اليوم، العملاء من جميع الصناعات - سواء كانت الخدمات المالية، والرعاية الصحية وعلوم الحياة، والسفر والضيافة، والإعلام والترفيه، والاتصالات، والبرمجيات كخدمة (SaaS)، وحتى موفري النماذج الاحتكارية - يستخدمون نماذج لغوية كبيرة (LLMs) إنشاء تطبيقات مثل روبوتات الدردشة للأسئلة والإجابة (QnA) ومحركات البحث وقواعد المعرفة. هؤلاء الذكاء الاصطناعي التوليدي لا تُستخدم التطبيقات لأتمتة العمليات التجارية الحالية فحسب، بل تتمتع أيضًا بالقدرة على تحويل تجربة العملاء الذين يستخدمون هذه التطبيقات. مع التقدم الذي تم إحرازه مع LLMs مثل تعليمات Mixtral-8x7B، مشتق من البنى مثل خليط من الخبراء (وزارة التربية والتعليم)، يبحث العملاء باستمرار عن طرق لتحسين أداء ودقة تطبيقات الذكاء الاصطناعي التوليدية مع السماح لهم بالاستخدام الفعال لمجموعة واسعة من النماذج المغلقة والمفتوحة المصدر.
عادةً ما يتم استخدام عدد من التقنيات لتحسين دقة وأداء مخرجات LLM، مثل الضبط الدقيق باستخدام الضبط الدقيق الفعال للمعلمة (PEFT), التعلم المعزز من التغذية الراجعة البشرية (RLHF)، والأداء تقطير المعرفة. ومع ذلك، عند إنشاء تطبيقات ذكاء اصطناعي توليدية، يمكنك استخدام حل بديل يسمح بالدمج الديناميكي للمعرفة الخارجية ويسمح لك بالتحكم في المعلومات المستخدمة للإنشاء دون الحاجة إلى ضبط النموذج الأساسي الحالي لديك. هذا هو المكان الذي يأتي فيه الجيل المعزز للاسترجاع (RAG)، خصيصًا لتطبيقات الذكاء الاصطناعي التوليدية بدلاً من بدائل الضبط الدقيق الأكثر تكلفة والأقوى التي ناقشناها. إذا كنت تقوم بتنفيذ تطبيقات RAG المعقدة في مهامك اليومية، فقد تواجه تحديات مشتركة مع أنظمة RAG الخاصة بك مثل الاسترجاع غير الدقيق، وزيادة حجم المستندات وتعقيدها، وتجاوز السياق، مما قد يؤثر بشكل كبير على جودة وموثوقية الإجابات التي تم إنشاؤها .
يناقش هذا المنشور أنماط RAG لتحسين دقة الاستجابة باستخدام LangChain وأدوات مثل مسترد المستندات الأصلي بالإضافة إلى تقنيات مثل الضغط السياقي لتمكين المطورين من تحسين تطبيقات الذكاء الاصطناعي التوليدية الحالية.
حل نظرة عامة
في هذا المنشور، نوضح استخدام إنشاء النص Mixtral-8x7B Instruct جنبًا إلى جنب مع نموذج التضمين BGE Large En لإنشاء نظام RAG QnA بكفاءة على كمبيوتر دفتري Amazon SageMaker باستخدام أداة استرداد المستندات الأصلية وتقنية الضغط السياقي. ويوضح الرسم البياني التالي بنية هذا الحل.
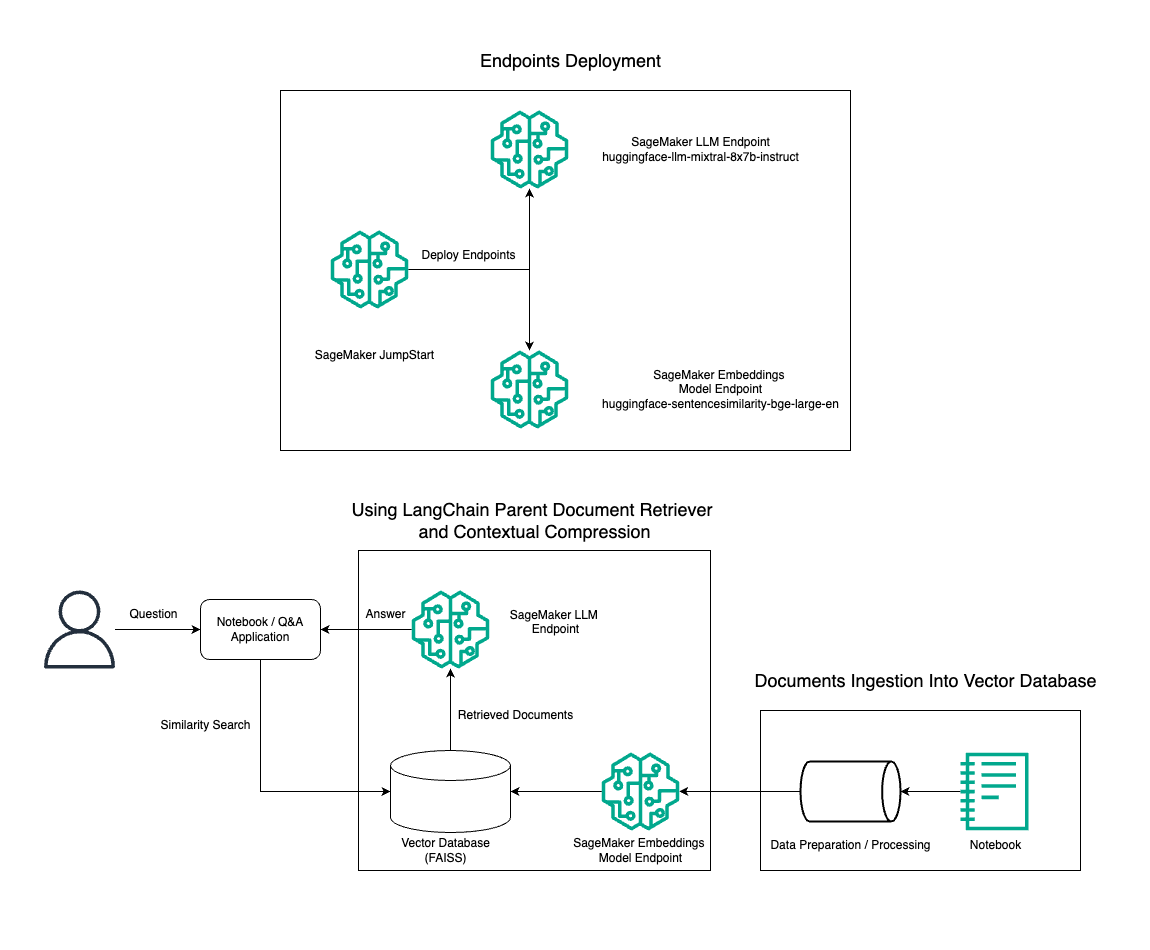
يمكنك نشر هذا الحل ببضع نقرات فقط باستخدام أمازون سيج ميكر جومب ستارت، منصة مُدارة بالكامل تقدم نماذج أساسية حديثة لحالات الاستخدام المختلفة مثل كتابة المحتوى وإنشاء التعليمات البرمجية والإجابة على الأسئلة وكتابة الإعلانات والتلخيص والتصنيف واسترجاع المعلومات. فهو يوفر مجموعة من النماذج المدربة مسبقًا والتي يمكنك نشرها بسرعة وسهولة، مما يؤدي إلى تسريع عملية تطوير ونشر تطبيقات التعلم الآلي (ML). أحد المكونات الرئيسية لـ SageMaker JumpStart هو Model Hub، الذي يقدم كتالوجًا كبيرًا من النماذج المدربة مسبقًا، مثل Mixtral-8x7B، لمجموعة متنوعة من المهام.
