكاء الاصطناعي/تعلم الآلة في AWS. يساعد João عملاء AWS - من الشركات الناشئة الصغيرة إلى المؤسسات الكبيرة - على تدريب النماذج الكبيرة ونشرها بكفاءة، وبناء منصات تعلم الآلة على AWS على نطاق أوسع.
جواو مورا هو أحد كبار مهندسي الحلول المتخصصة في الذكاء الاصطناعي/تعلم الآلة في AWS. يساعد João عملاء AWS - من الشركات الناشئة الصغيرة إلى المؤسسات الكبيرة - على تدريب النماذج الكبيرة ونشرها بكفاءة، وبناء منصات تعلم الآلة على AWS على نطاق أوسع.
 راهول شارما هو أحد كبار مهندسي الحلول في AWS، حيث يساعد عملاء AWS على تصميم وبناء حلول الذكاء الاصطناعي/تعلم الآلة. قبل انضمامه إلى AWS، أمضى راهول عدة سنوات في قطاع التمويل والتأمين، حيث ساعد العملاء على بناء منصات البيانات والتحليلات.
راهول شارما هو أحد كبار مهندسي الحلول في AWS، حيث يساعد عملاء AWS على تصميم وبناء حلول الذكاء الاصطناعي/تعلم الآلة. قبل انضمامه إلى AWS، أمضى راهول عدة سنوات في قطاع التمويل والتأمين، حيث ساعد العملاء على بناء منصات البيانات والتحليلات.
 تشينغ لان هو مهندس تطوير برمجيات في AWS. لقد كان يعمل على العديد من المنتجات الصعبة في Amazon ، بما في ذلك حلول استدلال ML عالية الأداء ونظام تسجيل عالي الأداء. أطلق فريق Qing بنجاح أول نموذج مليار معلمة في إعلانات أمازون بزمن انتقال منخفض للغاية مطلوب. تتمتع Qing بمعرفة متعمقة حول تحسين البنية التحتية وتسريع التعلم العميق.
تشينغ لان هو مهندس تطوير برمجيات في AWS. لقد كان يعمل على العديد من المنتجات الصعبة في Amazon ، بما في ذلك حلول استدلال ML عالية الأداء ونظام تسجيل عالي الأداء. أطلق فريق Qing بنجاح أول نموذج مليار معلمة في إعلانات أمازون بزمن انتقال منخفض للغاية مطلوب. تتمتع Qing بمعرفة متعمقة حول تحسين البنية التحتية وتسريع التعلم العميق.
 جيان شنغ هو مهندس تطوير برمجيات في Amazon Web Services وقد عمل على العديد من الجوانب الرئيسية لأنظمة التعلم الآلي. لقد كان مساهمًا رئيسيًا في خدمة SageMaker Neo، مع التركيز على تجميع التعلم العميق وتحسين وقت تشغيل الإطار. قام مؤخرًا بتوجيه جهوده وساهم في تحسين نظام التعلم الآلي لاستدلال النماذج الكبيرة.
جيان شنغ هو مهندس تطوير برمجيات في Amazon Web Services وقد عمل على العديد من الجوانب الرئيسية لأنظمة التعلم الآلي. لقد كان مساهمًا رئيسيًا في خدمة SageMaker Neo، مع التركيز على تجميع التعلم العميق وتحسين وقت تشغيل الإطار. قام مؤخرًا بتوجيه جهوده وساهم في تحسين نظام التعلم الآلي لاستدلال النماذج الكبيرة.
 تايلر أوستربيرج هو مهندس تطوير البرمجيات في AWS. وهو متخصص في صياغة تجارب استدلال التعلم الآلي عالية الأداء داخل SageMaker. وفي الآونة الأخيرة، انصب تركيزه على تحسين أداء حاويات Inferentia Deep Learning Containers على منصة SageMaker. يتفوق تايلر في تنفيذ حلول الاستضافة عالية الأداء لنماذج اللغات الكبيرة وتعزيز تجارب المستخدم باستخدام التكنولوجيا المتطورة.