يستخدم Mixtral-8x7B بنية MoE. تسمح هذه البنية لأجزاء مختلفة من الشبكة العصبية بالتخصص في مهام مختلفة، وتقسيم عبء العمل بشكل فعال بين العديد من الخبراء. يتيح هذا النهج التدريب الفعال ونشر نماذج أكبر مقارنة بالبنى التقليدية.
إحدى المزايا الرئيسية لبنية وزارة التربية والتعليم هي قابليتها للتوسع. ومن خلال توزيع عبء العمل على خبراء متعددين، يمكن تدريب نماذج وزارة التربية والتعليم على مجموعات بيانات أكبر وتحقيق أداء أفضل من النماذج التقليدية ذات الحجم نفسه. بالإضافة إلى ذلك، يمكن أن تكون نماذج وزارة التربية والتعليم أكثر كفاءة أثناء الاستدلال لأنه لا يلزم تنشيط سوى مجموعة فرعية من الخبراء لمدخلات معينة.
لمزيد من المعلومات حول تعليمات Mixtral-8x7B حول AWS، راجع Mixtral-8x7B متوفر الآن في Amazon SageMaker JumpStart. تم توفير نموذج Mixtral-8x7B بموجب ترخيص Apache 2.0 المسموح به للاستخدام دون قيود.
في هذه التدوينة نناقش كيف يمكنك استخدامها لانجشين لإنشاء تطبيقات RAG فعالة وأكثر كفاءة. LangChain هي مكتبة Python مفتوحة المصدر مصممة لبناء التطبيقات باستخدام LLMs. فهو يوفر إطارًا معياريًا ومرنًا للجمع بين LLMs والمكونات الأخرى، مثل قواعد المعرفة وأنظمة الاسترجاع وأدوات الذكاء الاصطناعي الأخرى، لإنشاء تطبيقات قوية وقابلة للتخصيص.
نسير عبر إنشاء خط أنابيب RAG على SageMaker باستخدام Mixtral-8x7B. نحن نستخدم نموذج إنشاء النص Mixtral-8x7B Instruct مع نموذج التضمين BGE Large En لإنشاء نظام QnA فعال باستخدام RAG على دفتر ملاحظات SageMaker. نحن نستخدم مثيل ml.t3.medium لتوضيح نشر LLMs عبر SageMaker JumpStart، والذي يمكن الوصول إليه من خلال نقطة نهاية واجهة برمجة التطبيقات (API) التي تم إنشاؤها بواسطة SageMaker. يسمح هذا الإعداد باستكشاف تقنيات RAG المتقدمة وتجريبها وتحسينها باستخدام LangChain. نوضح أيضًا دمج مخزن FAISS Embedding في سير عمل RAG، مع تسليط الضوء على دوره في تخزين واسترجاع التضمينات لتحسين أداء النظام.
نقوم بإجراء جولة مختصرة حول دفتر ملاحظات SageMaker. للحصول على تعليمات أكثر تفصيلاً وخطوة بخطوة، راجع أنماط RAG المتقدمة مع Mixtral على SageMaker Jumpstart GitHub repo.
الحاجة إلى أنماط RAG المتقدمة
تعد أنماط RAG المتقدمة ضرورية لتحسين القدرات الحالية لـ LLMs في معالجة وفهم وإنشاء نص يشبه الإنسان. مع زيادة حجم المستندات وتعقيدها، فإن تمثيل جوانب متعددة من المستند في تضمين واحد يمكن أن يؤدي إلى فقدان الخصوصية. على الرغم من أنه من الضروري فهم الجوهر العام للمستند، إلا أنه من المهم أيضًا التعرف على السياقات الفرعية المتنوعة وتمثيلها بداخلها. هذا هو التحدي الذي تواجهه غالبًا عند العمل مع مستندات أكبر حجمًا. التحدي الآخر الذي تواجهه RAG هو أنه عند الاسترجاع، لن تكون على دراية بالاستعلامات المحددة التي سيتعامل معها نظام تخزين المستندات الخاص بك عند الاستيعاب. قد يؤدي هذا إلى دفن المعلومات الأكثر صلة بالاستعلام تحت النص (تجاوز السياق). للتخفيف من الفشل وتحسين بنية RAG الحالية، يمكنك استخدام أنماط RAG المتقدمة (استرداد المستندات الأصلية والضغط السياقي) لتقليل أخطاء الاسترجاع وتحسين جودة الإجابة وتمكين معالجة الأسئلة المعقدة.
باستخدام التقنيات التي تمت مناقشتها في هذا المنشور، يمكنك معالجة التحديات الرئيسية المرتبطة باسترجاع المعرفة الخارجية وتكاملها، مما يمكّن تطبيقك من تقديم استجابات أكثر دقة ووعيًا بالسياق.
في الأقسام التالية، نستكشف كيف أدوات استرداد المستندات الأصلية و ضغط السياق يمكن أن تساعدك في التعامل مع بعض المشاكل التي ناقشناها.
برنامج استرداد المستندات الأصلية
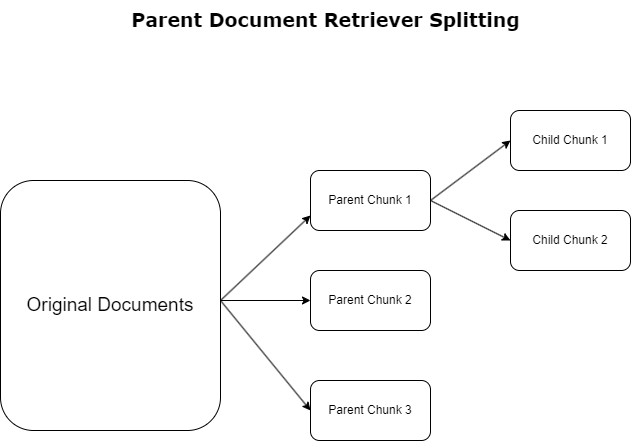
في القسم السابق، سلطنا الضوء على التحديات التي تواجهها تطبيقات RAG عند التعامل مع المستندات الشاملة. ولمواجهة هذه التحديات، أدوات استرداد المستندات الأصلية تصنيف وتعيين الوثائق الواردة كما وثائق الوالدين. يتم التعرف على هذه المستندات لطبيعتها الشاملة ولكن لا يتم استخدامها بشكل مباشر في شكلها الأصلي للتضمين. بدلاً من ضغط المستند بأكمله في تضمين واحد، تقوم برامج استرداد المستندات الأصلية بتشريح هذه المستندات الأصلية وثائق الطفل. يلتقط كل مستند فرعي جوانب أو موضوعات مميزة من المستند الأصلي الأوسع. بعد تحديد هذه الأجزاء الفرعية، يتم تعيين التضمينات الفردية لكل منها، مع التقاط جوهرها الموضوعي المحدد (انظر الرسم البياني التالي). أثناء الاسترجاع، يتم استدعاء المستند الأصلي. توفر هذه التقنية قدرات بحث مستهدفة وواسعة النطاق، مما يوفر للماجستير في القانون منظورًا أوسع. توفر أدوات استرداد المستندات الأصلية لـ LLM ميزة ذات شقين: خصوصية تضمين المستندات الفرعية لاسترجاع المعلومات الدقيقة وذات الصلة، إلى جانب استدعاء المستندات الأصلية لتوليد الاستجابة، مما يثري مخرجات LLM بسياق متعدد الطبقات وشامل.
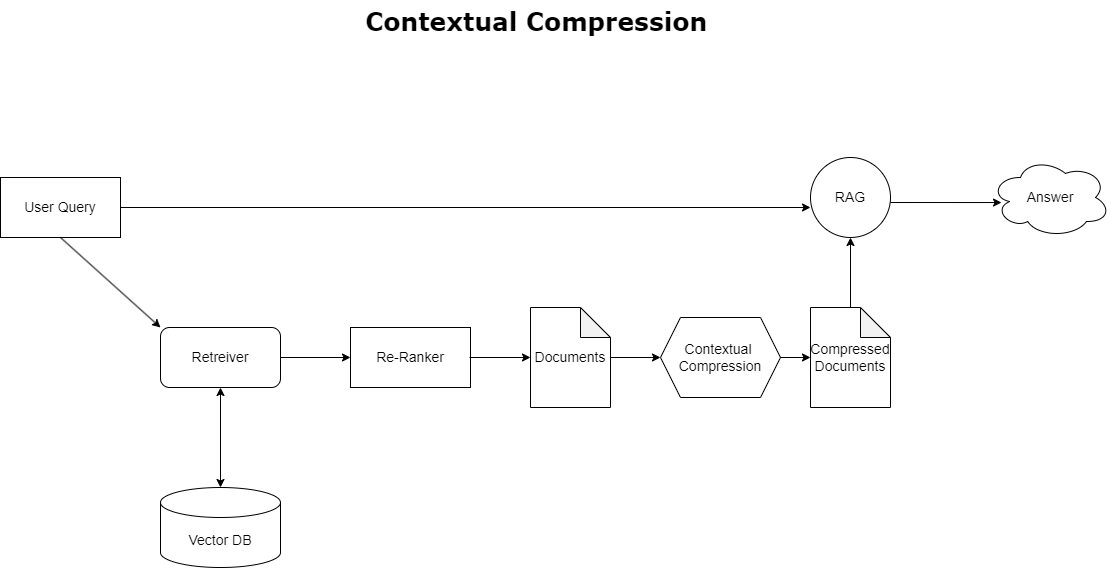
ضغط السياق
لمعالجة مشكلة تجاوز السياق التي تمت مناقشتها سابقًا، يمكنك استخدام ضغط السياق لضغط المستندات المستردة وتصفيتها بما يتماشى مع سياق الاستعلام، بحيث يتم الاحتفاظ بالمعلومات ذات الصلة فقط ومعالجتها. ويتم تحقيق ذلك من خلال مجموعة من المسترد الأساسي للجلب الأولي للمستندات وضاغط المستندات لتحسين هذه المستندات عن طريق تقليص محتواها أو استبعادها بالكامل بناءً على مدى ملاءمتها، كما هو موضح في الرسم البياني التالي. يعمل هذا النهج المبسط، الذي يسهله مسترد الضغط السياقي، على تحسين كفاءة تطبيق RAG بشكل كبير من خلال توفير طريقة لاستخراج واستخدام ما هو ضروري فقط من كتلة من المعلومات. فهو يعالج مشكلة الحمل الزائد للمعلومات ومعالجة البيانات غير ذات الصلة بشكل مباشر، مما يؤدي إلى تحسين جودة الاستجابة، وعمليات LLM أكثر فعالية من حيث التكلفة، وعملية استرجاع شاملة أكثر سلاسة. في الأساس، إنه مرشح يقوم بتخصيص المعلومات وفقًا للاستعلام المطروح، مما يجعله أداة مطلوبة بشدة للمطورين الذين يهدفون إلى تحسين تطبيقات RAG الخاصة بهم للحصول على أداء أفضل ورضا المستخدم.