تايلر أوستربيرج هو مهندس تطوير البرمجيات في AWS. وهو متخصص في صياغة تجارب استدلال التعلم الآلي عالية الأداء داخل SageMaker. وفي الآونة الأخيرة، انصب تركيزه على تحسين أداء حاويات Inferentia Deep Learning Containers على منصة SageMaker. يتفوق تايلر في تنفيذ حلول الاستضافة عالية الأداء لنماذج اللغات الكبيرة وتعزيز تجارب المستخدم باستخدام التكنولوجيا المتطورة.
 روبيندر جريوال هو أحد كبار مهندسي الحلول المتخصصة في الذكاء الاصطناعي/تعلم الآلة لدى AWS. وهو يركز حاليًا على تقديم النماذج وعمليات MLOps على Amazon SageMaker. قبل هذا الدور، عمل مهندسًا للتعلم الآلي في بناء واستضافة النماذج. وخارج العمل، يستمتع بلعب التنس وركوب الدراجات على الطرق الجبلية.
روبيندر جريوال هو أحد كبار مهندسي الحلول المتخصصة في الذكاء الاصطناعي/تعلم الآلة لدى AWS. وهو يركز حاليًا على تقديم النماذج وعمليات MLOps على Amazon SageMaker. قبل هذا الدور، عمل مهندسًا للتعلم الآلي في بناء واستضافة النماذج. وخارج العمل، يستمتع بلعب التنس وركوب الدراجات على الطرق الجبلية.
 ضوال باتل هو مهندس رئيسي لتعلم الآلة في AWS. لقد عمل مع مؤسسات تتراوح من المؤسسات الكبيرة إلى الشركات الناشئة متوسطة الحجم في المشكلات المتعلقة بالحوسبة الموزعة والذكاء الاصطناعي. يركز على التعلم العميق بما في ذلك مجالات البرمجة اللغوية العصبية ورؤية الكمبيوتر. إنه يساعد العملاء على تحقيق استدلال نموذج عالي الأداء على SageMaker.
ضوال باتل هو مهندس رئيسي لتعلم الآلة في AWS. لقد عمل مع مؤسسات تتراوح من المؤسسات الكبيرة إلى الشركات الناشئة متوسطة الحجم في المشكلات المتعلقة بالحوسبة الموزعة والذكاء الاصطناعي. يركز على التعلم العميق بما في ذلك مجالات البرمجة اللغوية العصبية ورؤية الكمبيوتر. إنه يساعد العملاء على تحقيق استدلال نموذج عالي الأداء على SageMaker.
 راغو راميشا هو أحد كبار مهندسي حلول ML مع فريق خدمة Amazon SageMaker. وهو يركز على مساعدة العملاء في إنشاء أعباء عمل إنتاج تعلم الآلة ونشرها وترحيلها إلى SageMaker على نطاق واسع. وهو متخصص في مجالات التعلم الآلي والذكاء الاصطناعي ورؤية الكمبيوتر، ويحمل درجة الماجستير في علوم الكمبيوتر من جامعة تكساس في دالاس. وفي أوقات فراغه، يستمتع بالسفر والتصوير الفوتوغرافي.
راغو راميشا هو أحد كبار مهندسي حلول ML مع فريق خدمة Amazon SageMaker. وهو يركز على مساعدة العملاء في إنشاء أعباء عمل إنتاج تعلم الآلة ونشرها وترحيلها إلى SageMaker على نطاق واسع. وهو متخصص في مجالات التعلم الآلي والذكاء الاصطناعي ورؤية الكمبيوتر، ويحمل درجة الماجستير في علوم الكمبيوتر من جامعة تكساس في دالاس. وفي أوقات فراغه، يستمتع بالسفر والتصوير الفوتوغرافي.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/boost-inference-performance-for-mixtral-and-llama-2-models-with-new-amazon-sagemaker-containers/