المتطلبات الأساسية المسبقة
إذا كنت جديدًا في SageMaker، فارجع إلى دليل تطوير Amazon SageMaker.
قبل أن تبدأ بالحل، إنشاء حساب AWS. عند إنشاء حساب AWS، تحصل على هوية تسجيل الدخول الموحد (SSO) التي تتمتع بإمكانية الوصول الكامل إلى جميع خدمات وموارد AWS الموجودة في الحساب. تسمى هذه الهوية حساب AWS مستخدم الجذر.
تسجيل الدخول إلى وحدة تحكم إدارة AWS يمنحك استخدام عنوان البريد الإلكتروني وكلمة المرور اللذين استخدمتهما لإنشاء الحساب إمكانية الوصول الكامل إلى جميع موارد AWS الموجودة في حسابك. نوصي بشدة بعدم استخدام المستخدم الجذر في المهام اليومية، حتى تلك الإدارية.
بدلا من ذلك، الالتزام أفضل الممارسات الأمنية in إدارة الهوية والوصول AWS (أنا و إنشاء مستخدم إداري ومجموعة. ثم قم بقفل بيانات اعتماد المستخدم الجذر بشكل آمن واستخدمها لأداء عدد قليل فقط من مهام إدارة الحساب والخدمة.
يتطلب نموذج Mixtral-8x7b مثيل ml.g5.48xlarge. يوفر SageMaker JumpStart طريقة مبسطة للوصول إلى أكثر من 100 نموذج أساسي مختلف مفتوح المصدر والجهات الخارجية ونشرها. بغرض إطلاق نقطة نهاية لاستضافة Mixtral-8x7B من SageMaker JumpStart، قد تحتاج إلى طلب زيادة حصة الخدمة للوصول إلى مثيل ml.g5.48xlarge لاستخدام نقطة النهاية. أنت تستطيع زيادة حصة خدمة الطلب من خلال وحدة التحكم، واجهة سطر الأوامر AWS (AWS CLI)، أو API للسماح بالوصول إلى تلك الموارد الإضافية.
قم بإعداد مثيل دفتر ملاحظات SageMaker وتثبيت التبعيات
للبدء، قم بإنشاء مثيل دفتر ملاحظات SageMaker وقم بتثبيت التبعيات المطلوبة. الرجوع إلى جيثب ريبو لضمان الإعداد الناجح. بعد إعداد مثيل دفتر الملاحظات، يمكنك نشر النموذج.
يمكنك أيضًا تشغيل الكمبيوتر الدفتري محليًا على بيئة التطوير المتكاملة (IDE) المفضلة لديك. تأكد من تثبيت Jupyter Notebook Lab.
انشر النموذج
انشر نموذج Mixtral-8X7B Instruct LLM على SageMaker JumpStart:
انشر نموذج التضمين BGE Large En على SageMaker JumpStart:
قم بإعداد LangChain
بعد استيراد جميع المكتبات الضرورية ونشر نموذج Mixtral-8x7B ونموذج تضمينات BGE Large En، يمكنك الآن إعداد LangChain. للحصول على تعليمات خطوة بخطوة، راجع جيثب ريبو.
إعداد البيانات
في هذا المنشور، نستخدم عدة سنوات من خطابات أمازون للمساهمين كمجموعة نصية لتنفيذ QnA. لمزيد من الخطوات التفصيلية لإعداد البيانات، راجع جيثب ريبو.
الإجابة على السؤال
بمجرد إعداد البيانات، يمكنك استخدام الغلاف الذي توفره LangChain، والذي يلتف حول مخزن المتجهات ويأخذ مدخلات لـ LLM. يقوم هذا المجمع بالخطوات التالية:
- خذ سؤال الإدخال.
- إنشاء تضمين السؤال.
- إحضار المستندات ذات الصلة.
- دمج المستندات والسؤال في موجه.
- قم باستدعاء النموذج باستخدام الموجه وقم بإنشاء الإجابة بطريقة قابلة للقراءة.
الآن بعد أن أصبح متجر المتجهات جاهزًا، يمكنك البدء في طرح الأسئلة:
سلسلة المسترد العادية
في السيناريو السابق، اكتشفنا الطريقة السريعة والمباشرة للحصول على إجابة تراعي السياق لسؤالك. الآن دعونا نلقي نظرة على خيار أكثر قابلية للتخصيص بمساعدة RetrievalQA، حيث يمكنك تخصيص كيفية إضافة المستندات التي تم جلبها إلى الموجه باستخدام المعلمة chain_type. أيضًا، من أجل التحكم في عدد المستندات ذات الصلة التي يجب استرجاعها، يمكنك تغيير المعلمة k في الكود التالي لرؤية مخرجات مختلفة. في العديد من السيناريوهات، قد ترغب في معرفة المستندات المصدر التي استخدمتها LLM لإنشاء الإجابة. يمكنك الحصول على تلك المستندات في الإخراج باستخدام return_source_documents، الذي يقوم بإرجاع المستندات التي تمت إضافتها إلى سياق موجه LLM. يتيح لك RetrievalQA أيضًا توفير قالب مطالبة مخصص يمكن أن يكون خاصًا بالنموذج.
دعونا نسأل سؤالا:
سلسلة استرداد المستندات الأصلية
دعونا نلقي نظرة على خيار RAG الأكثر تقدمًا بمساعدة ParentDocumentRetriever. عند العمل مع استرداد المستندات، قد تواجه مفاضلة بين تخزين أجزاء صغيرة من المستند للتضمين الدقيق والمستندات الأكبر حجمًا للحفاظ على المزيد من السياق. يحقق مسترد المستندات الأصلي هذا التوازن عن طريق تقسيم وتخزين أجزاء صغيرة من البيانات.
نحن نستخدم parent_splitter لتقسيم المستندات الأصلية إلى أجزاء أكبر تسمى المستندات الأصلية و child_splitter لإنشاء مستندات فرعية أصغر من المستندات الأصلية:
تتم بعد ذلك فهرسة المستندات الفرعية في مخزن متجه باستخدام التضمينات. يتيح ذلك استرجاعًا فعالاً لمستندات الأطفال ذات الصلة بناءً على التشابه. لاسترداد المعلومات ذات الصلة، يقوم مسترد المستند الأصلي أولاً بجلب المستندات الفرعية من مخزن المتجهات. ثم يبحث بعد ذلك عن المعرفات الأصلية لتلك المستندات الفرعية ويقوم بإرجاع المستندات الأصلية الأكبر حجمًا المقابلة.
دعونا نسأل سؤالا:
سلسلة الضغط السياقية
دعونا نلقي نظرة على خيار RAG متقدم آخر يسمى ضغط السياق. أحد تحديات الاسترجاع هو أننا عادة لا نعرف الاستعلامات المحددة التي سيواجهها نظام تخزين المستندات الخاص بك عند إدخال البيانات في النظام. وهذا يعني أن المعلومات الأكثر صلة بالاستعلام قد تكون مخفية في مستند يحتوي على الكثير من النصوص غير ذات الصلة. يمكن أن يؤدي تمرير هذا المستند الكامل من خلال طلبك إلى مكالمات LLM أكثر تكلفة واستجابات أقل.
يعالج مسترد الضغط السياقي التحدي المتمثل في استرداد المعلومات ذات الصلة من نظام تخزين المستندات، حيث قد يتم دفن البيانات ذات الصلة داخل المستندات التي تحتوي على الكثير من النصوص. ومن خلال ضغط المستندات المستردة وتصفيتها استنادًا إلى سياق الاستعلام المحدد، يتم إرجاع المعلومات الأكثر صلة فقط.
لاستخدام استرداد الضغط السياقي، ستحتاج إلى:
- مسترد قاعدة – هذا هو المسترد الأولي الذي يقوم بجلب المستندات من نظام التخزين بناءً على الاستعلام
- ضاغط المستندات - يأخذ هذا المكون المستندات المستردة في البداية ويختصرها عن طريق تقليل محتويات المستندات الفردية أو إسقاط المستندات غير ذات الصلة تمامًا، وذلك باستخدام سياق الاستعلام لتحديد مدى ملاءمتها
إضافة ضغط سياقي باستخدام مستخرج سلسلة LLM
أولاً، قم بلف المسترد الأساسي الخاص بك بـ ContextualCompressionRetriever. سوف تقوم بإضافة LLMChainExtractor، والذي سيتكرر على المستندات التي تم إرجاعها في البداية ويستخرج من كل منها فقط المحتوى ذي الصلة بالاستعلام.
تهيئة السلسلة باستخدام ContextualCompressionRetriever مع LLMChainExtractor وتمرير المطالبة عبر chain_type_kwargs جدال.
دعونا نسأل سؤالا:
قم بتصفية المستندات باستخدام مرشح سلسلة LLM
• LLMChainFilter هو ضاغط أبسط قليلاً ولكنه أكثر قوة يستخدم سلسلة LLM لتحديد أي من المستندات المستردة في البداية سيتم تصفيتها وأي منها سيتم إرجاعه، دون معالجة محتويات المستند:
تهيئة السلسلة باستخدام ContextualCompressionRetriever مع LLMChainFilter وتمرير المطالبة عبر chain_type_kwargs جدال.
دعونا نسأل سؤالا:
قارن النتائج
يقارن الجدول التالي النتائج من استعلامات مختلفة بناءً على التقنية.
| تقنية | استعلام 1 | استعلام 2 | مقارنة |
| كيف تطورت AWS؟ | لماذا تنجح أمازون؟ | ||
| إخراج سلسلة المسترد العادية | تطورت AWS (Amazon Web Services) من استثمار غير مربح في البداية إلى شركة ذات إيرادات سنوية تبلغ 85 مليار دولار مع ربحية قوية، وتقدم مجموعة واسعة من الخدمات والميزات، وأصبحت جزءًا مهمًا من محفظة أمازون. على الرغم من مواجهة الشكوك والرياح المعاكسة قصيرة المدى، واصلت AWS الابتكار وجذب عملاء جدد وترحيل العملاء النشطين، حيث قدمت فوائد مثل المرونة والابتكار وفعالية التكلفة والأمان. قامت AWS أيضًا بتوسيع استثماراتها طويلة المدى، بما في ذلك تطوير الرقائق، لتوفير إمكانات جديدة وتغيير ما هو ممكن لعملائها. | تعتبر أمازون ناجحة بسبب ابتكارها المستمر وتوسعها في مجالات جديدة مثل خدمات البنية التحتية التكنولوجية، وأجهزة القراءة الرقمية، والمساعدين الشخصيين الذين يعملون بالصوت، ونماذج الأعمال الجديدة مثل سوق الطرف الثالث. إن قدرتها على توسيع نطاق العمليات بسرعة، كما يظهر في التوسع السريع لشبكات النقل والتنفيذ، تساهم أيضًا في نجاحها. بالإضافة إلى ذلك، أدى تركيز أمازون على التحسين ومكاسب الكفاءة في عملياتها إلى تحسين الإنتاجية وخفض التكاليف. ويسلط مثال أمازون بيزنس الضوء على قدرة الشركة على الاستفادة من نقاط قوتها في التجارة الإلكترونية والخدمات اللوجستية في مختلف القطاعات. | بناءً على الردود الواردة من سلسلة المستردات العادية، نلاحظ أنه على الرغم من أنها تقدم إجابات طويلة، إلا أنها تعاني من تجاوز السياق وتفشل في ذكر أي تفاصيل مهمة من المجموعة فيما يتعلق بالرد على الاستعلام المقدم. إن سلسلة الاسترجاع المنتظمة غير قادرة على التقاط الفروق الدقيقة بعمق أو رؤية سياقية، مما قد يؤدي إلى فقدان الجوانب الهامة من الوثيقة. |
| إخراج مسترد المستندات الأصلية | بدأت AWS (Amazon Web Services) بإطلاق أولي ضعيف الميزات لخدمة Elastic Compute Cloud (EC2) في عام 2006، مما يوفر حجم مثيل واحد فقط، في مركز بيانات واحد، في منطقة واحدة من العالم، مع مثيلات نظام التشغيل Linux فقط ، وبدون العديد من الميزات الرئيسية مثل المراقبة أو موازنة التحميل أو القياس التلقائي أو التخزين المستمر. ومع ذلك، سمح لهم نجاح AWS بتكرار القدرات المفقودة وإضافتها بسرعة، والتوسع في النهاية لتقديم نكهات وأحجام وتحسينات مختلفة للحوسبة والتخزين والشبكات، بالإضافة إلى تطوير شرائحهم الخاصة (Graviton) لرفع السعر والأداء بشكل أكبر. . تطلبت عملية الابتكار التكراري لشركة AWS استثمارات كبيرة في الموارد المالية والبشرية على مدار 20 عامًا، وغالبًا ما يكون ذلك قبل الموعد المحدد للدفع بوقت طويل، وذلك لتلبية احتياجات العملاء وتحسين تجارب العملاء على المدى الطويل والولاء والعوائد للمساهمين. | ويعود نجاح أمازون إلى قدرتها على الابتكار المستمر والتكيف مع ظروف السوق المتغيرة وتلبية احتياجات العملاء في مختلف قطاعات السوق. ويتجلى هذا في نجاح Amazon Business، التي نمت لتحقق ما يقرب من 35 مليار دولار من إجمالي المبيعات السنوية من خلال تقديم الاختيار والقيمة والراحة لعملاء الأعمال. كما مكنت استثمارات أمازون في التجارة الإلكترونية والقدرات اللوجستية من إنشاء خدمات مثل الشراء باستخدام Prime، والتي تساعد التجار الذين لديهم مواقع ويب مباشرة للمستهلك على دفع التحويل من المشاهدات إلى عمليات الشراء. | يتعمق مسترد المستندات الأصلية بشكل أعمق في تفاصيل استراتيجية نمو AWS، بما في ذلك العملية التكرارية لإضافة ميزات جديدة بناءً على تعليقات العملاء والرحلة التفصيلية من الإطلاق الأولي الذي يفتقر إلى الميزات إلى وضع مهيمن في السوق، مع توفير استجابة غنية بالسياق . تغطي الإجابات مجموعة واسعة من الجوانب، بدءًا من الابتكارات التقنية واستراتيجية السوق وحتى الكفاءة التنظيمية والتركيز على العملاء، مما يوفر رؤية شاملة للعوامل التي تساهم في النجاح إلى جانب الأمثلة. يمكن أن يعزى ذلك إلى إمكانات البحث المستهدفة والواسعة النطاق لمسترد المستندات الأصلية. |
| مستخرج سلسلة LLM: إخراج الضغط السياقي | تطورت AWS من خلال البدء كمشروع صغير داخل أمازون، الأمر الذي يتطلب استثمارًا رأسماليًا كبيرًا ومواجهة الشكوك من داخل الشركة وخارجها. ومع ذلك، كان لدى AWS السبق في مواجهة المنافسين المحتملين، وكانت تؤمن بالقيمة التي يمكن أن تقدمها للعملاء وأمازون. التزمت AWS على المدى الطويل بمواصلة الاستثمار، مما أدى إلى إطلاق أكثر من 3,300 ميزة وخدمة جديدة في عام 2022. وقد أحدثت AWS تحولًا في كيفية إدارة العملاء للبنية التحتية التكنولوجية الخاصة بهم وأصبحت شركة يبلغ معدل إيراداتها السنوية 85 مليار دولار مع ربحية قوية. قامت AWS أيضًا بتحسين عروضها بشكل مستمر، مثل تعزيز EC2 بميزات وخدمات إضافية بعد إطلاقها الأولي. | واستنادًا إلى السياق المقدم، يمكن أن يُعزى نجاح أمازون إلى توسعها الاستراتيجي من منصة لبيع الكتب إلى سوق عالمية ذات نظام بيئي نابض بالحياة لبائعي الطرف الثالث، والاستثمار المبكر في AWS، والابتكار في تقديم Kindle وAlexa، والنمو الكبير. في الإيرادات السنوية من 2019 إلى 2022. وأدى هذا النمو إلى توسيع نطاق مركز التنفيذ، وإنشاء شبكة نقل الميل الأخير، وبناء شبكة جديدة لمراكز الفرز، والتي تم تحسينها لتحقيق الإنتاجية وخفض التكلفة. | يحافظ مستخرج سلسلة LLM على التوازن بين تغطية النقاط الرئيسية بشكل شامل وتجنب العمق غير الضروري. فهو يتكيف ديناميكيًا مع سياق الاستعلام، بحيث تكون المخرجات ذات صلة مباشرة وشاملة. |
| مرشح سلسلة LLM: إخراج الضغط السياقي | تطورت AWS (Amazon Web Services) من خلال الإطلاق الأولي للميزات الضعيفة ولكن التكرار بسرعة بناءً على تعليقات العملاء لإضافة الإمكانات الضرورية. سمح هذا النهج لشركة AWS بإطلاق EC2 في عام 2006 بميزات محدودة ثم إضافة وظائف جديدة باستمرار، مثل أحجام المثيلات الإضافية ومراكز البيانات والمناطق وخيارات نظام التشغيل وأدوات المراقبة وموازنة التحميل والقياس التلقائي والتخزين المستمر. بمرور الوقت، تحولت AWS من خدمة سيئة الميزات إلى شركة بمليارات الدولارات من خلال التركيز على احتياجات العملاء، وخفة الحركة، والابتكار، وفعالية التكلفة، والأمان. تتمتع AWS الآن بمعدل إيرادات سنوي يبلغ 85 مليار دولار أمريكي وتقدم أكثر من 3,300 ميزة وخدمة جديدة كل عام، تلبي احتياجات مجموعة واسعة من العملاء بدءًا من الشركات الناشئة وحتى الشركات متعددة الجنسيات ومؤسسات القطاع العام. | تعتبر أمازون ناجحة بسبب نماذج أعمالها المبتكرة، والتقدم التكنولوجي المستمر، والتغييرات التنظيمية الاستراتيجية. لقد أحدثت الشركة باستمرار ثورة في الصناعات التقليدية من خلال تقديم أفكار جديدة، مثل منصة التجارة الإلكترونية لمختلف المنتجات والخدمات، وسوق الطرف الثالث، وخدمات البنية التحتية السحابية (AWS)، وقارئ Kindle الإلكتروني، والمساعد الشخصي Alexa الذي يعمل بالصوت. . بالإضافة إلى ذلك، أجرت أمازون تغييرات هيكلية لتحسين كفاءتها، مثل إعادة تنظيم شبكة التنفيذ الخاصة بها في الولايات المتحدة لتقليل التكاليف ومواعيد التسليم، مما يساهم بشكل أكبر في نجاحها. | على غرار مستخرج سلسلة LLM، يتأكد مرشح سلسلة LLM من أنه على الرغم من تغطية النقاط الرئيسية، إلا أن الإخراج فعال للعملاء الذين يبحثون عن إجابات موجزة وسياقية. |
عند مقارنة هذه التقنيات المختلفة، يمكننا أن نرى أنه في سياقات مثل تفصيل انتقال AWS من خدمة بسيطة إلى كيان معقد بمليارات الدولارات، أو شرح نجاحات أمازون الإستراتيجية، فإن سلسلة الاسترداد العادية تفتقر إلى الدقة التي توفرها التقنيات الأكثر تطورًا. مما يؤدي إلى معلومات أقل استهدافا. على الرغم من وجود اختلافات قليلة جدًا بين التقنيات المتقدمة التي تمت مناقشتها، إلا أنها أكثر إفادة بكثير من سلاسل المستردات العادية.
بالنسبة للعملاء في صناعات مثل الرعاية الصحية والاتصالات والخدمات المالية الذين يتطلعون إلى تطبيق RAG في تطبيقاتهم، فإن القيود المفروضة على سلسلة الاسترجاع العادية في توفير الدقة وتجنب التكرار وضغط المعلومات بشكل فعال تجعلها أقل ملاءمة لتلبية هذه الاحتياجات مقارنة إلى أدوات استرداد المستندات الأصلية الأكثر تقدمًا وتقنيات الضغط السياقية. هذه التقنيات قادرة على استخلاص كميات هائلة من المعلومات وتحويلها إلى رؤى مركزة ومؤثرة تحتاجها، مع المساعدة في تحسين أداء السعر.
تنظيف
عند الانتهاء من تشغيل دفتر الملاحظات، احذف الموارد التي قمت بإنشائها لتجنب تراكم الرسوم على الموارد المستخدمة:
وفي الختام
في هذا المنشور، قدمنا حلاً يسمح لك بتنفيذ استرداد المستندات الأصلية وتقنيات سلسلة الضغط السياقية لتعزيز قدرة LLMs على معالجة المعلومات وإنشاءها. لقد اختبرنا تقنيات RAG المتقدمة هذه باستخدام نماذج Mixtral-8x7B Instruct وBGE Large En المتوفرة مع SageMaker JumpStart. لقد استكشفنا أيضًا استخدام التخزين المستمر للتضمينات وأجزاء المستندات والتكامل مع مخازن بيانات المؤسسة.
لا تعمل التقنيات التي قمنا بها على تحسين الطريقة التي تصل بها نماذج LLM إلى المعرفة الخارجية ودمجها فحسب، بل تعمل أيضًا على تحسين جودة مخرجاتها وملاءمتها وكفاءتها بشكل كبير. من خلال الجمع بين الاسترجاع من مجموعات نصية كبيرة وإمكانيات توليد اللغة، تمكّن تقنيات RAG المتقدمة هذه حاملي شهادة LLM من إنتاج استجابات أكثر واقعية وتماسكًا وملاءمة للسياق، مما يعزز أدائها عبر مهام معالجة اللغة الطبيعية المختلفة.
يقع SageMaker JumpStart في مركز هذا الحل. باستخدام SageMaker JumpStart، يمكنك الوصول إلى مجموعة واسعة من النماذج مفتوحة ومغلقة المصدر، مما يؤدي إلى تبسيط عملية بدء تعلم الآلة وتمكين التجريب والنشر السريع. لبدء نشر هذا الحل، انتقل إلى دفتر الملاحظات في ملف جيثب ريبو.
حول المؤلف
 نيثين فيجياسواران هو مهندس الحلول في AWS. مجال تركيزه هو الذكاء الاصطناعي التوليدي ومسرعات AWS AI. وهو حاصل على درجة البكالوريوس في علوم الكمبيوتر والمعلوماتية الحيوية. تعمل Niithiyn بشكل وثيق مع فريق Geneative AI GTM لتمكين عملاء AWS على جبهات متعددة وتسريع اعتمادهم للذكاء الاصطناعي التوليدي. إنه من أشد المعجبين بفريق دالاس مافريكس ويستمتع بجمع الأحذية الرياضية.
نيثين فيجياسواران هو مهندس الحلول في AWS. مجال تركيزه هو الذكاء الاصطناعي التوليدي ومسرعات AWS AI. وهو حاصل على درجة البكالوريوس في علوم الكمبيوتر والمعلوماتية الحيوية. تعمل Niithiyn بشكل وثيق مع فريق Geneative AI GTM لتمكين عملاء AWS على جبهات متعددة وتسريع اعتمادهم للذكاء الاصطناعي التوليدي. إنه من أشد المعجبين بفريق دالاس مافريكس ويستمتع بجمع الأحذية الرياضية.
 سيباستيان بوستيلو هو مهندس الحلول في AWS. إنه يركز على تقنيات الذكاء الاصطناعي/التعلم الآلي مع شغف عميق بالذكاء الاصطناعي التوليدي ومسرعات الحوسبة. في AWS، يساعد العملاء على إطلاق العنان لقيمة الأعمال من خلال الذكاء الاصطناعي التوليدي. عندما لا يكون في العمل، يستمتع بتحضير كوب مثالي من القهوة المتخصصة واستكشاف العالم مع زوجته.
سيباستيان بوستيلو هو مهندس الحلول في AWS. إنه يركز على تقنيات الذكاء الاصطناعي/التعلم الآلي مع شغف عميق بالذكاء الاصطناعي التوليدي ومسرعات الحوسبة. في AWS، يساعد العملاء على إطلاق العنان لقيمة الأعمال من خلال الذكاء الاصطناعي التوليدي. عندما لا يكون في العمل، يستمتع بتحضير كوب مثالي من القهوة المتخصصة واستكشاف العالم مع زوجته.
 أرماندو دياز هو مهندس الحلول في AWS. وهو يركز على الذكاء الاصطناعي التوليدي والذكاء الاصطناعي/تعلم الآلة وتحليلات البيانات. في AWS، يساعد Armando العملاء على دمج قدرات الذكاء الاصطناعي التوليدية المتطورة في أنظمتهم، وتعزيز الابتكار والميزة التنافسية. عندما لا يكون في العمل، يستمتع بقضاء الوقت مع زوجته وعائلته، والمشي لمسافات طويلة، والسفر حول العالم.
أرماندو دياز هو مهندس الحلول في AWS. وهو يركز على الذكاء الاصطناعي التوليدي والذكاء الاصطناعي/تعلم الآلة وتحليلات البيانات. في AWS، يساعد Armando العملاء على دمج قدرات الذكاء الاصطناعي التوليدية المتطورة في أنظمتهم، وتعزيز الابتكار والميزة التنافسية. عندما لا يكون في العمل، يستمتع بقضاء الوقت مع زوجته وعائلته، والمشي لمسافات طويلة، والسفر حول العالم.
 د.فاروق صابر هو مهندس حلول متخصص في الذكاء الاصطناعي وتعلم الآلة في AWS. وهو حاصل على درجتي الدكتوراه والماجستير في الهندسة الكهربائية من جامعة تكساس في أوستن ودرجة الماجستير في علوم الكمبيوتر من معهد جورجيا للتكنولوجيا. لديه أكثر من 15 عامًا من الخبرة العملية ويحب أيضًا تعليم وإرشاد طلاب الجامعات. في AWS ، يساعد العملاء على صياغة مشاكل أعمالهم وحلها في علوم البيانات والتعلم الآلي ورؤية الكمبيوتر والذكاء الاصطناعي والتحسين العددي والمجالات ذات الصلة. من مقره في دالاس ، تكساس ، يحب هو وعائلته السفر والقيام برحلات طويلة على الطريق.
د.فاروق صابر هو مهندس حلول متخصص في الذكاء الاصطناعي وتعلم الآلة في AWS. وهو حاصل على درجتي الدكتوراه والماجستير في الهندسة الكهربائية من جامعة تكساس في أوستن ودرجة الماجستير في علوم الكمبيوتر من معهد جورجيا للتكنولوجيا. لديه أكثر من 15 عامًا من الخبرة العملية ويحب أيضًا تعليم وإرشاد طلاب الجامعات. في AWS ، يساعد العملاء على صياغة مشاكل أعمالهم وحلها في علوم البيانات والتعلم الآلي ورؤية الكمبيوتر والذكاء الاصطناعي والتحسين العددي والمجالات ذات الصلة. من مقره في دالاس ، تكساس ، يحب هو وعائلته السفر والقيام برحلات طويلة على الطريق.
 ماركو بونيو هو مهندس حلول يركز على استراتيجية الذكاء الاصطناعي التوليدية وحلول الذكاء الاصطناعي التطبيقية وإجراء الأبحاث لمساعدة العملاء على التوسع بشكل كبير في AWS. ماركو هو مستشار سحابي رقمي أصلي يتمتع بخبرة في مجال التكنولوجيا المالية والرعاية الصحية وعلوم الحياة والبرمجيات كخدمة، ومؤخرًا في صناعات الاتصالات. وهو تقني مؤهل ولديه شغف بالتعلم الآلي والذكاء الاصطناعي وعمليات الدمج والاستحواذ. يقيم ماركو في سياتل، واشنطن، ويستمتع بالكتابة والقراءة والتمرين وبناء التطبيقات في أوقات فراغه.
ماركو بونيو هو مهندس حلول يركز على استراتيجية الذكاء الاصطناعي التوليدية وحلول الذكاء الاصطناعي التطبيقية وإجراء الأبحاث لمساعدة العملاء على التوسع بشكل كبير في AWS. ماركو هو مستشار سحابي رقمي أصلي يتمتع بخبرة في مجال التكنولوجيا المالية والرعاية الصحية وعلوم الحياة والبرمجيات كخدمة، ومؤخرًا في صناعات الاتصالات. وهو تقني مؤهل ولديه شغف بالتعلم الآلي والذكاء الاصطناعي وعمليات الدمج والاستحواذ. يقيم ماركو في سياتل، واشنطن، ويستمتع بالكتابة والقراءة والتمرين وبناء التطبيقات في أوقات فراغه.
 أ ج ديمين هو مهندس الحلول في AWS. وهو متخصص في الذكاء الاصطناعي التوليدي والحوسبة بدون خادم وتحليلات البيانات. وهو عضو/مرشد نشط في مجتمع المجال التقني للتعلم الآلي وقد نشر العديد من الأوراق العلمية حول موضوعات مختلفة حول الذكاء الاصطناعي/تعلم الآلة. إنه يعمل مع العملاء، بدءًا من الشركات الناشئة وحتى المؤسسات، لتطوير حلول الذكاء الاصطناعي التوليدية AWSome. وهو متحمس بشكل خاص للاستفادة من نماذج اللغات الكبيرة لتحليلات البيانات المتقدمة واستكشاف التطبيقات العملية التي تعالج تحديات العالم الحقيقي. خارج العمل، يستمتع AJ بالسفر، ويتواجد حاليًا في 53 دولة بهدف زيارة كل دولة في العالم.
أ ج ديمين هو مهندس الحلول في AWS. وهو متخصص في الذكاء الاصطناعي التوليدي والحوسبة بدون خادم وتحليلات البيانات. وهو عضو/مرشد نشط في مجتمع المجال التقني للتعلم الآلي وقد نشر العديد من الأوراق العلمية حول موضوعات مختلفة حول الذكاء الاصطناعي/تعلم الآلة. إنه يعمل مع العملاء، بدءًا من الشركات الناشئة وحتى المؤسسات، لتطوير حلول الذكاء الاصطناعي التوليدية AWSome. وهو متحمس بشكل خاص للاستفادة من نماذج اللغات الكبيرة لتحليلات البيانات المتقدمة واستكشاف التطبيقات العملية التي تعالج تحديات العالم الحقيقي. خارج العمل، يستمتع AJ بالسفر، ويتواجد حاليًا في 53 دولة بهدف زيارة كل دولة في العالم.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/advanced-rag-patterns-on-amazon-sagemaker/

